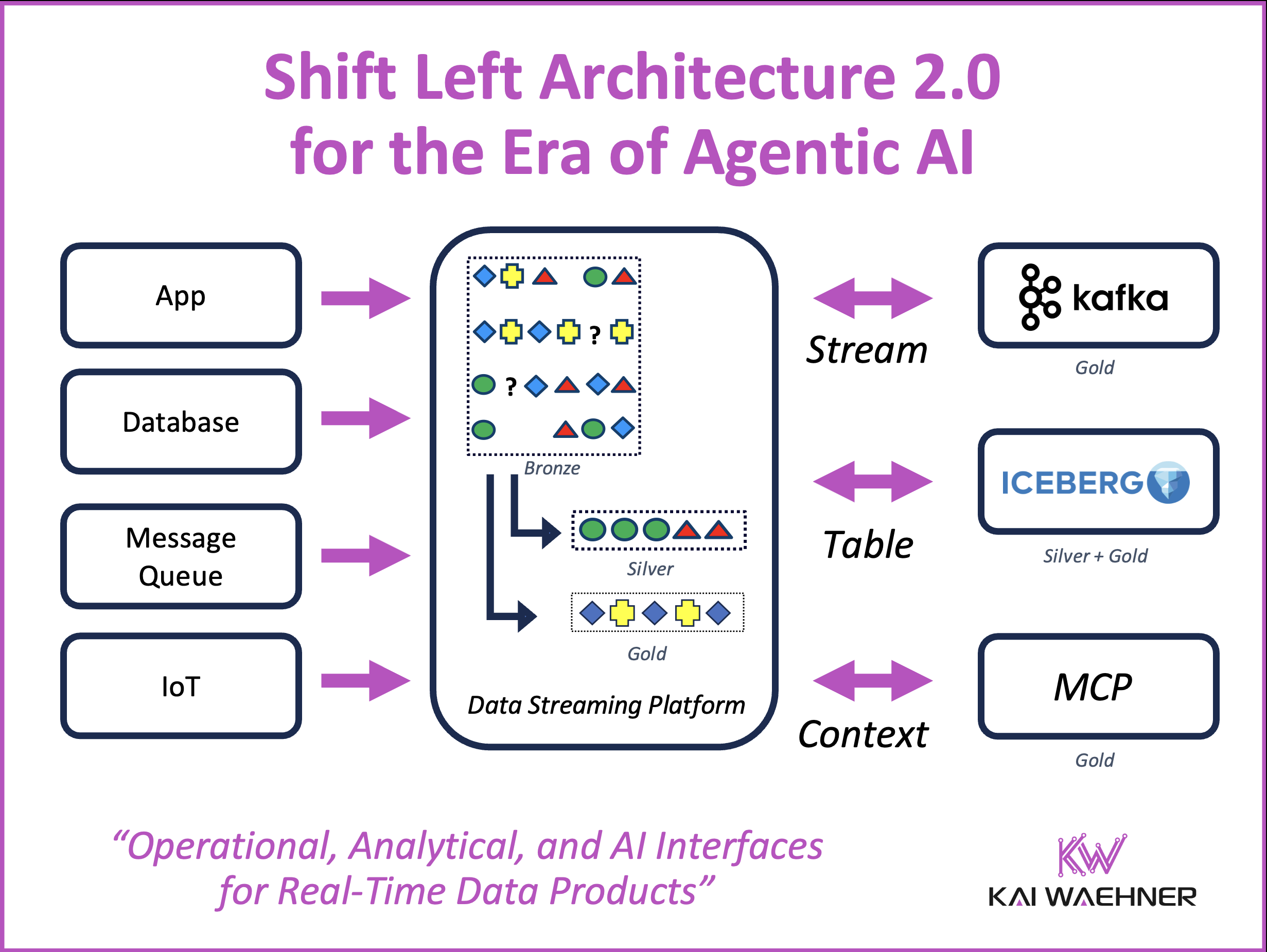
Agentic AI
The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data products are built once and served to multiple consumers. The

The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data products are built once and served to multiple consumers. The

Each year brings new momentum to the data streaming space. In 2026, six key trends stand out. Platforms and vendors are consolidating. Diskless Kafka and
