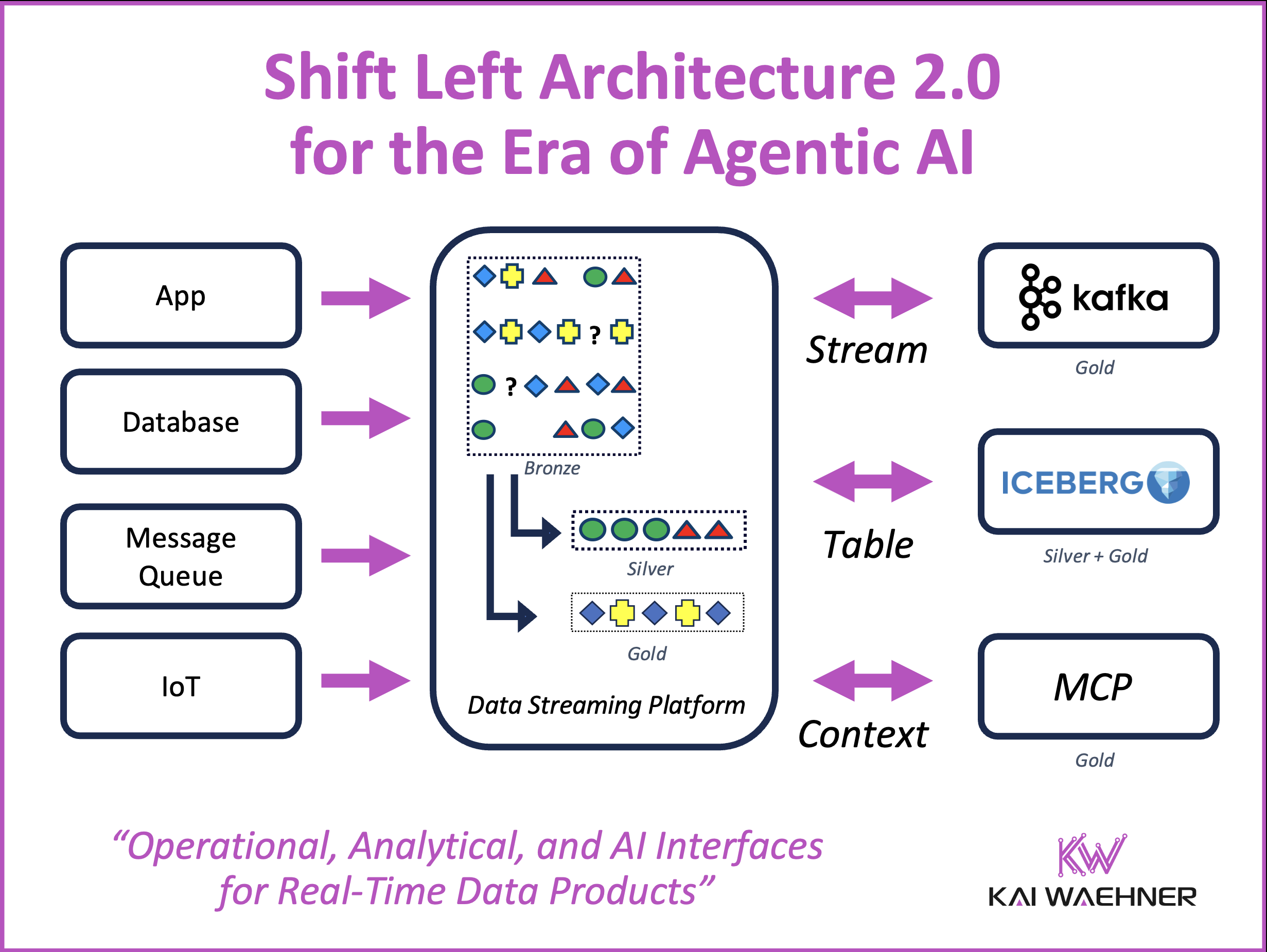
Agentic AI
The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data products are built once and served to multiple consumers. The

The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data products are built once and served to multiple consumers. The
