The Apache Kafka community introduced KIP-500 to remove ZooKeeper and replace it with KRaft, a new built-in consensus layer. This was a major milestone. It simplified operations, improved scalability, and reduced complexity. Importantly, Kafka supports smooth, zero downtime migrations from ZooKeeper to KRaft, even for large, business critical clusters. But NOT with Amazon MSK…

Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various data Kafka architectures and best practices.
Challenge: Amazon MSK Migration Required to Remove ZooKeeper from Apache Kafka
Amazon MSK users face a difficult reality. You cannot do an in place upgrade from ZooKeeper based clusters to the new Kafka KRaft mode. Instead, AWS requires a full migration to a new cluster if you want to be on the latest version of Kafka without ZooKeeper. Read the AWS docs to learn more:

This removes one of Apache Kafka’s biggest advantages: zero downtime migration. Many enterprises have already completed seamless migrations, including ZooKeeper removal, with their own Kafka or Confluent clusters. These systems power business critical data streaming applications 24/7 without any data loss. MSK, however, does not support this path. A migration is mandatory if you want to stay on updated Kafka versions to benefit from community bug fixes, security patches, and the latest new features.
Do Not Forget the Kafka Clients During the Migration
Migrating a Kafka cluster is only half the story. Every producer, consumer, and stream processing application depends on client connectivity. During a Kafka cluster migration, handling the clients is often the biggest challenge. Like the Kafka brokers, Kafka clients need to be upgraded over time to stay on community supported versions.
A practical checklist for handling clients during migration includes:
Connection Management
- Update client configurations to point to the new cluster endpoints.
- Use DNS-based aliases or load balancers to abstract cluster addresses.
Compatibility Checks
- Validate that client libraries are compatible with the target Kafka version.
- Pay special attention to features like KRaft support and newer APIs.
Authentication and Authorization
- Reapply IAM roles, ACLs, and other security settings in the new cluster.
- Test service accounts and credentials ahead of cutover.
Consumer Offsets and State
- Migrate consumer offsets from the old cluster to the new one.
- For stateful stream processing apps (Kafka Streams, Flink, ksqlDB), plan state migration or resynchronization.
Testing and Phased Rollout
- Run integration tests against the new cluster before cutover.
- Consider dual writes or phased traffic migration to reduce risk.
Evaluation: The Data Streaming Landscape
As a migration is unavoidable for Amazon MSK if you want to stay on the latest version for bug fixes, security patches, and accessing the latest new features, it is also an opportunity to step back and evaluate your data streaming strategy. The Apache Kafka ecosystem has evolved dramatically in recent years. Beyond Amazon MSK, you will find:
- Cloud services from hyperscalers.
- Startups offering modern architectures and simplified operations.
- Mature vendors with proven enterprise offerings, SLAs, and governance.
Learn more in the data streaming landscape:
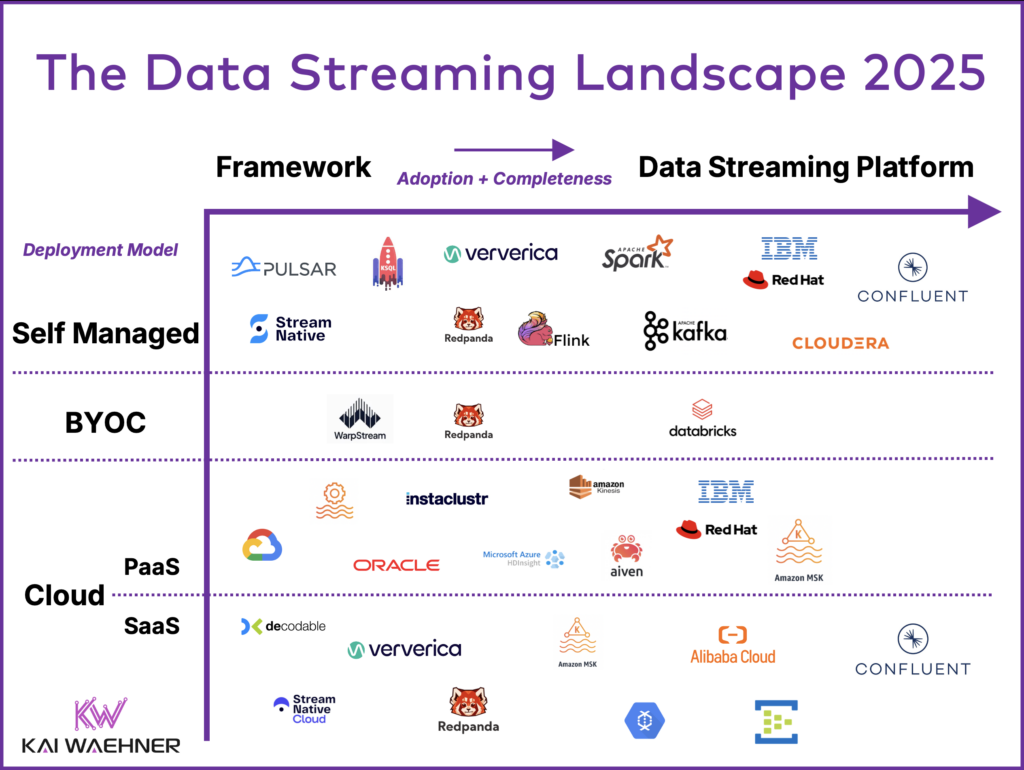
Key aspects to evaluate include cost, reliability, SLAs, security, and advanced features. Simply staying with MSK may not be the safest choice when disruption is already required in order to upgrade Kafka to newer versions without ZooKeeper.
And let’s not forget: Amazon MSK’s SLAs cover the cluster infrastructure, but not Kafka itself. So when things break, you might just find yourself in the world’s most expensive do-it-yourself support plan. But I am sure you read the Amazon MSK T&C and know this already… 🙂
Recommendations for the Evaluation of a Data Streaming Platform
To make the right decision for your organization to choose the right Kafka offering:
-
Read the terms and conditions carefully. Understand the support SLAs of each vendor, including Confluent, WarpStream, Aiven, Redpanda Data, Buf, AutoMQ, and others.
-
Evaluate the true total cost of ownership. Do not stop at the “Kafka Cloud Service Cost.” There are many hidden factors to consider, and some vendors use misleading marketing around costs.
Kafka clusters on Amazon MSK that still depend on ZooKeeper face growing risks and uncertainty. The real question is: where will you migrate to? A newer version of Kafka on the same Amazon MSK infrastructure, or another Kafka cloud service?
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various data Kafka architectures and best practices.