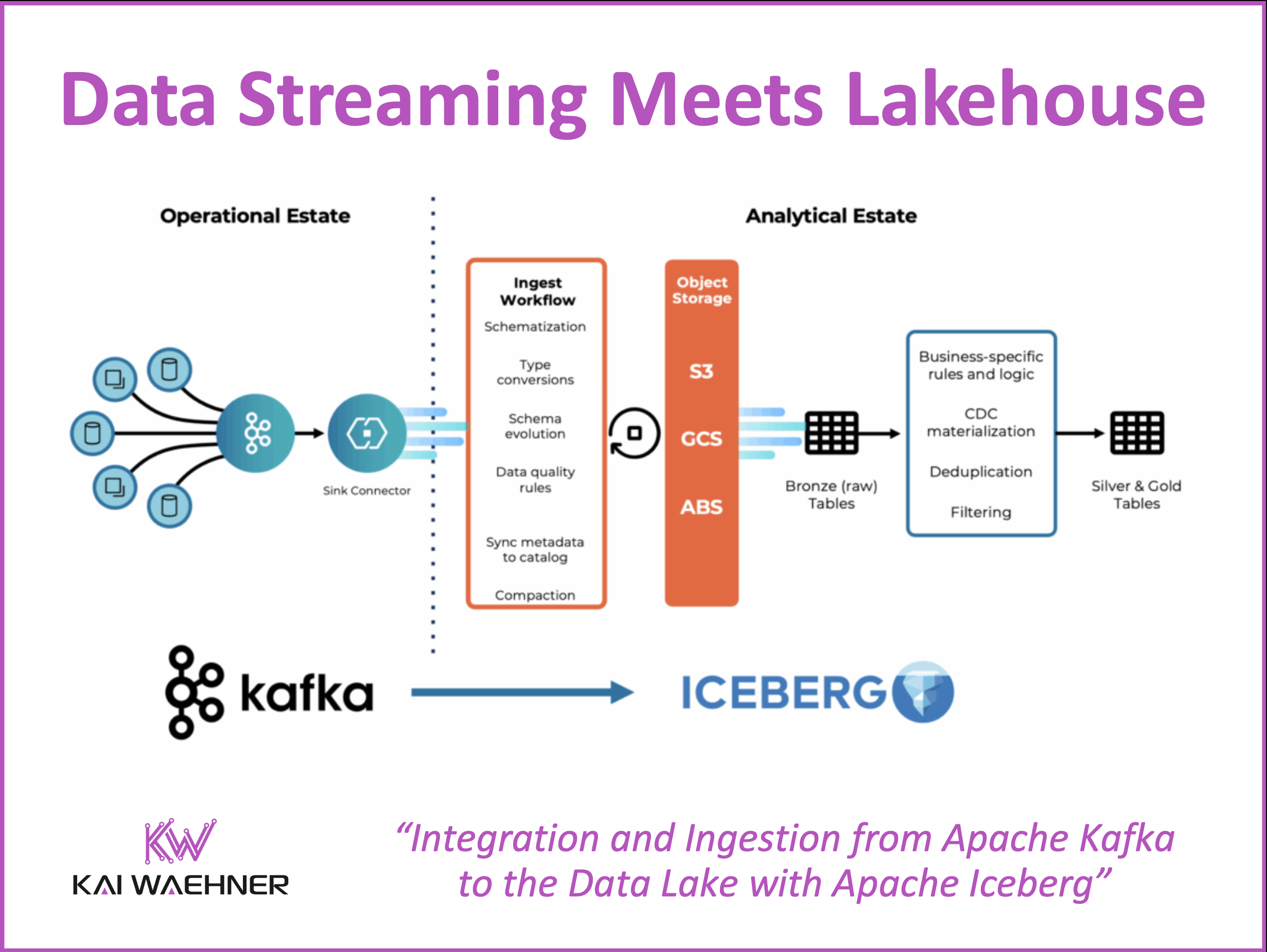
Apache Iceberg is gaining momentum as the open table format of choice for modern data architectures. In this blog post, the key takeaways from my
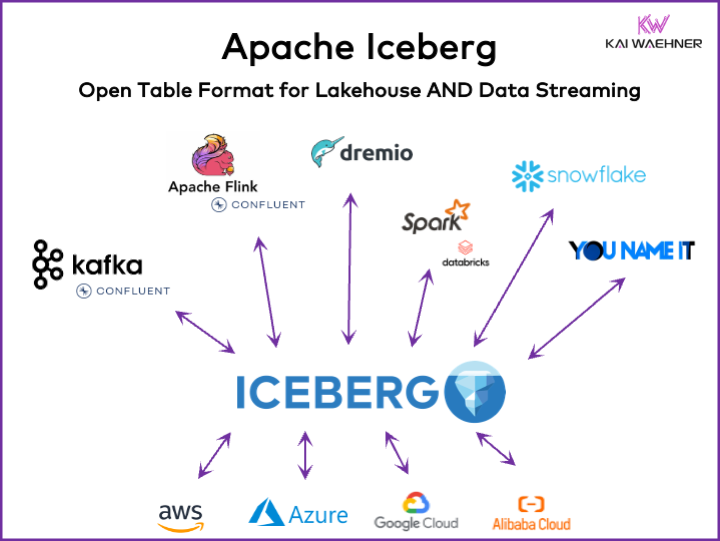
An open table format framework like Apache Iceberg is essential in the enterprise architecture to ensure reliable data management and sharing, seamless schema evolution, efficient
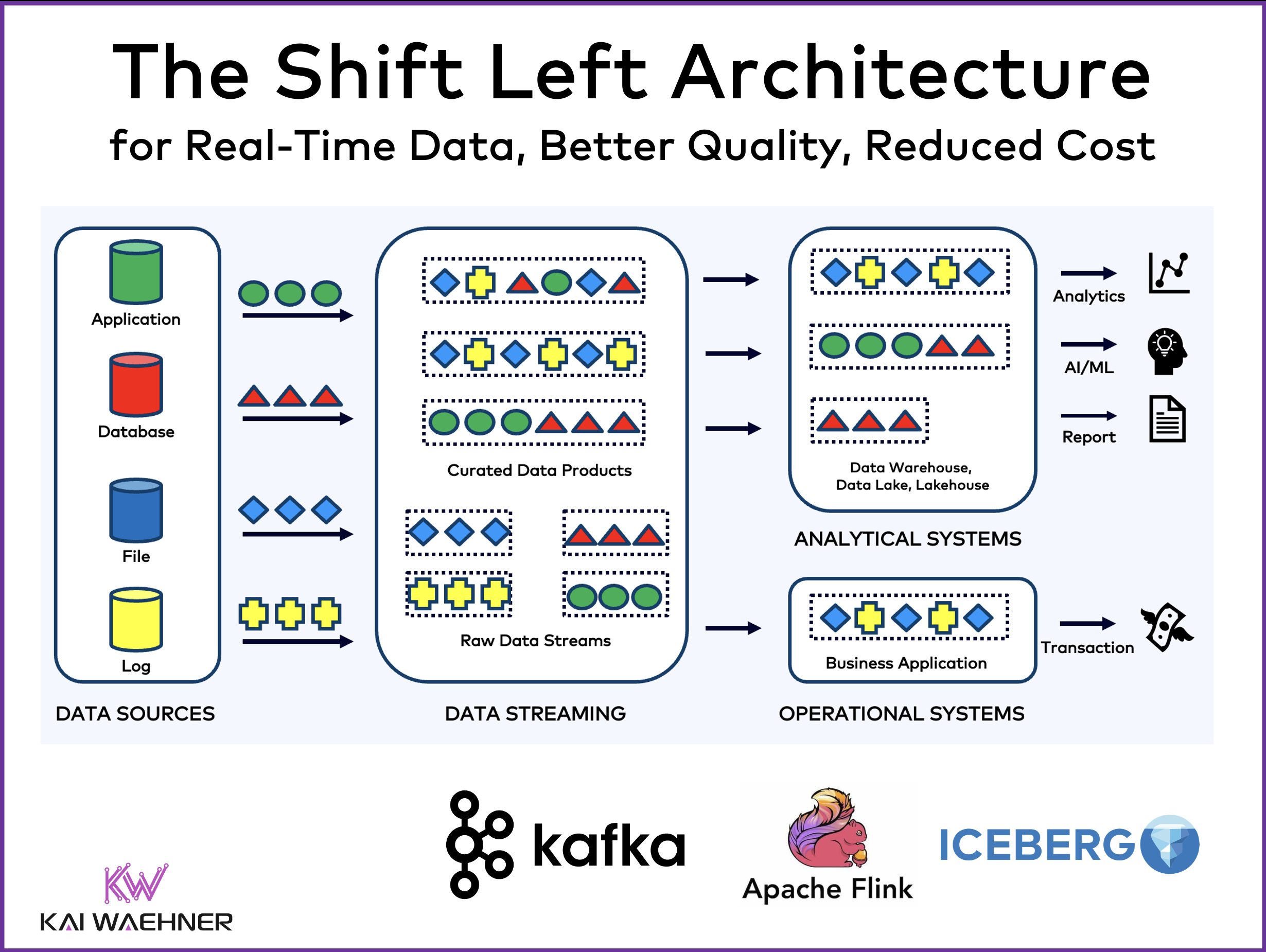
Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.