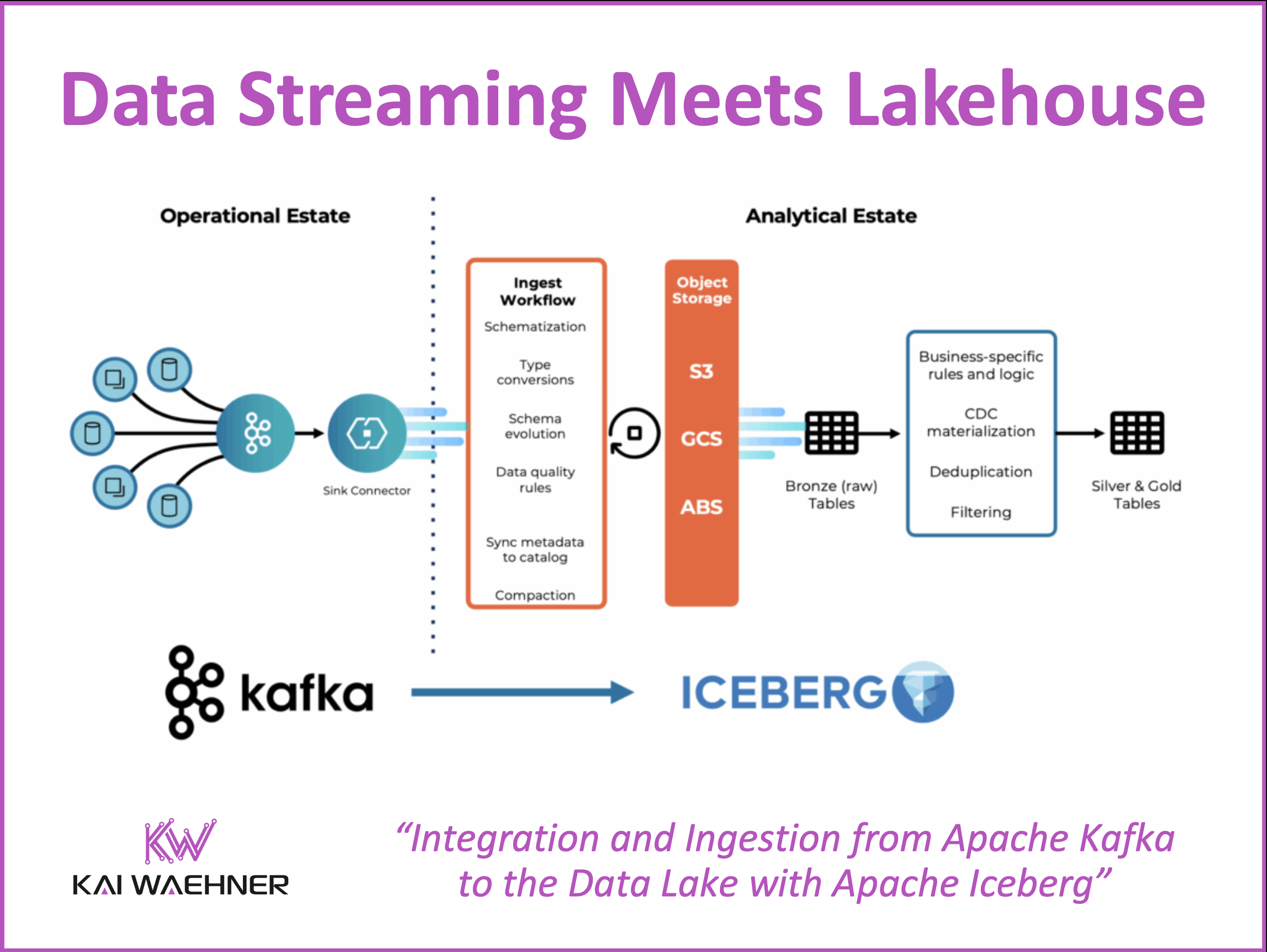
Apache Iceberg is gaining momentum as the open table format of choice for modern data architectures. In this blog post, the key takeaways from my
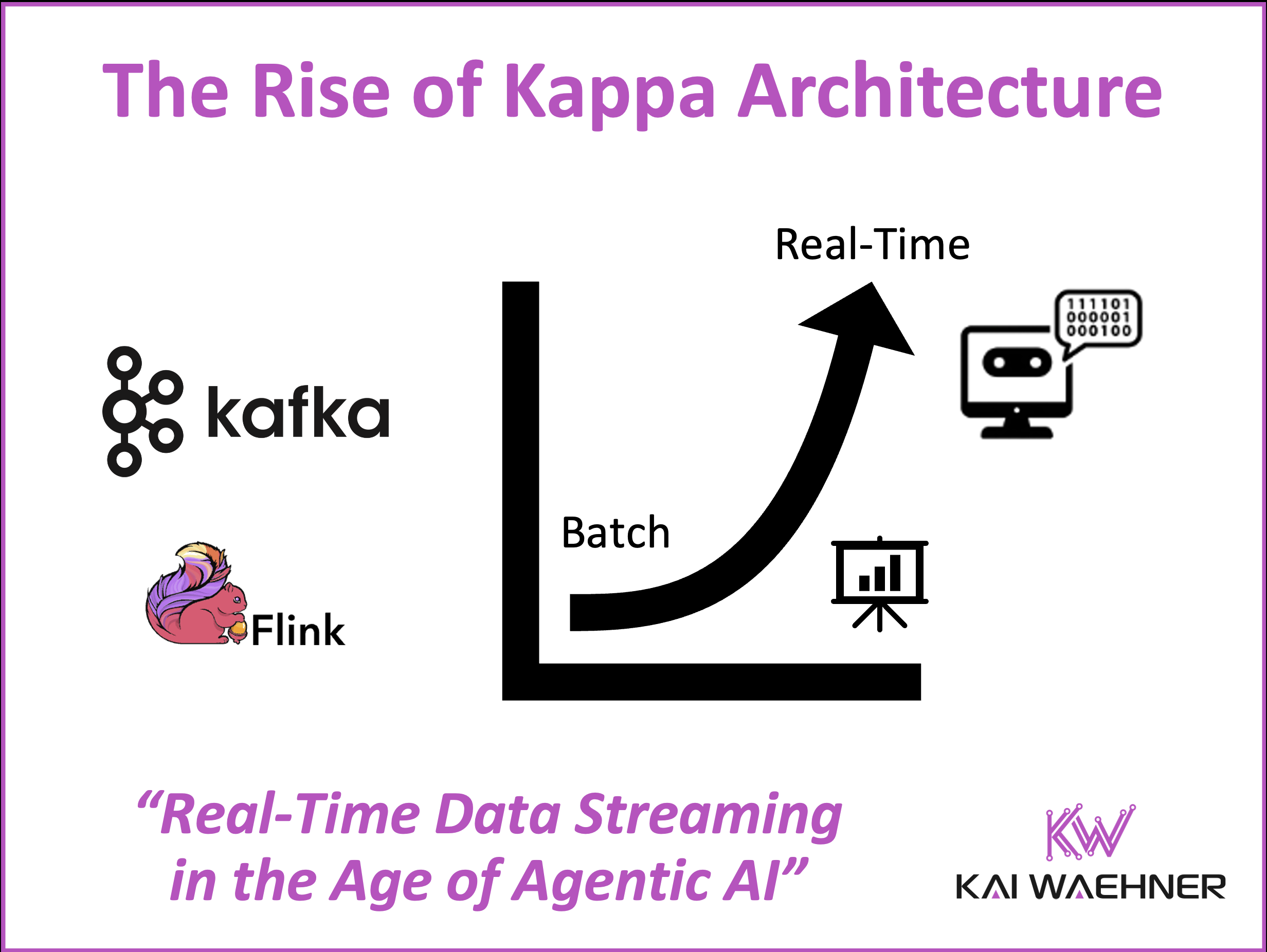
