
The following question comes up almost every week in conversations with customers: Can and should I deploy Apache Kafka at the edge? Or should I just deploy Kafka in a “real” data center or public cloud infrastructure? I am glad that people ask because it is a valid question in various industries, including manufacturing, automation industry, aviation, logistics, and retailing. This blog post explains why Apache Kafka is the New Black at the Edge in Internet of Things (IoT) projects. I cover use cases and different architectures. The last section discusses how Kafka as event streaming platform complements other IoT frameworks and products at the edge for data integration and edge processing in real time at scale.
Multiple Kafka Clusters Became the Norm, not an Exception!
Multi-cluster and cross-data center deployments of Apache Kafka have become the norm rather than an exception. A Kafka deployment at the edge can be an independent project. However, in most cases, Kafka at the edge is part of an overall Kafka architecture.
Many reasons exist to create more than just one Kafka cluster in your organization:
- Independent Projects
- Hybrid integration
- Edge computing
- Aggregation
- Migration
- Disaster recovery
- Global infrastructure (regional or even cross continent communication)
- Cross-company communication
This blog post focuses on the deployment of Apache Kafka at the edge. The relation to all the other kinds of Kafka architectures will be discussed in February 2020 at DevNexus in Atlanta. There, I will explain in detail the “architecture patterns for distributed, hybrid and global Apache Kafka deployments“. I will share the slides and a video recording in another blog post after the conference.
Before we think about running Kafka at the edge, we need to define the term “edge”.
What is “The Edge” or “Edge Computing”?
Wikipedia says “edge computing is a distributed computing paradigm which brings computation and data storage closer to the location where it is needed, to improve response times and save bandwidth”. Other benefits include add cost reduction, flexible architecture and separation of concerns.
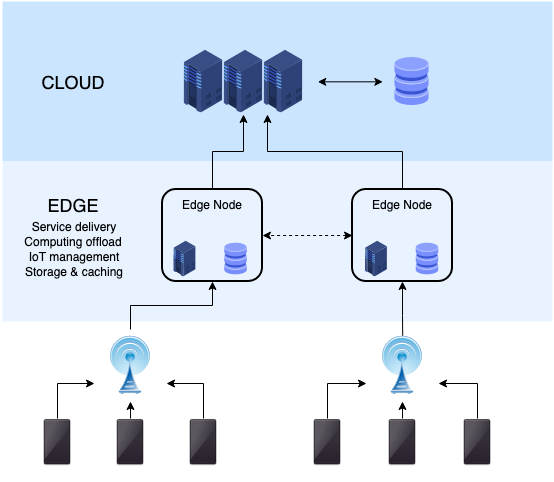
Apache Kafka at the Edge
Different options exist to discuss “Kafka for edge computing”:
- Only Clients at the Edge: Kafka Clients running at the edge. Kafka Cluster deployed in a Data Center or Public Cloud environment.
- Everything at the Edge: Kafka Cluster and Kafka Clients (e.g. sensors in the factory) deployed at the edge.
- Edge and Beyond: Kafka Cluster deployed at the edge. Kafka Clients (e.g. smartphones in the region) running close to the edge.
Therefore, the range of “Kafka at the Edge” is gigantic:
- Edge in an IIoT shop floor could be a Kafka Client written in C and deployed to a microcontroller in a sensor. Such a sensor typically has just a few kilobyte of memory. It lives for a defined time span before it dies and gets replaced.
- Edge in telco business could be a full distributed Kafka cluster running on StarlingX. This is an open source private cloud infrastructure software stack based on Kubernetes for the edge used by the most demanding applications in industrial IoT, telecom, video delivery and other ultra-low latency use cases. The hardware requirements for such an edge deployment are higher than what some teams in a traditional bank or insurance company get after waiting six months for management approvals.
- In most cases, edge is somewhere in the middle of the two extreme scenarios described above.
