
FinOps brings finance, engineering, and operations together to manage cloud costs in real time. But many organizations still rely on delayed, batch-based reports that miss sudden spikes or waste. With Data Streaming leveraging Apache Kafka and Apache Flink, businesses can stream, process, and govern cloud usage data as it happens. This unlocks instant cost visibility, supports compliance, and enables automation. This post explores how data streaming powers modern FinOps—and how companies like Bitvavo and SumUp use it to scale securely and efficiently.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases. It features multiple use cases across financial services.
FinOps Fundamentals: Where Finance Meets DevOps
FinOps transforms how cloud costs are tracked, managed, and optimized. Instead of isolated budget reviews or delayed billing reports, FinOps introduces a continuous feedback loop. Engineering teams become responsible for the financial implications of their architecture. Finance gains technical insights to align budgeting with reality. And leadership can drive decisions based on live usage data.
At its core, FinOps introduces processes for monitoring cloud costs in real time, assigning spend to teams or services, and improving forecasting accuracy. However, most FinOps implementations today are still based on delayed batch pipelines. These systems may only pull billing data once per day, leaving organizations blind to cost anomalies until it’s too late.
This batch-driven model breaks down in fast-moving cloud environments, where one misconfigured workload can scale costs within minutes. Without real-time visibility, automation, and governance, FinOps becomes reactive—and expensive.
The Hidden Challenge of FinOps: Data Governance and Compliance
Cloud cost data is not just numerical. It contains metadata, user identities, service names, business units, and often personal or sensitive information. In regulated industries, financial reporting must also comply with internal audit controls, data retention policies, and external requirements like GDPR, SOC 2, or HIPAA.
Without strict governance, FinOps data becomes unreliable. Inconsistent tagging, poor lineage, missing schema definitions, and unauthorized access make cost data hard to trust or reuse.
