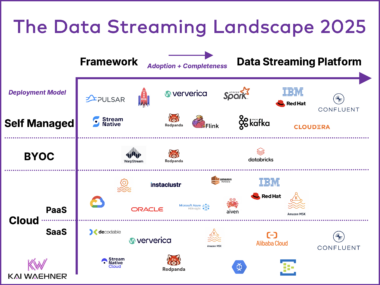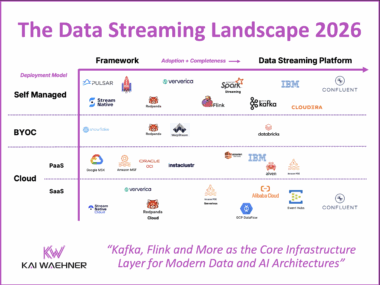
The Data Streaming Landscape 2026
Data streaming is now a core software category in modern data architecture. It powers real-time use cases like fraud prevention, personalization, supply chain optimization, and AI automation. What started with open source Apache Kafka and Flink has grown into a critical layer for business operations. The 2026 Data Streaming Landscape shows the most relevant Data Streaming Platform evolution. These platforms connect systems, process data in motion, enforce governance, and support mission-critical workloads at scale. Kafka is the standard protocol, but protocol support alone is not enough. Enterprises need full feature compatibility, 24/7 support, and expert guidance for security, resilience, and cloud strategy.