In February 2016, I presented a brand new talk at OOP in Munich: “Comparison of Frameworks and Tools for Big Data Log Analytics and IT Operations Analytics”. The focus of the talk is to discuss different open source frameworks, SaaS cloud offerings and enterprise products for analyzing big masses of distributed log events. This topic is getting much more traction these days with the emerging architecture concept of Microservices.
Key Take-Aways
- Log Analytics enables IT Operations Analytics for Machine Data
- Correlation of Events is the Key for Added Business Value
- Log Management is complementary to other Big Data Components
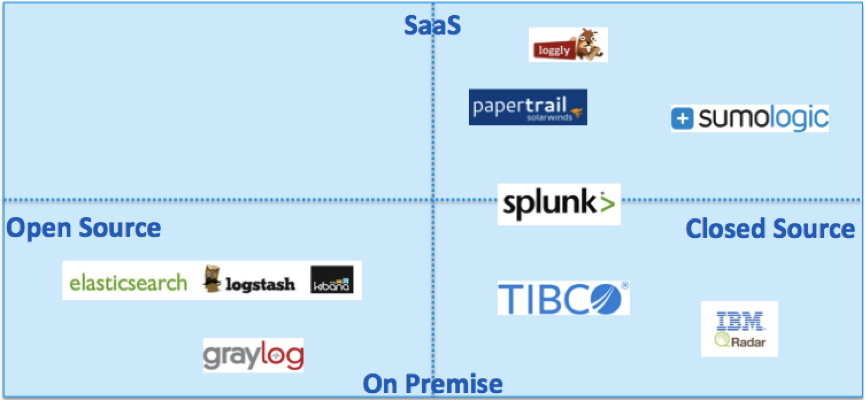
Log Management with Papertrail, ELK Stack, TIBCO LogLogic, Splunk, etc.
Log Management is a mature concept since many years; used for troubleshooting, root cause analysis, and solving security issues of devices such as web servers, firewalls, routers, databases, etc. In the meantime, it is also used for analyzing applications and distributed deployments using SOA or Microservices architectures.
The slide deck compares different solutions for log management:
- SaaS Cloud, e.g. Papertrail, Loggly, Sumo Logic
- Open Source Frameworks, e.g. ELK stack (Logstash, Elasticsearch, Kibana), Graylog
- Enterprise Products, e.g. TIBCO LogLogic, IBM QRadar, Splunk
IT Operations Analytics (ITOA) with TIBCO Unity
IT Operations Analytics is a new, very young market growing strongly (100% year-by-year, according to Gartner). In contrary to Log Management, it does not just focus on analyzing historical data, but also enables to make complex correlations of distributed data to allow predictive analytics in (near) real time. TIBCO Unity is a product heading into this direction. You can integrate log data, but also real time events (e.g. via TIBCO Hawk) to enable monitoring, analysis and complex correlation of distributed Microserices.
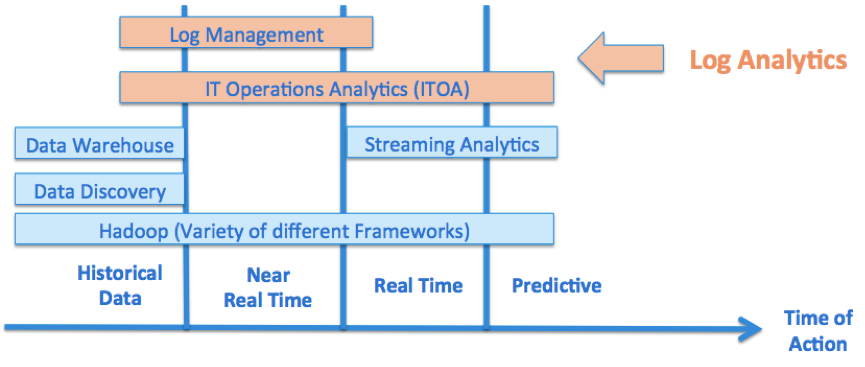
What about Apache Hadoop versus Log Management and ITOA?
Why not use just Apache Hadoop? You can also store and analyze all data on its cluster! Why not just use Log Collectors (such as Apache Flume) and send data directly to Hadoop without Log Analytics “in the middle”?
Here are some reasons… Log Management and ITOA tools
- are an integrated solution for data analysis (tooling, consulting, support)
- are built exactly for these use cases
- involve data indexing, data processing (querying) and data visualization by means of dashboards and other tools out-of-the-box
- offer easy-of-use tooling and allow fast time-to-market / low TCO
The following graphic shows the different concepts and when they are usually used:
Having said that, a better Hadoop integration is possible, nevertheless! It might make sense to leverage both together: The great tooling for Log Management, plus the Hadoop storage with very high scalability for really BIG data. For example, TIBCO Unity uses Apache Kafka under the hood to support processing and scaling millions of messages. Thus, integration with Hadoop storage might be possible in a future release… 🙂
Slides
Finally, here is my slide deck:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
As always, I appreciate any questions or feedback!





