
Analytics
Confluent and Databricks enable a modern data architecture that unifies real-time streaming and lakehouse analytics. By combining shift-left principles with the structured layers of the

Confluent and Databricks enable a modern data architecture that unifies real-time streaming and lakehouse analytics. By combining shift-left principles with the structured layers of the

In today’s data-driven world, understanding data at rest versus data in motion is crucial for businesses. Data streaming frameworks like Apache Kafka and Apache Flink

If you ask your favorite large language model, Microsoft Fabric appears to be the ultimate solution for any data challenge you can imagine. That’s also

Apache Kafka became the de facto standard for data streaming. However, the combination of an event-driven architecture with request-response APIs is crucial for most enterprise

Apache Kafka is the de facto standard for data streaming to process data in motion. With its significant adoption growth across all industries, I get

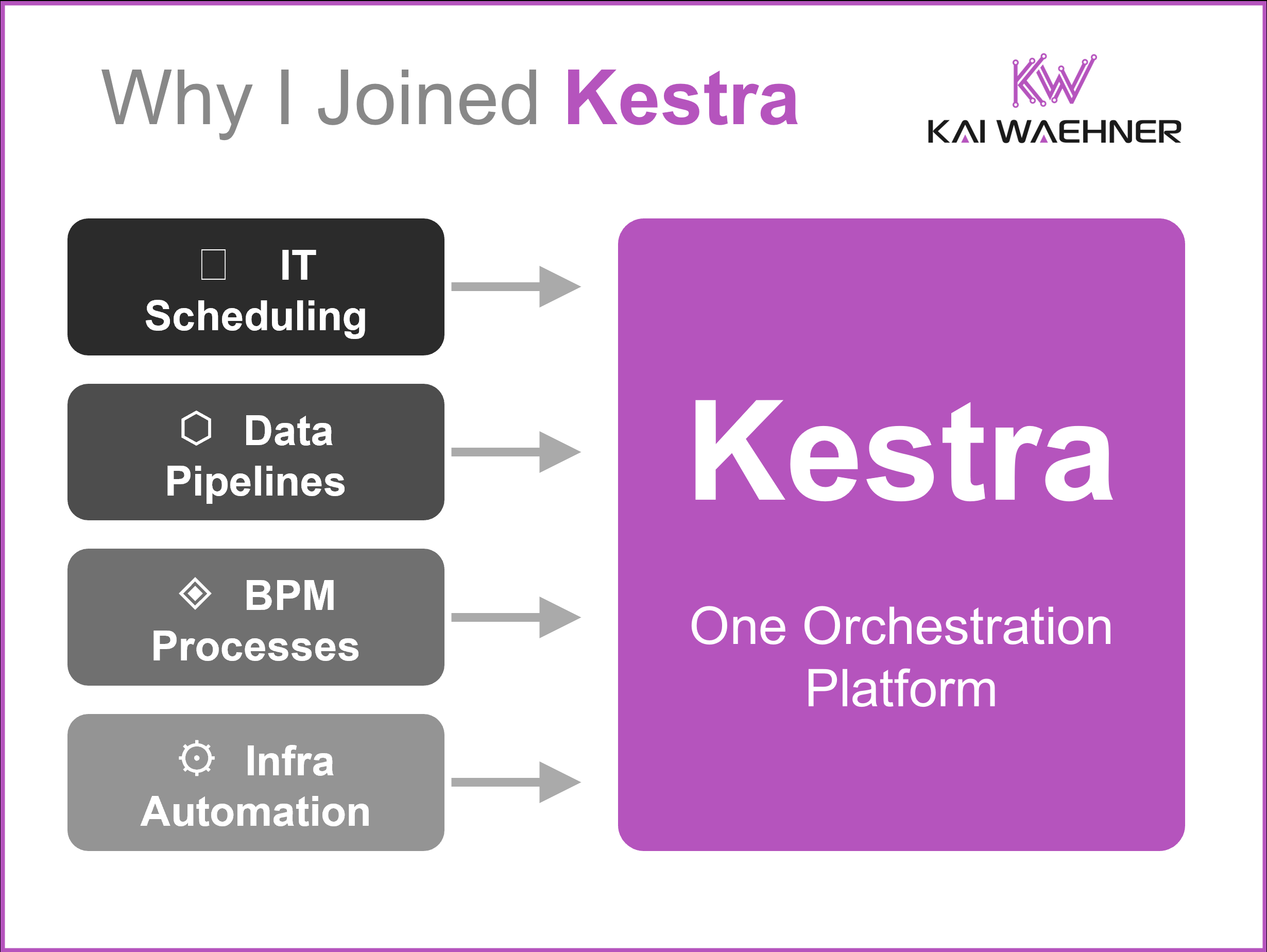
Data Streaming is one of the most relevant buzzwords in tech to build scalable real-time applications in the cloud and innovative business models. Do you

If there were a buzzword of the hour, it would undoubtedly be “data mesh”! This new architectural paradigm unlocks analytic and transactional data at scale

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information