Agentic AI
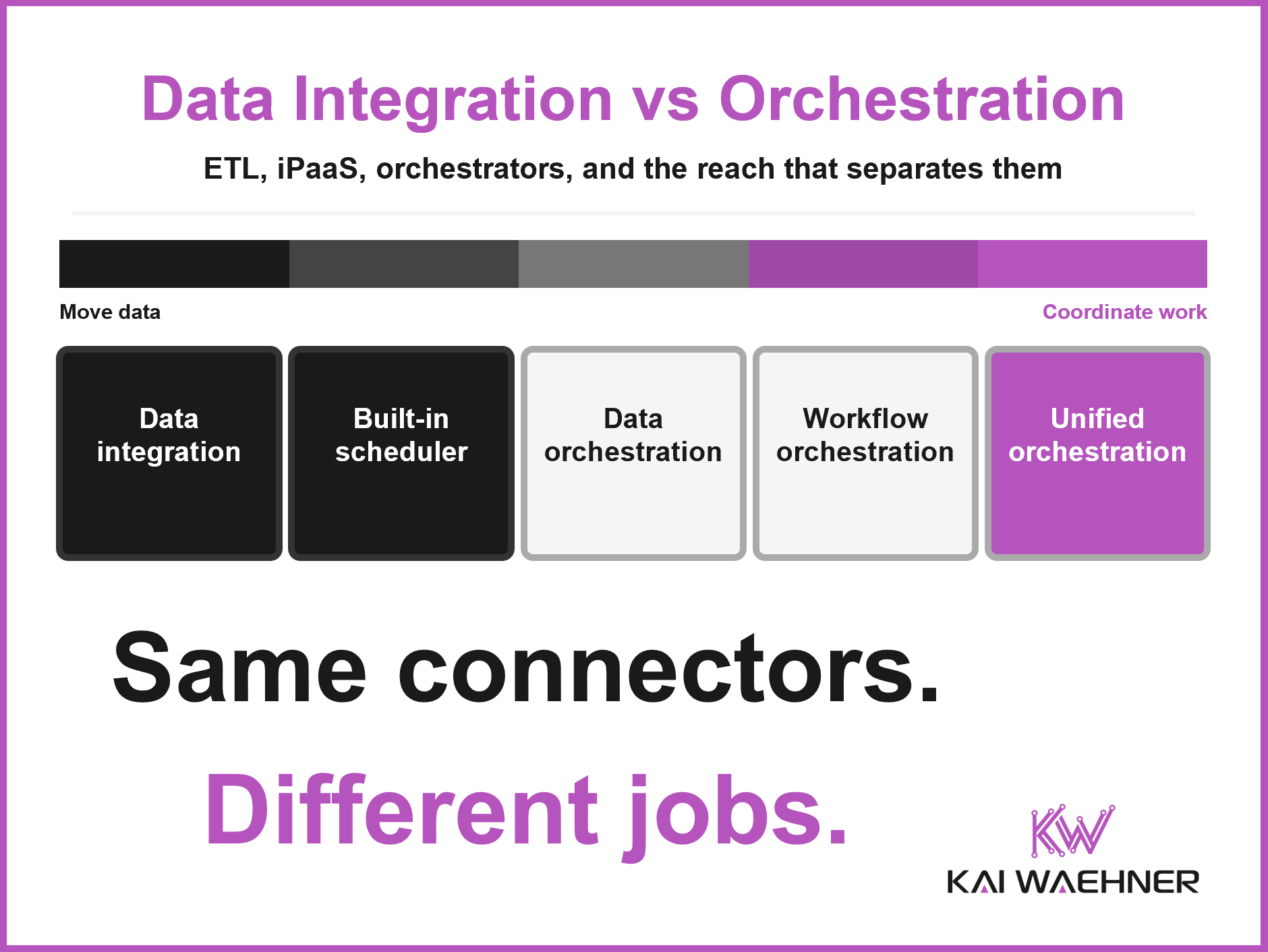
Data integration and workflow orchestration get confused because both ship hundreds of connectors. This post draws the line: integration moves and reshapes data, orchestration coordinates

Data integration and workflow orchestration get confused because both ship hundreds of connectors. This post draws the line: integration moves and reshapes data, orchestration coordinates