In most scenarios, “Kafka at the edge” means the deployment of a Kafka cluster on site at the edge. The Kafka Clients are either running on site or close to the site (“close” could be several miles away in some cases). Sometimes, the edge site is offline and disconnected from the cloud regularly. This is my definition for this blog post, too. Just make sure to define what you mean with the term “edge” in your conversations with colleagues and customers.
Now let’s think about use cases for running Kafka at the edge.
Use Cases for Kafka at the Edge
Use cases for Kafka deployments at the edge exist in various industries. No matter if “your things” are smartphones, machines in the shop floor, sensors, cars, robots, cash point machines, or anything else.
Let’s take a look at a few examples of what I have seen in 2019 in many different enterprises:
- Industrial IoT (IIoT): Edge integration and processing in real time are key for success in modern IoT architectures. Various use cases exist for Industry 4.0, including predictive maintenance, quality insurance, process optimization and cyber security. Building a Digital Twin with Kafka is one of the most frequent scenarios and a perfect fit for many use cases.
- Retailing: The digital transformation enables many new, innovative use cases, including customer 360 experiences, cross-selling and collaboration with partner vendors. This is relevant for any kind of retailer. No matter if you think about retail stores like Walmart, coffee shops like Starbucks, or cutting-edge shops like the Amazon Go store.
- Logistics: Correlation of data in real time at scale is a game changer for any logistics scenario: Track and trace end-to-end for package delivery, communication between delivery drones (or humans using cars) and the local self-service collection booths, accelerated processing in the logistics center, coordination and planning of car sharing / ride sharing, traffic light management in a smart city, and so on.
Kafka at the Edge – High Level Architecture
No matter which use case you want to implement: The architecture for Apache Kafka at the edge typically looks more or less like the following (on a very high level):
Why and How does Kafka help at the Edge?
The ideas and use cases discussed above are nothing new. But think about your favorite consumer application, retailer or coffee shop: How many enterprises have already rolled out real time applications for context-specific push messages, customer experience or other services at scale in a reliable way?
Honestly, not many. Only some tech companies like Uber and Lyft did a great job. Though, these companies could start on the green field a few years ago. Not really surprisingly, all the tech companies use the event streaming platform Kafka as the heart of their real time infrastructure.
But the situation gets better and better these days. More and more traditional enterprises already rolled out an event streaming platform in their data centers or in the cloud to process data in real time at scale to build innovative applications.
Challenges at the Edge
However, enterprises often have challenges to bring these innovative real time applications into scenarios where data is distributed in local sites, like factories, retail stores, coffee shops, etc.
Challenges include:
- Integration with all the hardware, machines, devices at the edge is hard due to bad network and many other limitations
- Processing at scale and in real time is mandatory for many use cases. Thus, processing should happen on site, not in a remote data center or cloud (often hundreds of miles away).
- Various technologies and protocols have to be integrated at the edge. Often, legacy and proprietary protocols need to communicate with modern big data tools on the other side of the tunnel.
- Limited hardware resources and human expertise at the edge. IT experts cannot go on site to every location. Teams cannot spend a lot of money on hardware and operations continuously in every site.
Data has to be stored and processed locally on site in real time at scale. Plus, data needs to be replicated to the data center or cloud to do further processing and analytics with the aggregated data from different sites. In best case, communication is bidirectional so that smaller local sites can be controlled from one single point by sending commands and control events back to the local sites.
The Same Infrastructure and Technology at the Edge and in the Data Center / Cloud
The implementation of edge use cases is a lot of efforts. Rolling out the solution to all the sites is another big challenge. Ideally, enterprises can leverage the same infrastructure, technologies and applications BOTH on site at the edge in factories or stores AND in the big data center or cloud.
This is why Apache Kafka comes into play in more and more edge scenarios: Leverage the same infrastructure, technologies and applications everywhere. Real time stream processing, reliability and flexible scalability are core features of Kafka. This allows large scale scenarios in the cloud and small or medium scale scenarios at the edge.
