I had a new talk presented at “Codemotion Amsterdam 2018” this week. I discussed the relation of Apache Kafka and Machine Learning to build a Machine Learning infrastructure for extreme scale.
Long version of the title:
“Deep Learning at Extreme Scale (in the Cloud) with the Apache Kafka Open Source Ecosystem – How to Build a Machine Learning Infrastructure with Kafka, Connect, Streams, KSQL, etc.”
As always, I want to share the slide deck. The talk was also recorded. I will share the video as soon as it was published by the organizer.
The room was full. No free seats. A lot of interest in this topic. I talked to many attendees who have huge challenges bringing analytic models into mission-critical production. No scalability and missing flexibility were other challenges many people had when using e.g. just a Python environment to build an analytic model.
Apache Kafka as Key Component in a Machine Learning Infrastructure
The open source Apache Kafka ecosystem helps in many situations of a machine learning process. Data integration, data ingestion, data preprocessing, model deployment, monitoring, etc. Many companies have built a Kafka ML infrastructure already. Take a look at tech giants like Netflix with Meson or Uber with Michelangelo to mention two examples.
Tech giants and many other companies use Apache Kafka at very large scale already. So you do not need to worry about this. You just need to evaluate how you integrate it into your existing environment and projects. See the example from LinkedIn (> 4.5 Trillion messages per day) or Netflix (peak of 6 Petabyte per day):

Machine Learning and Apache Kafka are both part of their core infrastructure. I see similar scenarios at most traditional companies (like banks, telcos, retailer) these days. They all build a central nervous system around Apache Kafka and apply analytic models in several scenarios and business processes.
Abstract of the Talk: Machine Learning and Deep Learning with Apache Kafka
This talk shows how to build Machine Learning models at extreme scale and how to productionize the built models in mission-critical real time applications by leveraging open source components in the public cloud. The session discusses the relation between TensorFlow and the Apache Kafka ecosystem – and why this is a great fit for machine learning at extreme scale.
The Machine Learning architecture includes: Kafka Connect for continuous high volume data ingestion into the public cloud, TensorFlow leveraging Deep Learning algorithms to build an analytic model on powerful GPUs, Kafka Streams for model deployment and inference in real time, and KSQL for real time analytics of predictions, alerts and model accuracy.
Sensor analytics for predictive alerting in real time is used as real world example from Internet of Things scenarios. A live demo shows the out-of-the-box integration and dynamic scalability of these components on Google Cloud.
Machine Learning Infrastructure based on the Apache Kafka and Confluent open source ecosystem:
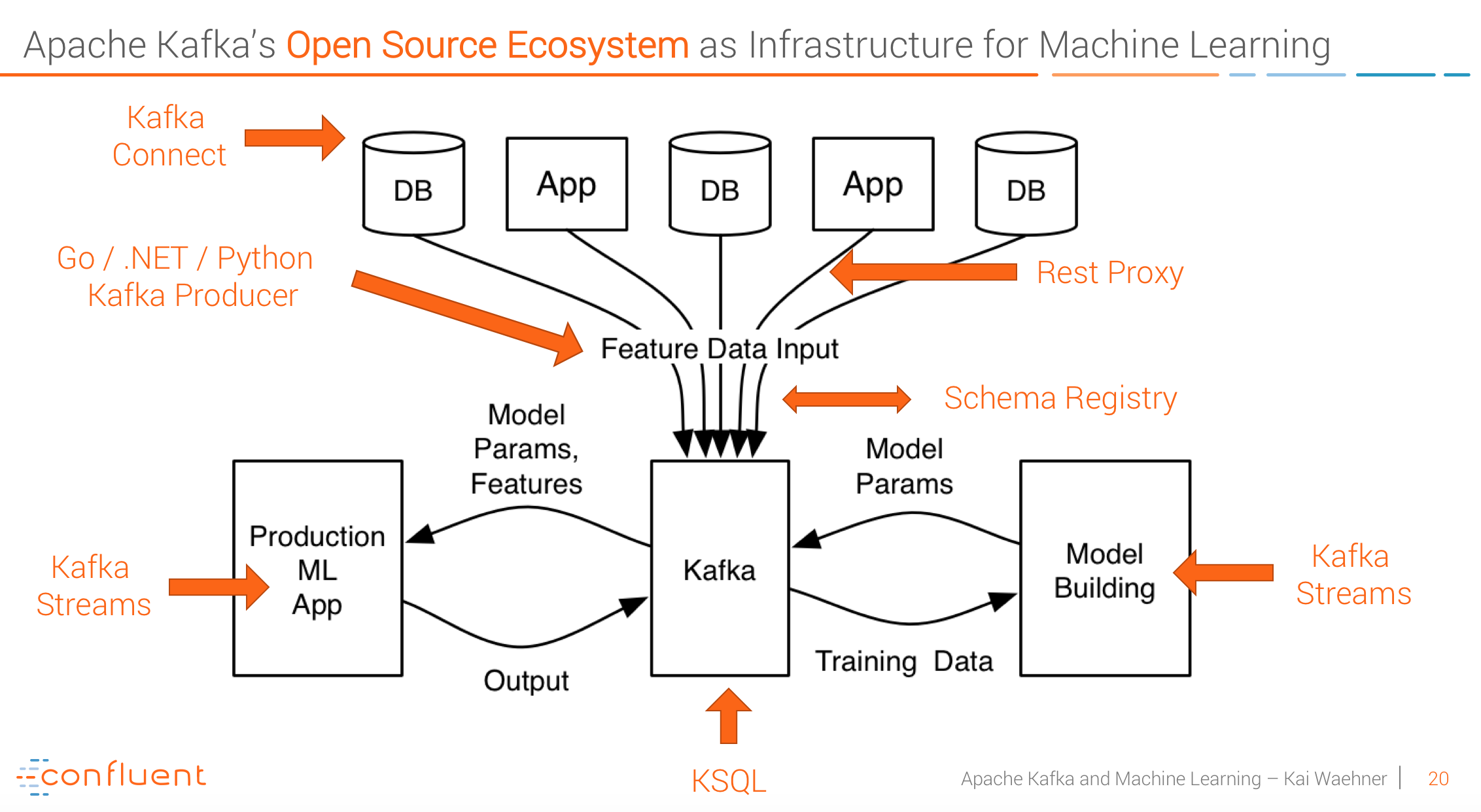
Key takeaways for the audience
- Data Scientist and Developers have to work together continuously (org + tech!)
- Mission critical, scalable production infrastructure is key for success of Machine Learning projects
- Apache Kafka Ecosystem + Cloud = Machine Learning at Extreme Scale (Ingestion, Processing, Training, Inference, Monitoring)
Slide Deck: Apache Kafka + Machine Learning at Extreme Scale
Here is the slide deck of my talk:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
As always, I appreciate any feedback.