This is especially problematic in larger enterprises with hundreds of teams, cloud accounts, and toolchains. When everyone collects and processes billing data in their own way, shared accountability is impossible.
How Data Streaming with Apache Kafka and Flink Enable Real-Time, Governed FinOps
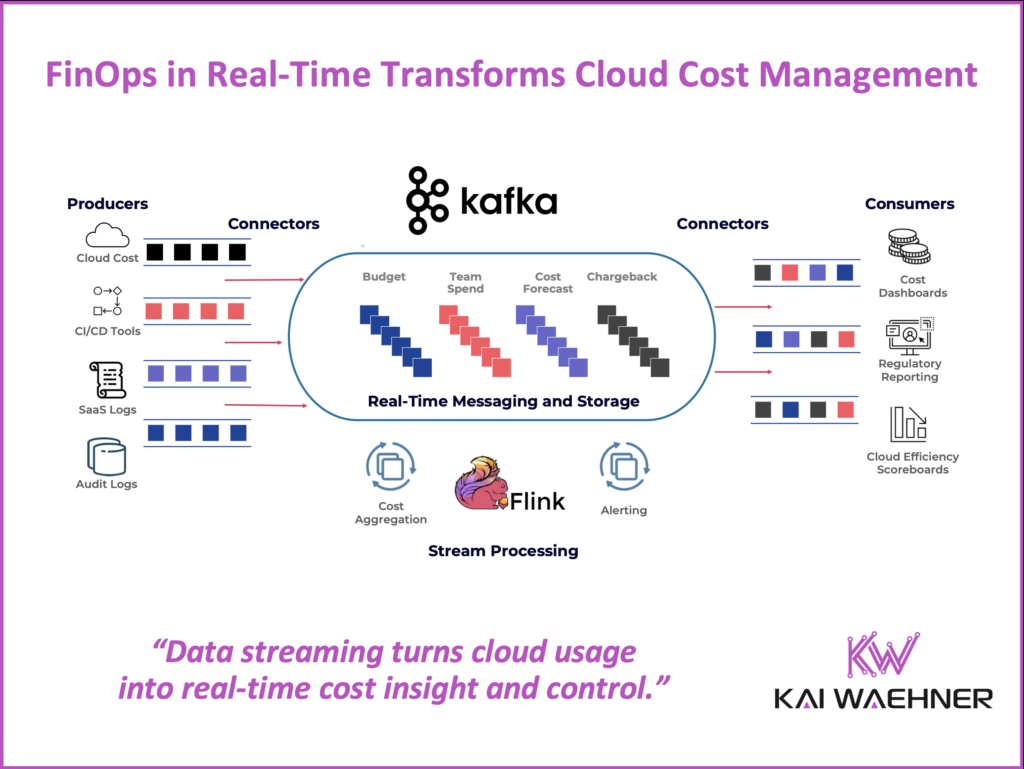
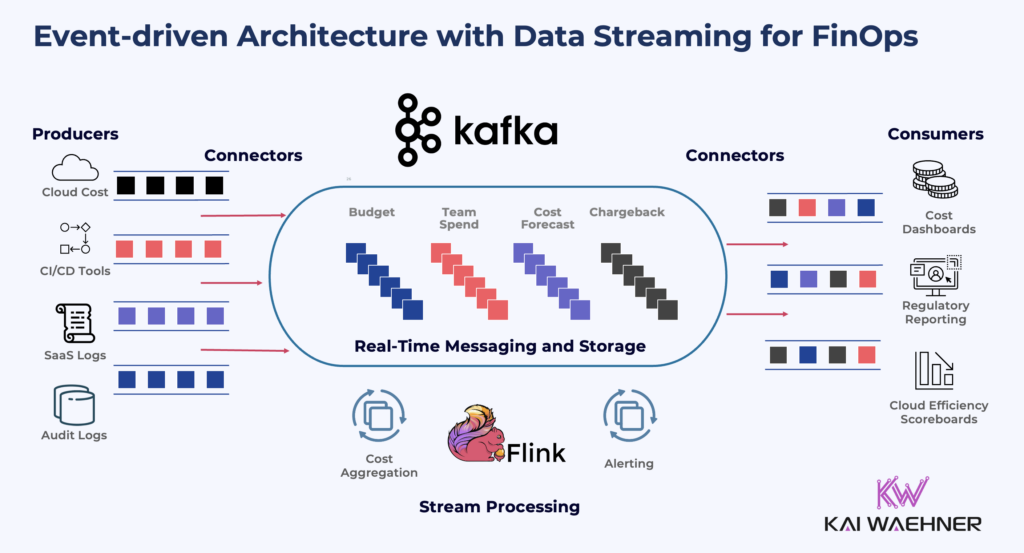
Data Streaming with Apache Kafka and Apache Flink provides the technical foundation for real-time, governed, and scalable FinOps architecture. A data streaming platform ingests data from sources like cloud billing APIs, Kubernetes, CI/CD tools, and identity systems. Stream processing apps continuously enrich and transform this data into reusable, trusted data products. These data products are consumed by dashboards, cost optimization tools, compliance systems, and finance apps. Each team gets accurate, real-time cost insights.
Apache Kafka for Real-Time Data Integration
Apache Kafka serves as the central nervous system for FinOps data. It ingests a continuous stream of cost and usage events from multiple sources:
- Cloud billing APIs like AWS Cost and Usage Report (CUR), Azure Cost Management, or GCP Billing Export
- Kubernetes metrics (via Prometheus exporters or Fluent Bit agents)
- Logs from CI/CD tools, infrastructure as code (IaC) pipelines, and provisioning systems
- Metadata from internal systems like CMDBs or user management platforms
Kafka Connect integrates with these systems through managed or custom connectors. Each billing or usage event is serialized (typically using Avro or JSON Schema), enriched with metadata (like cost center or service name), and published to Kafka topics.
Kafka’s distributed log architecture ensures durability, ordering, and replayability—critical for audit and traceability in financial operations. Its pub-sub model also allows multiple downstream systems to consume the same data independently, without building custom integrations.
This decoupling supports collaborative FinOps use cases. Finance teams use BI tools. Engineers monitor their own spend. Security teams enforce compliance. All use the same stream of data – but can still choose their favorite tools and SaaS products.
Apache Flink for Streaming Cost Analytics and Policy Enforcement
Apache Flink sits downstream of Kafka, providing low-latency stream processing and real-time analytics.