The shift from Lambda to Kappa architecture reflects the growing demand for unified, real-time data pipelines that serve both analytical and operational needs. With the

Confluent and Databricks enable a modern data architecture that unifies real-time streaming and lakehouse analytics. By combining shift-left principles with the structured layers of the
This blog explores how Confluent and Databricks address data integration and processing in modern architectures. Confluent provides real-time, event-driven pipelines connecting operational systems, APIs, and

Industrial enterprises face increasing pressure to move faster, automate more, and adapt to constant change—without compromising reliability. Siemens Digital Industries addresses this challenge by combining
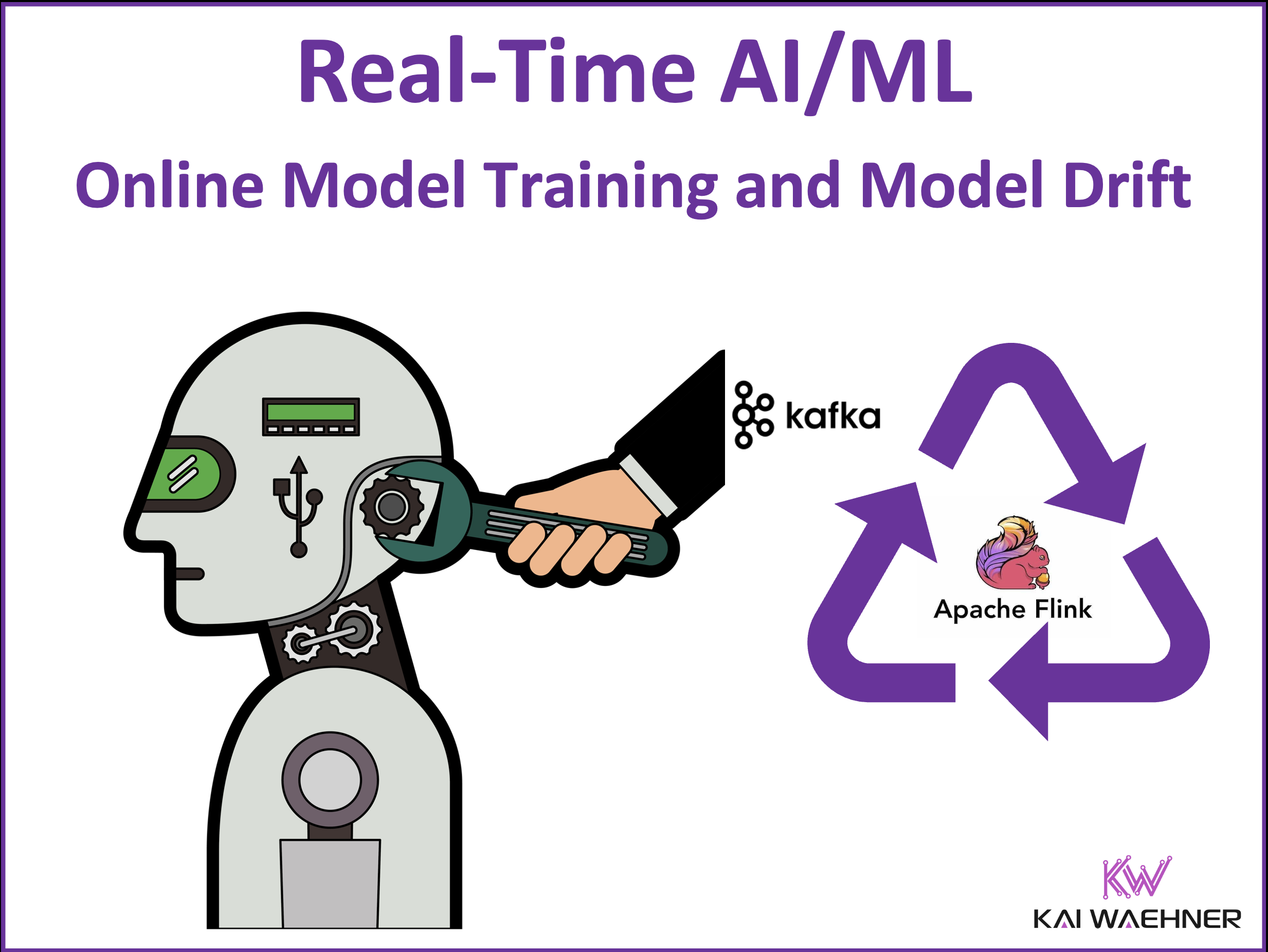
The rise of real-time AI and machine learning is