Snowflake is a leading cloud data warehouse and transitions into a data cloud that enables various use cases. The major drawback of this evolution is
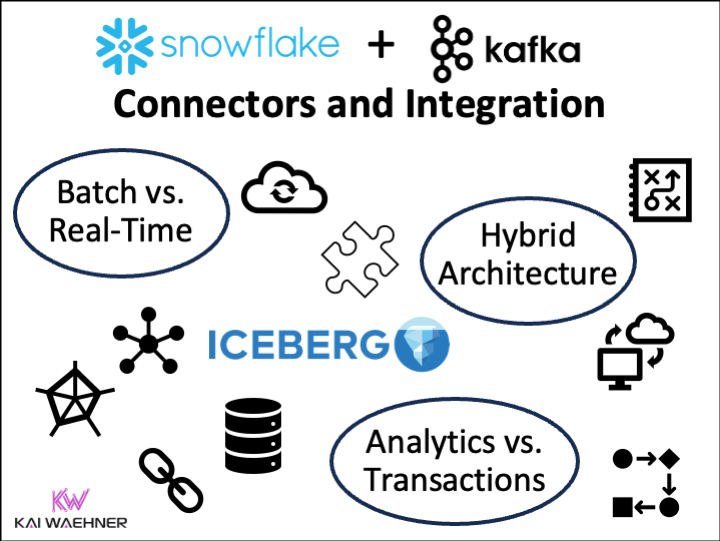
The integration between Apache Kafka and Snowflake is often cumbersome. Options include near real-time ingestion with a Kafka Connect connector, batch ingestion from large files,



You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information