In FinOps, Flink is used to enrich and transform the raw data continuously:
- Aggregating spend by cloud service, team, or business unit
- Joining usage records with org hierarchies and budget data
- Calculating real-time deltas and usage trends
- Detecting anomalies based on thresholds or machine learning models
- Applying policies, such as blocking workloads that exceed budget caps
Flink supports windowing for time-based aggregations (e.g., cost per minute), stateful processing for tracking spend over time, and SQL or CEP (Complex Event Processing) for flexible rule definitions. Its low latency enables alerts and actions to be triggered within seconds of detecting a cost spike.
Processed records can be written back to Kafka topics, stored in analytical databases, or exposed to dashboards and APIs.
Data Governance and Compliance Through Self-Service Data Products
To support scalability and compliance, these cost insights need to be managed as data products. This means each Kafka topic or Flink output stream is documented, versioned, and schema-validated.
A Schema Registry ensures that each message conforms to a predefined data contract with structure, policies and rule constraints. This allows for safe evolution over time—adding new fields, changing logic, or migrating services—without breaking downstream consumers.
Access control is enforced through RBAC or ACLs. Metadata and lineage are stored alongside the data product definition. SLAs (Service Level Agreements) define availability and freshness expectations.
This approach turns real-time data into a governed asset that can be safely reused across the business—for reporting, alerts, billing, forecasting, and audits.
Learn more about data quality and policy enforcement within data streaming pipelines in the article “Policy Enforcement and Data Quality for Apache Kafka with Schema Registry“.
Bitvavo: Enabling GDPR-Compliant Crypto Trading Analytics at Millisecond Latency
Bitvavo, a cryptocurrency exchange in the EU, faced challenges managing its Kafka infrastructure while maintaining data security and regulatory compliance.
By migrating to Confluent Cloud, Bitvavo offloaded infrastructure management and gained access to fully managed, scalable Kafka clusters with built-in security and governance.

The company scaled its operations 10x, enabling real-time trading analytics, reducing latency to milliseconds, and improving customer experience. Encrypted, governed data streams ensured GDPR compliance while giving teams the agility to build new services.
This foundation enabled FinOps practices by giving teams real-time visibility into infrastructure usage and cost, all while meeting strict regulatory requirements.
“As we scaled our operations, we realized that managing data governance and providing real-time analytics were becoming more complex. We needed a platform that could handle large-scale data streams efficiently while maintaining the highest security standards,” said Marcos Maia, Senior Staff Engineer at Bivavo.
Read the full details in Confluent’s Bitvavo case study.
SumUp: Decentralized Data Ownership for Scalable Fintech Innovation
SumUp is a leading fintech company offering mobile point-of-sale solutions for small businesses. The company wanted to decentralize data ownership and improve team agility.
Traditional ETL pipelines created bottlenecks and delayed insights. With Confluent Cloud and Kafka, SumUp introduced an event-driven architecture based on data mesh principles. Real-time data streaming empowered over 20 teams to build their own data products.

This allowed rapid development of fraud detection, customer personalization, and internal cost dashboards—all using reusable, governed Kafka topics and Flink pipelines.
By shifting from central ETL to self-service streaming, SumUp accelerated innovation and improved decision-making across the organization.
This shift enabled teams to build FinOps tools like real-time cost dashboards and chargeback models, making cloud spending more transparent, accountable, and aligned with business goals.
Explore more in the SumUp case study from Confluent.
FinOps and Data Streaming: A New Era of Cloud Cost Management
FinOps is not just about cutting cloud bills—it’s about aligning technical and financial decisions in real time. Data Streaming with Apache Kafka and Flink makes this possible by turning raw usage data into structured, governed, and actionable insights.
With real-time data streaming:
- Engineers can see the financial impact of their code within seconds
- Finance teams can track budgets with precision
- Compliance becomes proactive instead of reactive
Most importantly, the business gains the confidence to scale without losing control. In the age of cloud-native architectures, this is no longer optional—it’s foundational.
For organizations serious about cloud efficiency and operational maturity, Kafka and Flink aren’t just tools—they are enablers of modern FinOps at scale.
If you want to learn more about data streaming, explore “How Apache Kafka and Flink Drive the Top 10 Innovations in FinServ“.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases. It features multiple use cases across financial services.