Process intelligence has become three things, not one: mining, orchestration, and a decision gate. Here is how they fit, why agentic AI raises the stakes,

Most vendors sell milliseconds, but most enterprise use cases do not need them. A critical look at Kafka, Flink, Spark, Pulsar, and Redpanda, and why

Edge to cloud is not one integration problem. It is four: telemetry going up, control going down, sites syncing sideways, and data reaching people. This

The Data Integration Landscape 2026 maps every major vendor across three communication paradigms: request-response, event-driven, and batch. Event streaming has become the architectural foundation for

Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka

XML, JSON, and YAML were built for different jobs in different eras. This post covers where each came from, how they compare, and where each
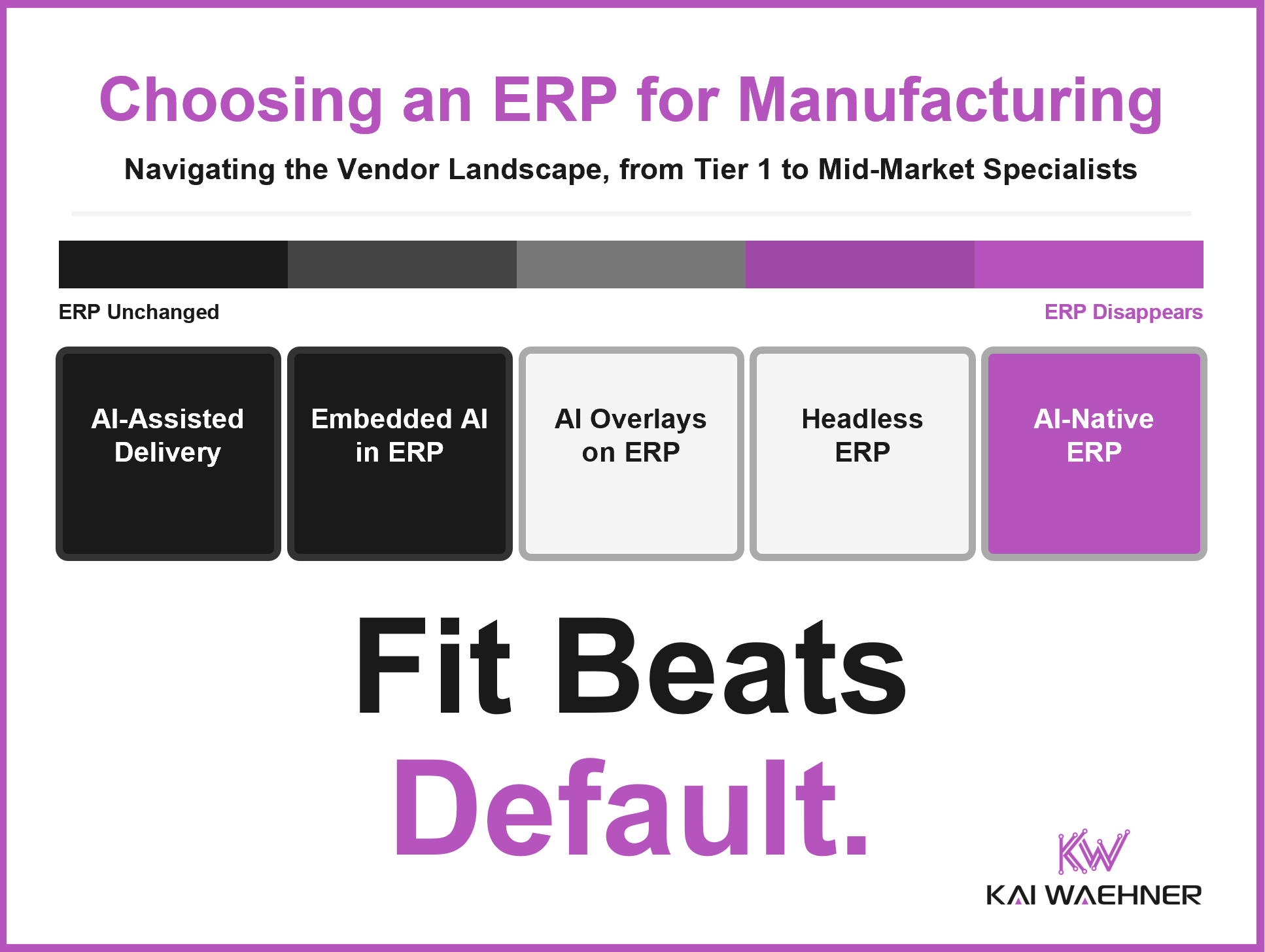
ERP vendor selection for manufacturing is not a product decision. It is a strategic bet on fit, total cost, and which AI future your vendor