Let’s take a loot at different options for deploying Kafka at the edge.
Kafka Architectures for Edge Computing
The key question you have to ask yourself: Do I need high availability at the edge?
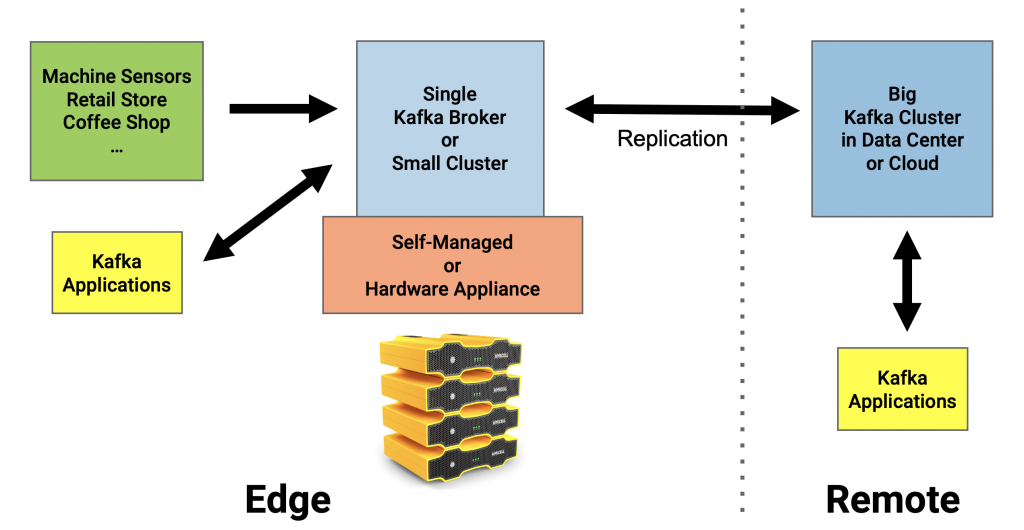
Edge Computing does not always require high availability. If it does, then you deploy a traditional Kafka cluster. If it does not, then you choose the simple and less costly option with just one single Kafka broker at the edge. A hardware appliance could make this even easier for roll out in tens or hundreds of sites.
The following example shows three edge sites. One Kafka cluster is deployed at each site including additional Kafka components:
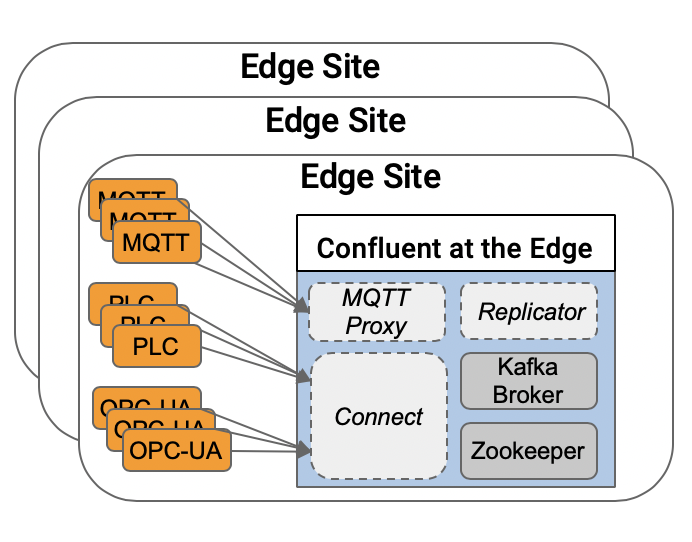
Resilient Deployment at the Edge with 3+ Kafka Brokers
Kafka and its ecosystem are build for high availability and zero downtime (even if individual nodes fail). Usually, you deploy a distributed system. Kafka and Zookeeper required at least three nodes. Other components require at least two nodes to guarantee robust operations without data loss:
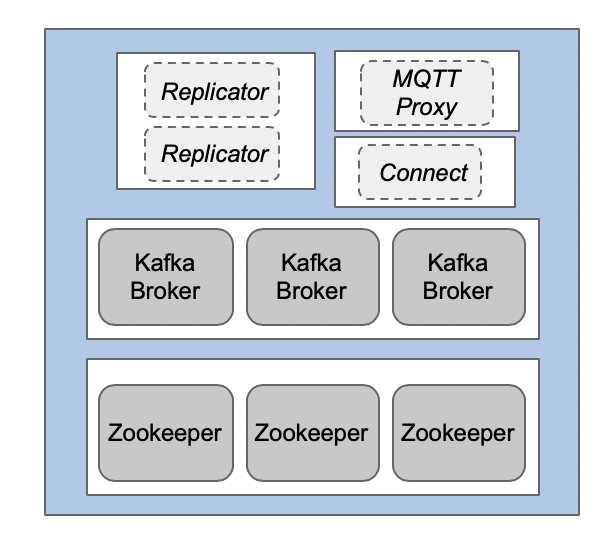
Check out the Apache Kafka and Confluent Platform Reference Architecture for more details about deployment best practices. These best practices do not change at the edge. Having said this, the load and throughput is often lower at the edge. Therefore, less memory and smaller disks are often sufficient. It all depends on your SLAs, requirements and use cases.
Non-Resilient Deployment at the Edge with One Single Kafka Broker
