Data Streaming Meets Lakehouse: Apache Iceberg for Unified Real-Time and Batch Analytics
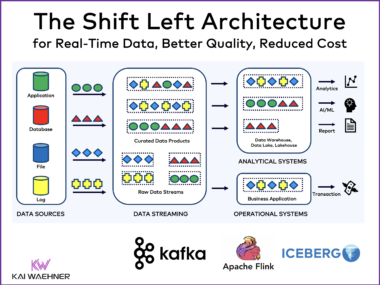
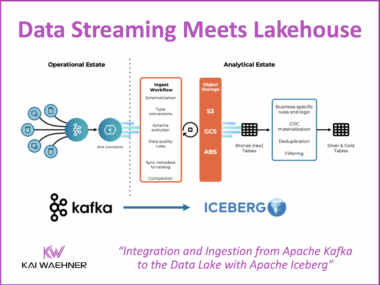
Apache Iceberg is gaining momentum as the open table format of choice for modern data architectures. In this blog post, the key takeaways from my talk at Open Source Data Summit are shared, along with the full video and downloadable slides. The session explores how Iceberg fits into real-time data streaming with Apache Kafka and Flink, why streaming into a data lake is complex, and what patterns actually work in production. It also covers technical challenges like schema evolution, compaction, and governance — and how to solve them. Watch the session, review the slides, and learn how Iceberg helps build reliable, streaming-powered data products at scale.