reshaping the competitive landscape. Traditional batch-trained models struggle with model drift, leading to inaccurate predictions and
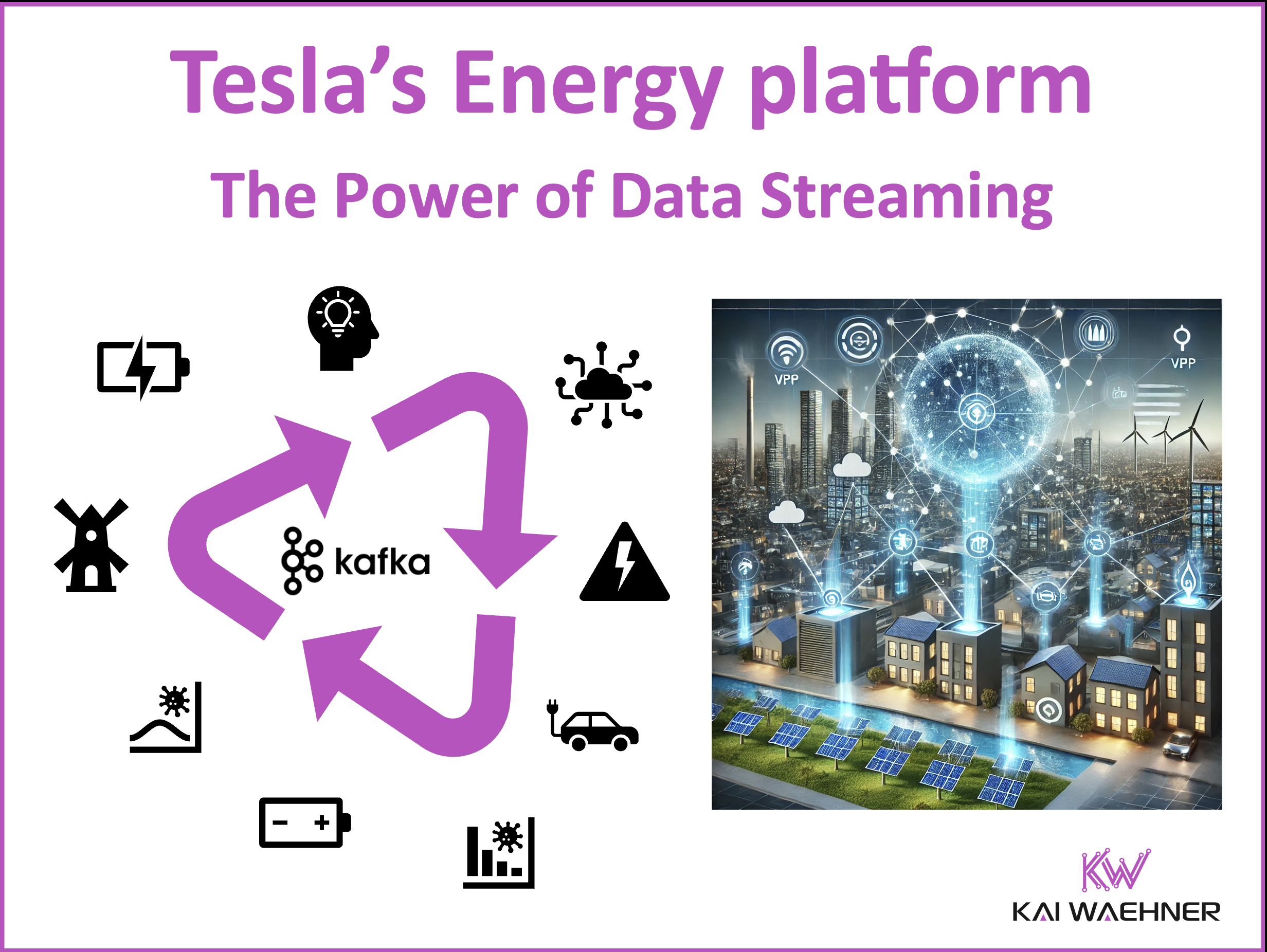
Tesla’s Virtual Power Plant (VPP) turns thousands of home batteries, solar panels, and energy storage systems