The demand to deploy a “lightweight Kafka cluster” at the edge and synchronize / replicate data with a bigger central Kafka cluster comes up more and more. Due to hardware limitations or lower SLAs regarding high availability, the deployment of just one single Kafka broker (plus one Zookeeper) at the edge is totally fine. You can even deploy the whole Kafka environment on one single server:
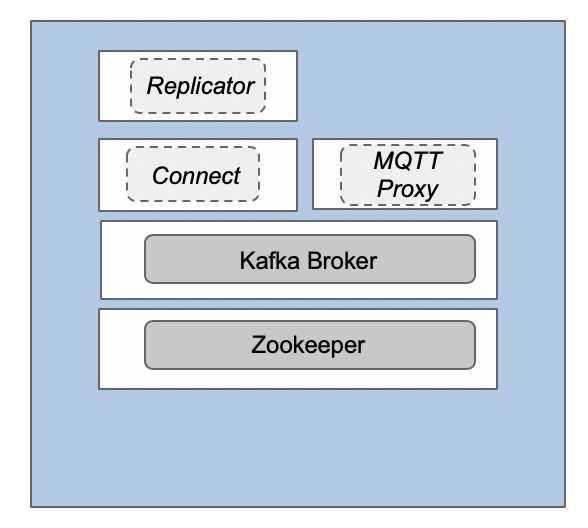
This creates some obvious drawbacks: No replication, downtime in case of failure of the node or network, risk of data loss. However, a single-node Kafka deployment works and still provides many benefits of the Kafka fundamentals:
- Decoupling between producers and consumers
- Handling of back-pressure
- High volume real time processing (even one broker has a lot of power)
- Storage on disks
- Ability to reprocess data
- All Kafka-native components available (Kafka Connect for integration, Kafka Streams or ksqlDB for stream processing, Schema Registry for governance).
TL;DR: A Single-Broker Kafka deployment works well. Just be aware of the drawbacks and doublecheck if this is okay for your SLAs and requirements.
ZooKeeper Removal – A Great Help for Kafka at the Edge
Kafka is a powerful distributed infrastructure. Hence, Kafka is not the easiest piece of infrastructure to operate. A key reason is the dependency to ZooKeeper (the same is true for many other distributed systems like Hadoop or Spark). I won’t go into details about the challenges and problems with ZooKeeper here. There is enough information on the web. TL;DR: ZooKeeper makes Kafka harder to operate and less scalable. Many P1 and P2 support tickets are not about Kafka but about ZooKeeper (not because ZooKeeper is unstable, but because it is hard to operate).
