I had a talk at MesosCon 2017 Europe in Prague about building highly scalable, mission-critical microservices with Apache Kafka, Kafka Streams and Apache Mesos / DCOS. I would like to share the slides and a video recording of the live demo.
Abstract
Microservices establish many benefits like agile, flexible development and deployment of business logic. However, a Microservice architecture also creates many new challenges. This includes increased communication between distributed instances, the need for orchestration, new fail-over requirements, and resiliency design patterns.
This session discusses how to build a highly scalable, performant, mission-critical microservice infrastructure with Apache Kafka, Kafka Streams and Apache Mesos respectively DC/OS. Apache Kafka brokers are used as powerful, scalable, distributed message backbone. Kafka’s Streams API allows to embed stream processing directly into any external microservice or business application. Without the need for a dedicated streaming cluster. Apache Mesos can be used as scalable infrastructure for both, the Apache Kafka brokers and external applications using the Kafka Streams API, to leverage the benefits of a cloud native platforms like service discovery, health checks, or fail-over management.
A live demo shows how to develop real time applications for your core business with Kafka messaging brokers and Kafka Streams API. You see how to deploy / manage / scale them on a DC/OS cluster using different deployment options.
Key takeaways
- Successful microservice architectures require a highly scalable messaging infrastructure combined with a cloud-native platform which manages distributed microservices
- Apache Kafka offers a highly scalable, mission critical infrastructure for distributed messaging and integration
- Kafka’s Streams API allows to embed stream processing into any external application or microservice
- Mesos respectively DC/OS allow management of both, Kafka brokers and external applications using Kafka Streams API, to leverage many built-in benefits like health checks, service discovery or fail-over control of microservices
- See a live demo which combines the Apache Kafka streaming platform and DC/OS
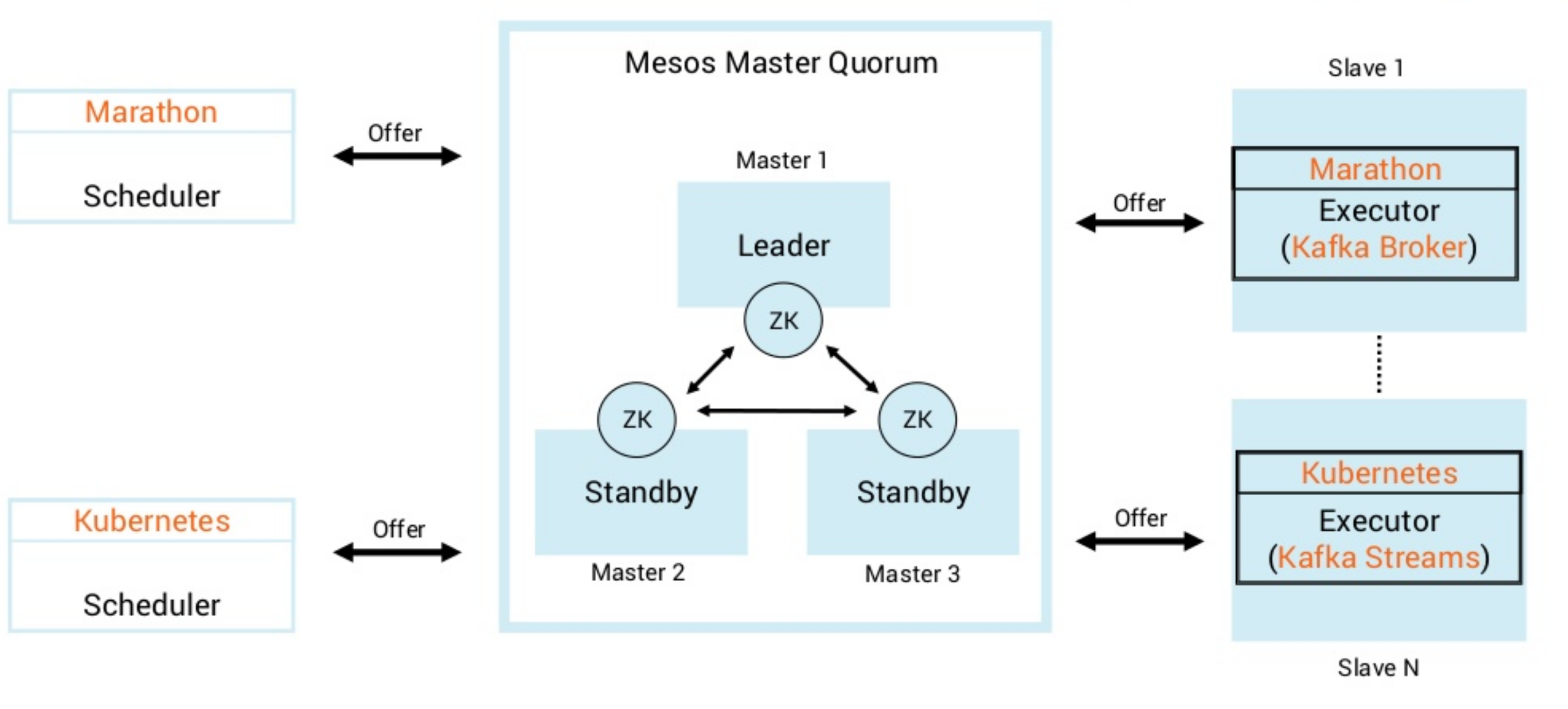
Architecture: Kafka Brokers + Kafka Streams on Kubernetes and DC/OS
The following picture shows the architecture. You can either run Kafka Brokers and Kafka Streams microservices natively on DC/OS via Marathon or leverage Kubernetes as Docker container orchestration tool (which is also supported my Mesosphere in the meantime).
Slides
Here are the slides from my talk:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Live Demo
The following video shows the live demo. It is built on AWS using Mesosphere’s Cloud Formation script to setup a DC/OS cluster in ten minutes.
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Here, I deployed both – Kafka brokers and Kafka Streams microservices – directly to DC/OS without leveraging Kubernetes. I expect to see many people continue to deploy Kafka brokers directly on DC/OS. For microservices many teams might move to the following stack: Microservice –> Docker –> Kubernetes –> DC/OS.
Do you also use Apache Mesos respectively DC/OS to run Kafka? Only the brokers or also Kafka clients (producers, consumers, Streams, Connect, KSQL, etc)? Or do you prefer another tool like Kubernetes (maybe on DC/OS)?