Real-time personalization has become a cornerstone of modern digital experiences. From content recommendations to dynamic user interfaces, delivering relevant interactions at the right moment depends on fresh data and fast machine learning inference. Traditional batch systems can’t keep up—especially when speed, scale, and accuracy are critical.
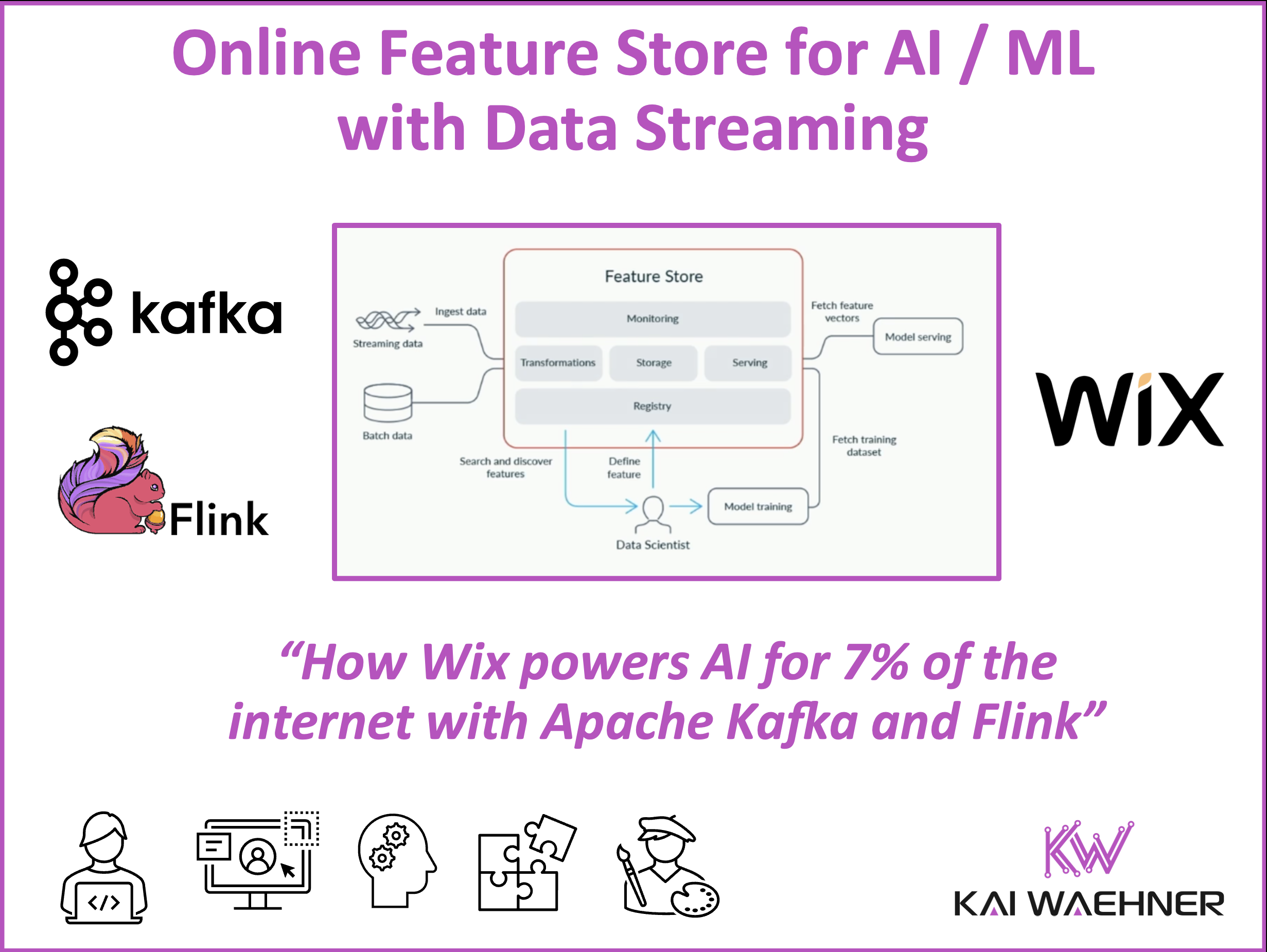
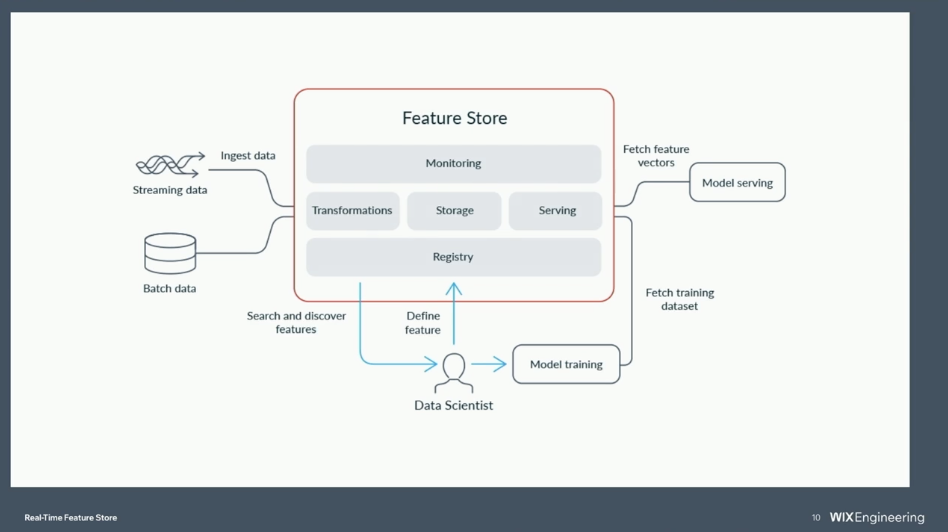
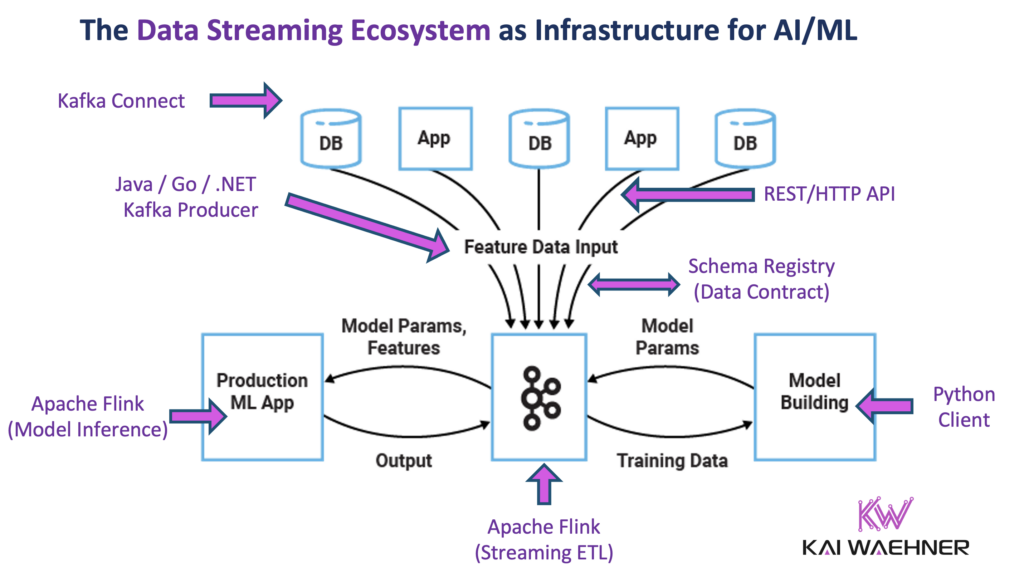
A key component of the AI/ML architecture that enables this is the feature store. It’s the system responsible for computing, storing, and serving the features that machine learning models rely on—both during training and in real-time production environments. To meet today’s demands, the feature store must be real-time, reliable, and deeply integrated with the entire AI/ML data pipeline.
Wix.com is an excellent example of how this can be done at scale. By combining Apache Kafka and Apache Flink, they built a real-time feature store that powers personalized recommendations for millions of users. This blog post explores how streaming data technologies are reshaping AI infrastructure—and how Wix made it work in production.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various AI examples across industries.
This blog post explores how Wix uses real-time data streaming to power its online feature store and drive customer engagement. It draws from the talk “Before and After: Transforming Wix’s Online Feature Store with Apache Flink” by Omer Yogev and Omer Cohen, and insights from my fireside chat with Josef Goldstein, Head of R&D for Wix’s Big Data Platform, at the Current Data Streaming Conference.