The good news: Kafka will get rid of ZooKeeper in the next few releases. Check out “KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum” for more details. KIP-500 will make Kafka much more lightweight, scalable, elastic and simple to operate. This is relevant BOTH at extreme scale in the cloud AND in small single-broker deployments at the edge.
As most IoT projects do not plan just one year ahead, but being rolled out to different sites over five and more years, remember that Kafka will be much easier and more lightweight without ZooKeeper in ~1 year from now.
Kafka as Gateway between Edge Devices and Cloud
A Kafka gateway is an additional optional component in the architecture. In some configurations you might want the edges devices to communicate with a local gateway on premise.
As example, in an industry plant, you might see multiple machines or production lines as edge devices. They integrate with their own Kafka cluster and send this data to a gateway Kafka cluster. At the gateway Kafka cluster, you can do some analytics directly on premise, and maybe filter the data or transform it, before sending it to a large remote aggregation Kafka cluster:
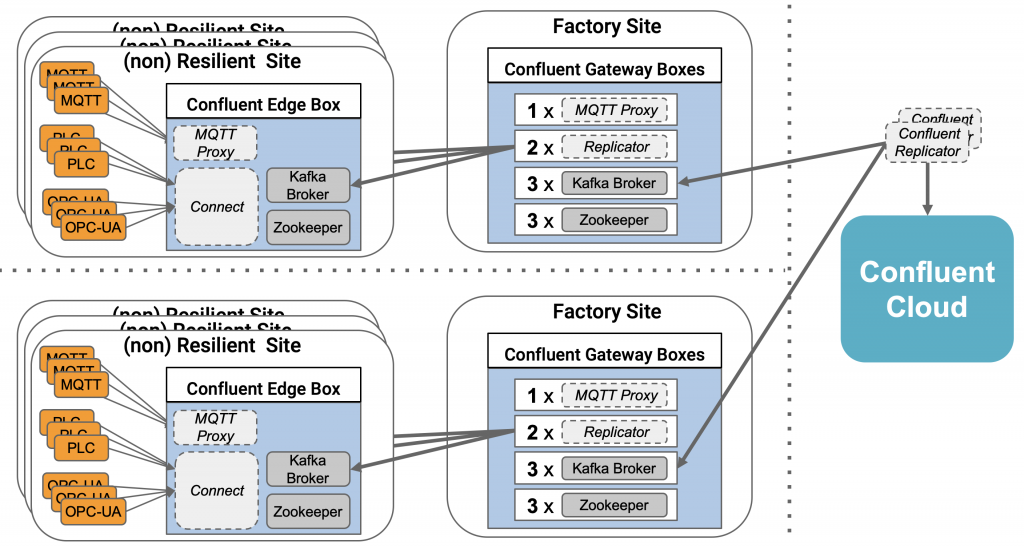
In the above example, we have two independent factories. Both use non-resilient single-broker Kafka deployments for local processing. A resilient gateway Kafka cluster with three Kafka brokers aggregates and processes the data locally in the factory. Only the important and pre-processed data is forwarded to a remote Kafka cluster; in this case Confluent Cloud. The Kafka cluster in the cloud aggregates the data from different factories to integrate with other business applications or analytics tools.
Kafka at the Edge as OEM or in Hardware Appliances
At the edge, enterprises do not have the capabilities and possibilities like in their data centers or in the public cloud. Installing hardware is a huge challenge. Operations is even harder. A standardized way of installing Kafka components at the edge reduces the efforts and risks.
Tens of hardware vendors are available to build your own OEM or hardware appliance. Or you just pick a ready-to-ship box and install all required software components with some DevOps tools via remote management.