into a coordinated, intelligent energy network. By leveraging Apache
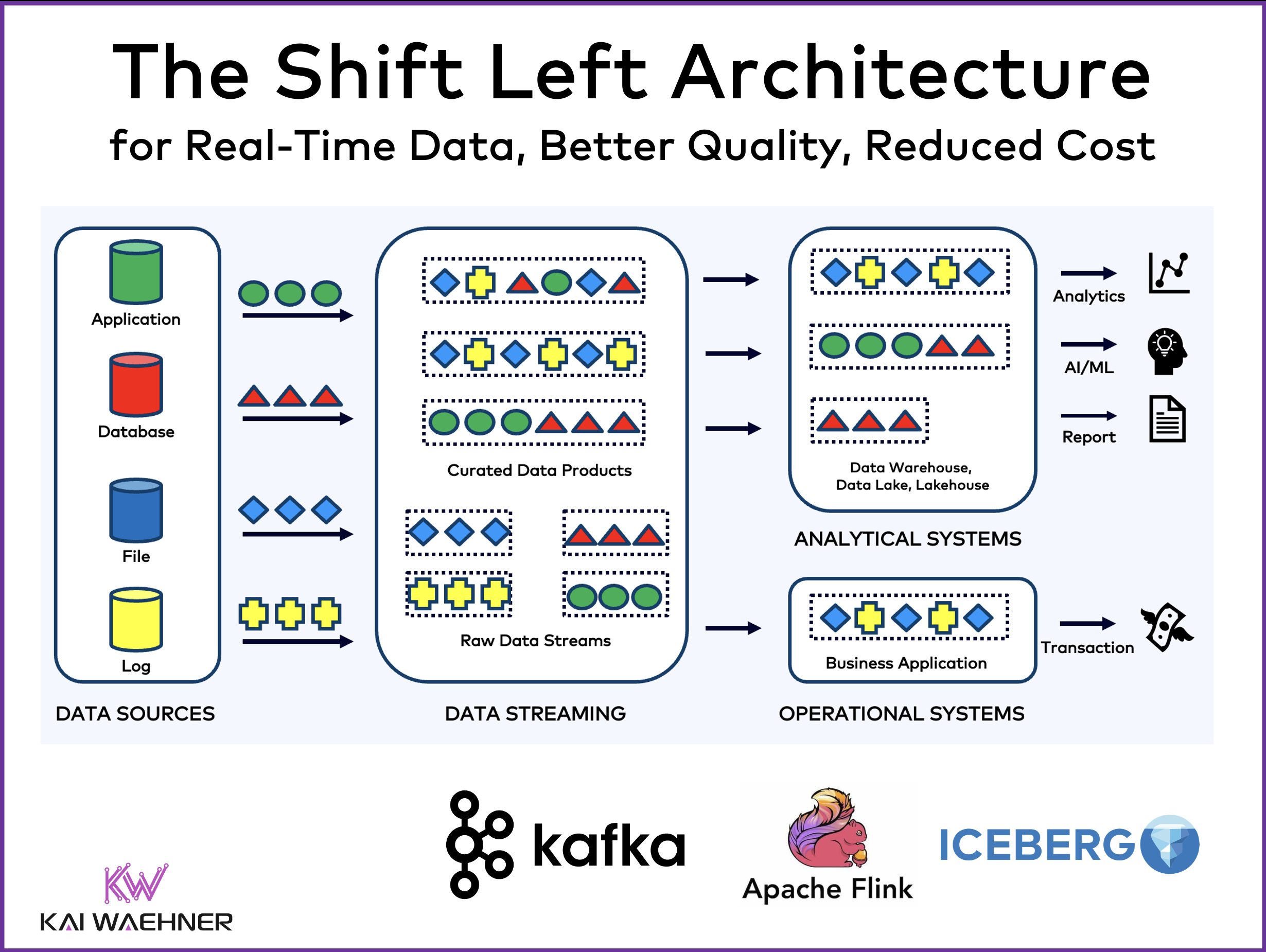
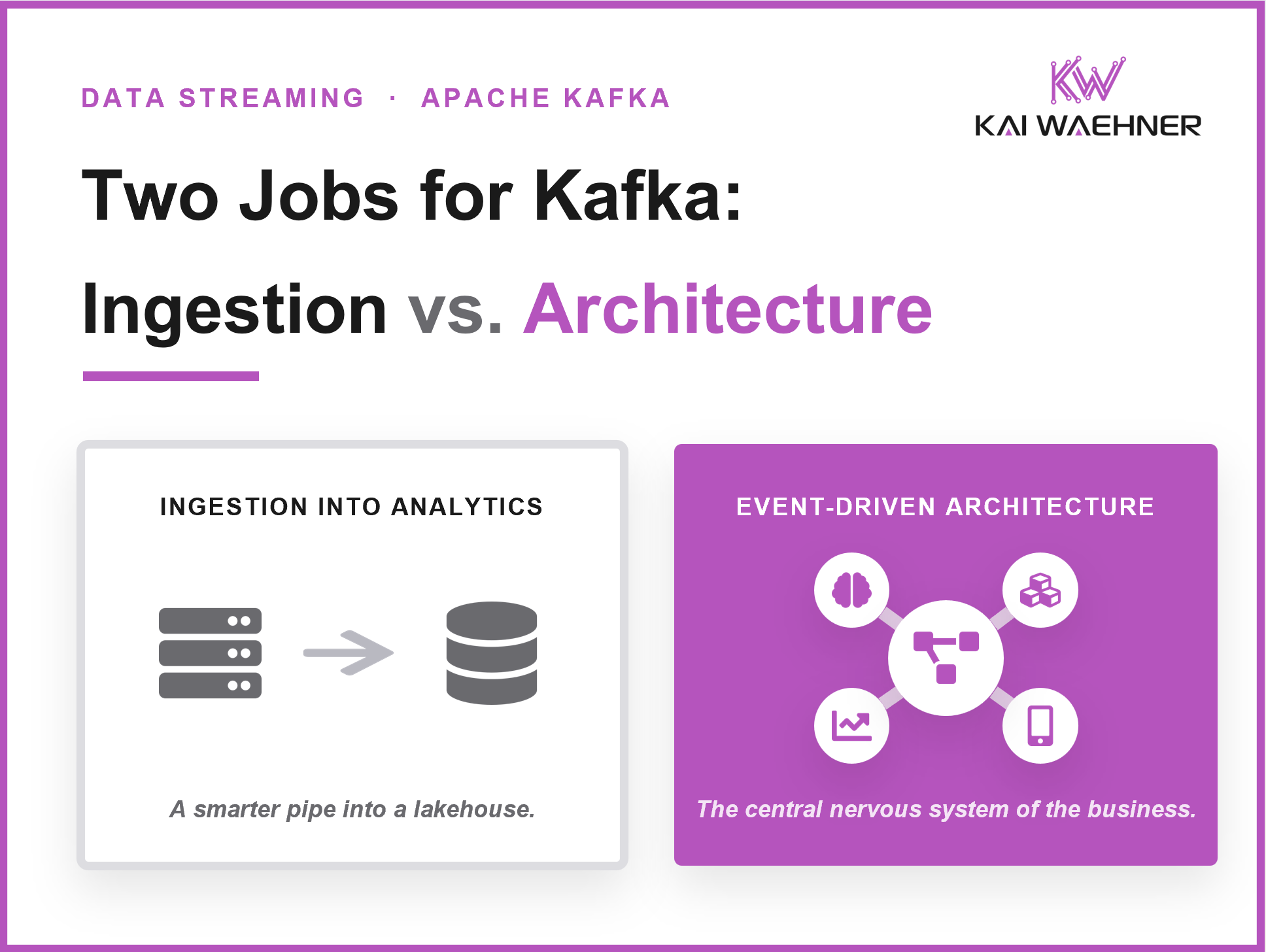
Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.


You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information