What Is a Feature Store in an AI/ML Architecture?
In machine learning, a feature is an individual measurable property or signal used by a model to make predictions—such as a user’s last login time, purchase history, or number of website visits.
A feature store is a central platform for managing these features across the ML lifecycle. It supports the entire process—creation, transformation, storage, and serving—across both real-time and batch data. In modern ML systems, features are reused across models and use cases.
The feature store ensures consistency between training and inference, simplifies engineering workflows, and promotes collaboration between data scientists and developers.
Key components of a feature store include:
- Feature registration and metadata
- Real-time and batch ingestion
- Online and offline storage
- Versioning and reproducibility
- Integration with model training and inference systems
Why Online / Real-Time Matters for a Feature Store
Batch feature stores are not enough for today’s use cases. Real-time personalization, fraud detection, and predictive services demand fresh data and low-latency access.
Online (real-time) feature stores:
- Deliver features with millisecond latency
- React to new user behavior instantly
- Support continuous learning and fast feedback loops
- Improve user experience and business outcomes
Without real-time capabilities, models operate on stale data. This limits accuracy and reduces the value of AI investments.
Wix.com: A No-Code Website Builder and Global SaaS Leader Powering 7% of the Internet
Wix is a global SaaS company that enables users to build websites, manage content, and grow online businesses. It provides drag-and-drop web design tools, e-commerce solutions, and digital marketing services. Real-time AI-powered features personalize the experience, making it even easier and faster for users to build high-quality websites.
Business model:
- Freemium platform with premium subscriptions
- Revenue from value-added services like hosting, payments, and custom domains
Scale:
- Powers 7% of the internet’s websites
- Serves over 200 million users worldwide
- Operates 2,300+ microservices
To deliver seamless digital experiences, Wix relies heavily on real-time data streaming.