Plenty of options exist to ease installation and operations of a Kafka cluster at the edge. Hivecell is one interesting example which you could use. “Hivecell enables companies to deploy and maintain software at the edge without an army of technicians” is the slogan of this startup. You just ship one or more boxes to the site, connect it to the local WiFi and everything else can be done remotely. The Hivecell boxes be shipped in a pre-configured way. For instance, the hardware could already have installed Kubernetes, the Kafka ecosystem and other business applications. Tooling like Confluent Operator can run on the boxes to ease and automate operations of the Kafka environment at the edge. This way, remote management is typically sufficient.
Communication, Connectivity, Integration, Data Processing
As already shown in the diagrams above, a Kafka environment includes more than just the Kafka broker and mandatory Zookeeper. Communication, connectivity, integration and data processing are important components in a Kafka infrastructure, no matter if in the cloud, on premise or at the edge:
Communication between Kafka Brokers and Kafka Clients:
- Edge-Only: Device -> Kafka at the edge -> Device
- Edge-to-Remote: Device -> Kafka at the edge -> Replication -> Kafka (Data Center / Cloud) -> Analytics / Real Time Processing
- Bidirectional: A combination of 1) and 2) for bidirectional communication between the edge and remote Kafka cluster
Kafka-native Connectivity, Integration, Data Processing:
Kafka-native components leverage Kafka under the hood. This way, you have to manage just one platform for communication, integration and processing of data in real time at scale:
- Kafka Connect: MQTT, OPC-UA, FTP, CSV, PLC4X (Legacy and proprietary IIoT protocols and PLCs like Modbus, Siemens S7, Beckhoff, Allen Bradley), etc.
- Mirrormaker 2 / Confluent Replicator: Uni- or Bidirectional replication between two Kafka Clusters
- Kafka Clients (Producers / Consumers): Java, Python, C++, C, Go, Javascript, …
- Data Processing: Stream Processing (stateless streaming ETL or stateful applications) with Kafka Streams or ksqlDB
- Proxies: REST Proxy for HTTP(S) communication, MQTT Proxy for MQTT integration
- Schema Registry: Governance and schema enforcement.
Make sure to plan the whole infrastructure from the beginning. Especially at the edge where you typically have limited hardware resources… Doublecheck if you really need another database or external processing framework! Maybe the Kafka stack is good enough for your needs?
Kafka is NOT an IoT framework
Kafka can be used in very different scenarios. It is best for event streaming at scale and building a reliable and open infrastructure to integrate IoT at the edge and the rest of the enterprise.
However, Kafka is not the silver bullet for every problem. A specific IoT product might be the better choice for integration and processing of IoT interfaces and shop floors. This depends on the specific requirements, existing ecosystem and already used software. Complexity and cost of solutions need to be evaluated. “Build vs. buy” is always a valid question. Often, the best choice and solution is a mix of building an open, flexible, self-built central streaming infrastructure and buying COTS for specific edge integration and processing scenarios.
Hybrid Architecture – When and Why to use Additional IoT Frameworks and Products?
You should always ask yourself: Is Kafka alone sufficient? If yes, why use an additional framework or product? End-to-End integration gets harder with each additional technology. 24/7 deployments, zero data loss, and real time processing without latency spikes are requirements Kafka works best for.