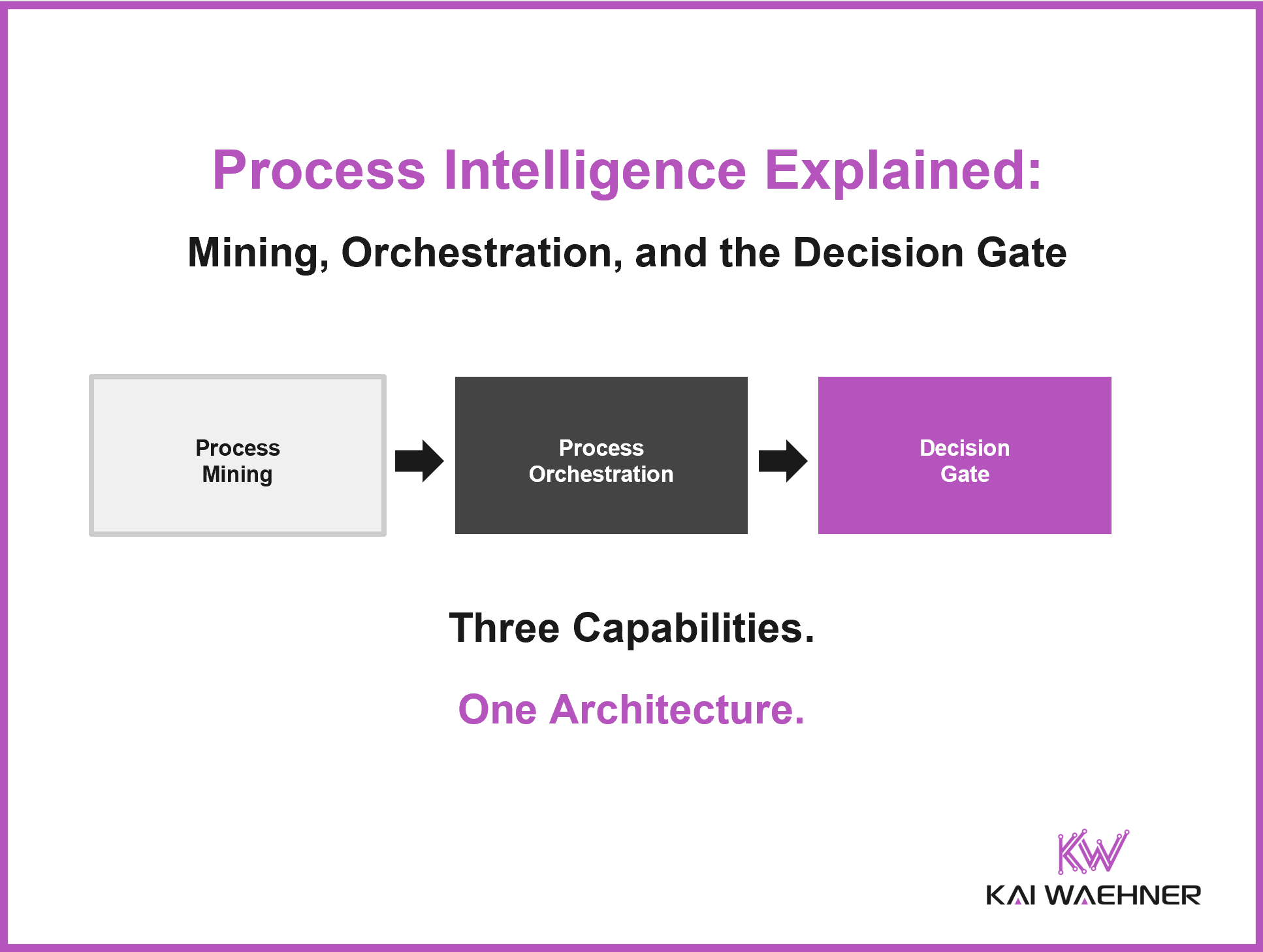
Process intelligence is not a single tool. It combines process mining, process orchestration, and a decision gate into one architecture that shows how processes really
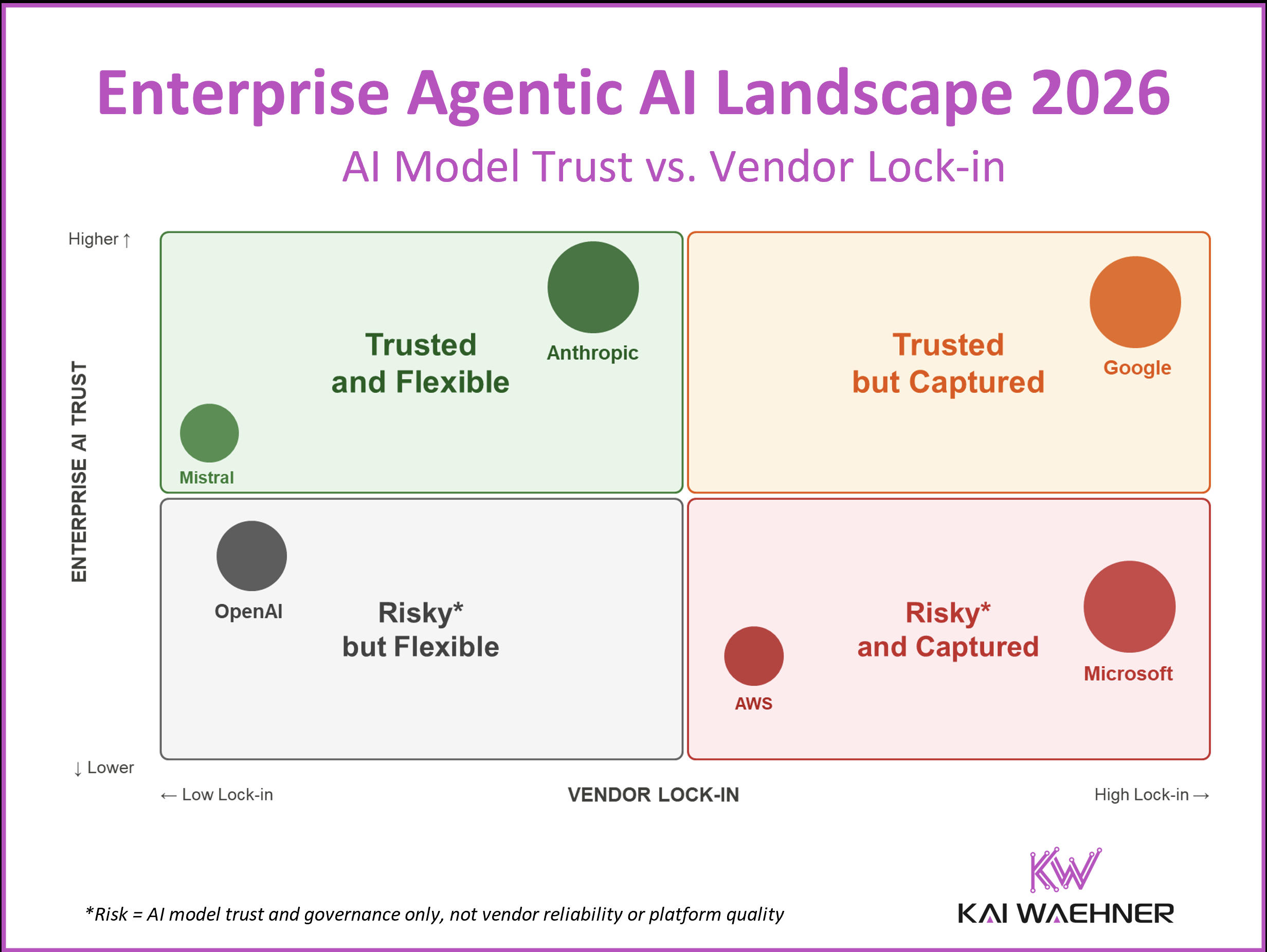
The Enterprise Agentic AI Landscape 2026 maps every major AI vendor across two dimensions that matter most: how much you trust their AI, and how
You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information