How Wix.com Leverages Data Streaming with Apache Kafka and Flink
Wix’s data architecture is powered by Apache Kafka and Apache Flink. These technologies enable scalable, low-latency data pipelines that feed into analytics, monitoring, and machine learning systems.
Here are a few impressive numbers about Wix’ data platform:
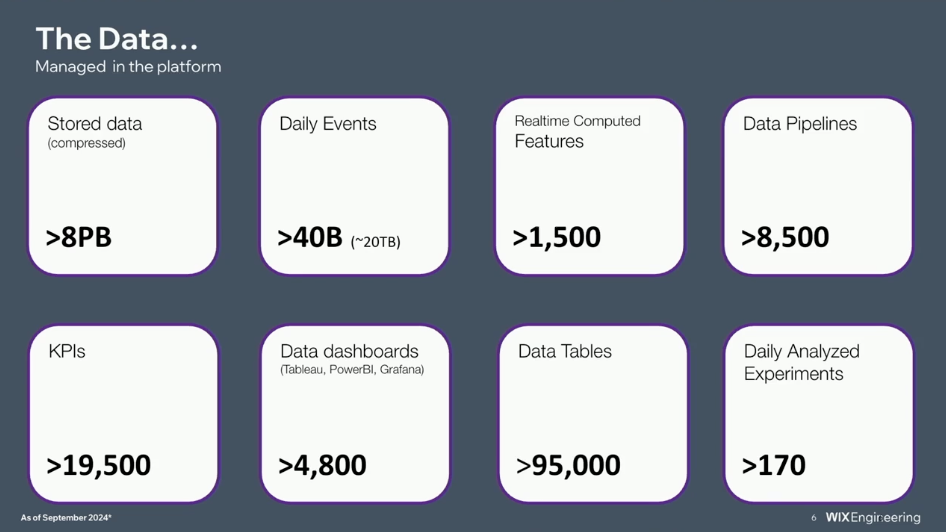
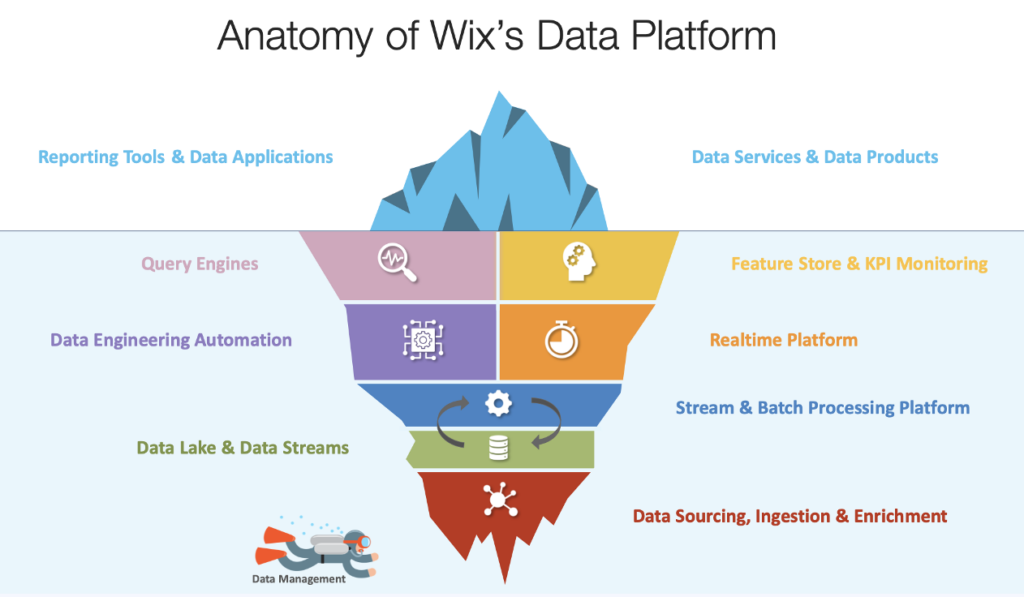
The Wix data platform combines data streaming, a feature store, query engines, and a data lake to unify real-time and batch workloads. Data streaming complements the data lake and other components by enabling immediate processing and delivery of fresh data across the platform.
Apache Kafka Usage at Wix
At Wix, Kafka plays a central role in the data architecture. It enables seamless communication between microservices, orchestrates data pipelines, and supports real-time observability and monitoring. Kafka also serves as the foundation for feeding data into analytics platforms and machine learning systems.
A few impressive facts:
- 70+ billion events processed per day
- 50,000 Kafka topics
- Used across all services for messaging, telemetry, and data integration
Kafka Proxy Architecture using gRPC
Wix also built a proxy architecture using gRPC to simplify Kafka integration for developers. The system includes:
- Advanced retry logic
- Dead letter queues
- Cross-data-center replication
- Custom dashboards for message tracing and debugging
Kafka enables horizontal scalability and strict decoupling between producers and consumers.
Wix’s Evaluation Framework for Stream Processing Technologies
To choose the right engine for real-time feature processing, Wix evaluated several stream processing technologies. The team compared three open-source options—Kafka Streams, Spark Structured Streaming, and Apache Flink—alongside Confluent Cloud’s serverless Flink offering.
From Wix’s perspective, the comparison table below highlights the key differences they observed in latency, throughput, operational complexity, and time to market across these stream processing options:
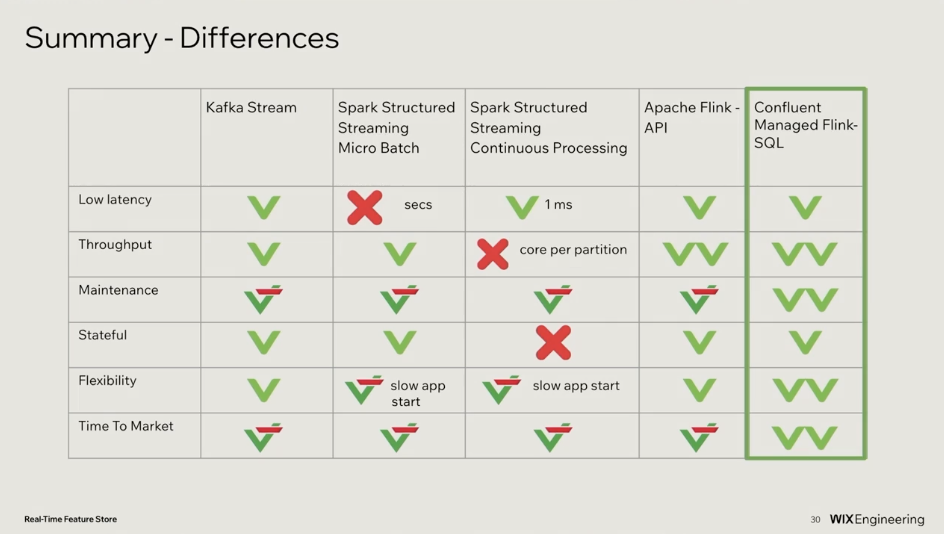
For a broader overview of stream processing technologies, see my Data Streaming Landscape. I also compared Kafka Streams and Apache Flink in a dedicated blog post.