If Kafka is not sufficient alone, combine it with another IoT framework or solution:
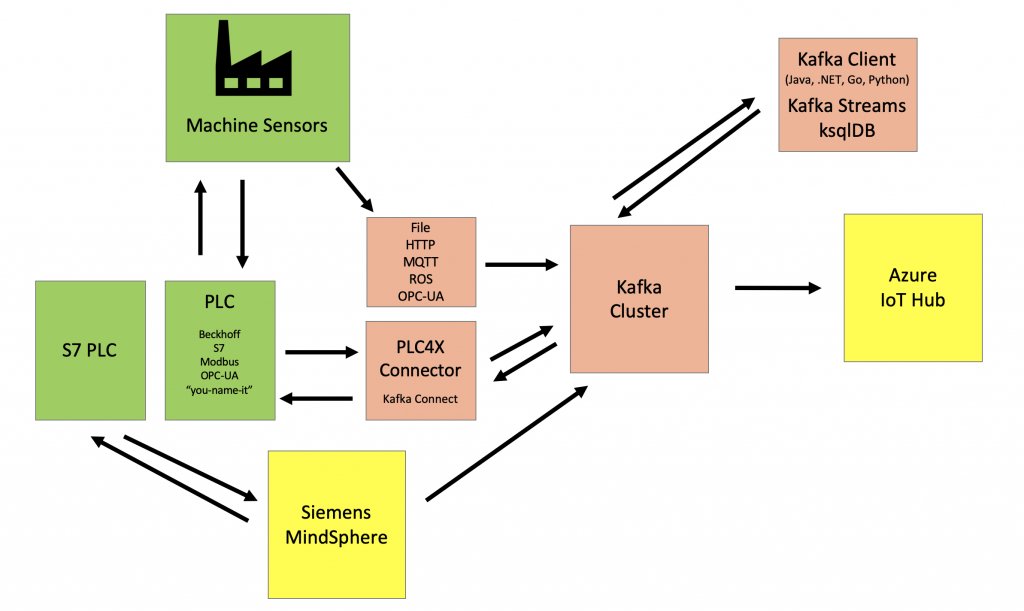
Sometimes, the shop floor connects to an IoT solution. The IoT solution is used as gateway or proxy. This can be a broad, powerful (but also more complex and expensive) solution like Siemens MindSphere. Or the choice is to deploy “just” a specific solution, more lightweight solution to solve one problem. For instance, HiveMQ could be deployed as scalable MQTT cluster to connect to machines and devices. This IoT gateway or proxy connects to Kafka. Kafka is either deployed in the same infrastructure or in another data center or cloud. The Kafka cluster connects to the rest of the enterprise.
In other scenarios, Kafka is used as IoT gateway or proxy to connect to the PLCs or Distributed Control System (DCS) directly. Kafka then connects to an IoT Solution like AWS IoT or Google Cloud’s MQTT Bridge where further processing and analytics happen.
Communication is often bidirectional. No matter what architecture you choose: The data is ingested from the shop floor or other IoT devices, processed and correlated in real time, and finally control events are sent back to the machines. For instance, in predictive analytics, you first train analytic models with tools like TensorFlow in the cloud. Then you deploy the analytic model at the edge for real time predictions.
Do you really need NiFi / MiNiFi or an ESB / ETL Tool?
I just explained why you might combine Kafka with other IoT frameworks or solutions. These are very complementary to the Kafka ecosystem and focus on different use cases like device management, training an analytic model, reporting or building a digital twin.
For example, the major cloud providers provide IoT services for device management, proxies to their own cloud services, and analytics tools. At the edge, Eclipse IoT alone provides various different IoT frameworks. For instance, Eclipse ditto is a great open source framework for building a digital twin.
For integration problems, I think differently!
24/7 Uptime and Zero Data Loss Required?
This is a long discussion, but TL;DR: Most integration projects have critical SLAs. The infrastructure has to run 24/7 without downtime and without data loss. The more middleware components combined, the harder it gets to ensure your SLAs and requirements. If you can run Kafka infrastructure 99.95, for each additional middleware components you combine with it, the end-to-end availability goes down. Additionally, you have to develop, test, operate and pay for two or more middleware components instead of just focusing on one single infrastructure.