Apache Flink Usage at Wix
At Wix, Apache Flink is used for high-throughput, low-latency stream processing to support real-time feature transformations and aggregations. It integrates natively with Kafka for both input and output to ensure seamless data flow across the platform.
Wix leverages FlinkSQL for complex computations and runs in a serverless environment using Confluent Cloud. Its stateful processing capabilities are key to delivering consistent, real-time machine learning features at scale.
Apache Kafka and Flink for an Online Feature Store
Wix rebuilt its online feature store with Kafka and Flink at the center. The system processes billions of events daily and supports over 3,000 features.
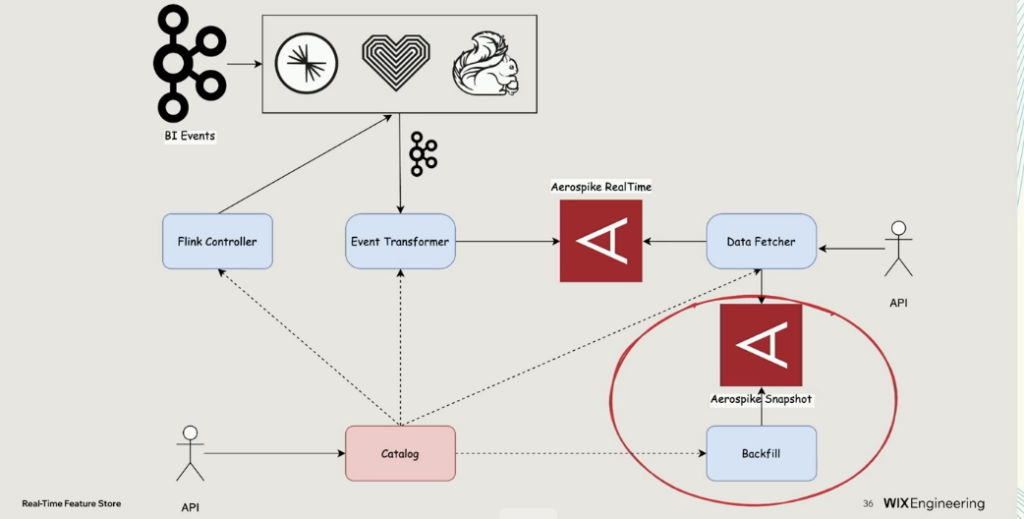
Architecture:
- Source: Kafka topics
- Transform: Flink SQL queries (windowing, joins, aggregations)
- Sink: Kafka output for downstream consumers and real-time ML inference
- Storage: Aerospike for online lookups
Benefits:
- Real-time updates
- Fault tolerance with Flink checkpoints
- Exactly-once delivery
- Scalable processing
The platform enables immediate personalization, where each user interaction updates model inputs in near real time.
The Future of Real-Time AI Infrastructure Powered by Data Streaming with Kafka and Flink
Wix’s journey reflects a larger trend: companies are moving away from batch ETL and toward real-time AI architectures that prioritize speed, scalability, and accuracy.
Key shifts include:
- From monolithic ML pipelines to modular, streaming-first platforms
- From static daily updates to continuous feature refreshes
- From fragile legacy tools to robust data mesh platforms
Kafka serves as the transport layer, while Flink adds a powerful, stateful compute layer. Together, they form the foundation for AI systems that react in real time, adapt continuously, and scale effortlessly.
Two architectural principles are also shaping this transformation. The Kappa architecture simplifies system complexity by treating all data as a stream, eliminating the need for separate batch and streaming paths. Meanwhile, a shift-left architecture moves data processing and feature computation closer to the source—at ingest—improving latency, resilience, and model accuracy.
As organizations embrace real-time AI and machine learning, the value of a data streaming infrastructure becomes clear:
- Faster time to insight
- More accurate and responsive models
- Lower operational overhead
This evolution drives both innovation and efficiency. Real-time AI infrastructure accelerates decision-making, reduces data inconsistencies, and delivers measurable business impact.
The future of machine learning is built on data streaming. Now is the time to lay the foundation.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various AI examples across industries.