SLAs Important? Kafka Eats its Own Dog Food
This is one of the key benefits of Kafka; Kafka eats its own dog food: All components leverage the Kafka protocol and its features like offsets, replication, consumer groups, etc. under the hood:
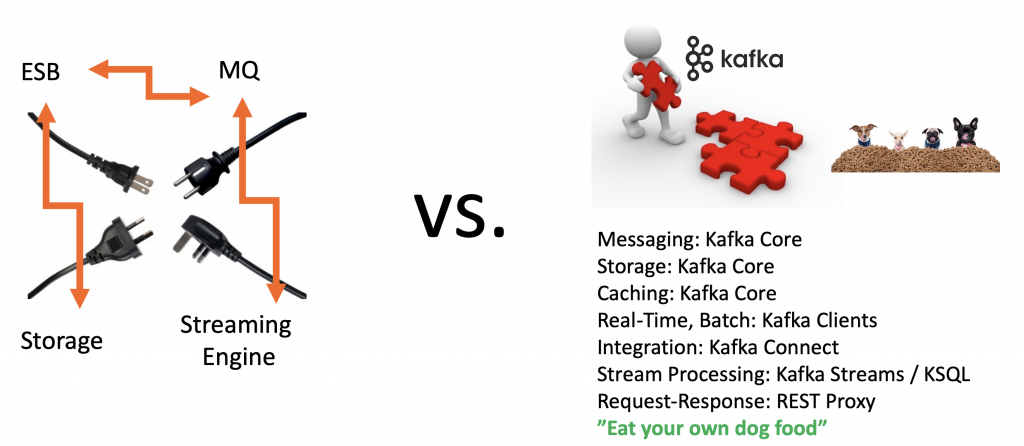
I see the added value of tools like Apache NiFi or Node-RED: You have a drag&drop UI to build pipelines. This is really nice! If you just have to built a pipeline to send data from the edge to the data lake for reporting and analytics, Nifi et al are great tools – if you can live with the risk of downtime and data loss!
Kafka + NiFi + XYZ = Too Many Distributed Systems to Operate!
If you have to built a scalable, reliable streaming infrastructure for edge computing and hybrid architecture without downtime and without data loss: Trust me, you will have a lot of pain. I have seen many deployments where end-to-end integration combining different middleware tools did not go through the integration tests. The idea looks nice in the beginning, but is not robust enough for mission-critical scenarios.
Think about it again: The more tools you combine with each other, the higher the risk for an outage or data loss! NiFi, as one example, runs its own distributed infrastructure. This means you have to guarantee 24/7 end-to-end uptime from the producers via NiFi and Kafka to the final consumer. Kafka-native tools like Kafka Connect or Kafka Streams use Kafka topics (including all the high availability features of Kafka) under the hood. This means you have to operate just one single infrastructure in 24/7 mode to guarantee end-to-end integration without downtime and without data loss.
My heart aches when I see architecture recommendations where you have pipelines like “Sensor ABC -> NiFi (Ingestion) -> Kafka Topic A -> NiFi (Transformation) -> Kafka Topic B -> NiFi (Load) -> Application XYZ”. Again, this is fine for batch ETL pipelines and I see the added value of a nice UI tool like NiFi. But this is NOT the right way to build a 24/7 infrastructure for real time processing at scale with zero data loss.
I have a lot of material to learn the differences between an event-driven streaming platform like Apache Kafka and middleware like NiFi, Node-RED, Message Queues (MQ), Extract-Transform-Load (ETL) and Enterprise Service Bus (ESB).
Kafka at the Edge to Consolidate the Hybrid IoT Architecture
“Kafka at the edge” is the new black. Many industries deploy Kafka in hybrid architectures. Edge computing allows innovative use cases, increases processing speed, reduces network cost and makes the overall infrastructure more scalable, reliable and robust.
Start small, roll out Kafka at the edge in one site, connect it to the remote Kafka cluster. Then, connect more and more sites step-by-step or build bidirectional use cases.
Edge computing is just a part of the overall architecture. It is okay to deploy just one single Kafka broker in small sites like a coffee shop, retail store or small plant. A “real Kafka cluster” has to be deployed on site to ensure mission-critical use cases. Local processing allows mission-critical processing in real time at scale without the need for remote communication. This reduces costs and increases security.
However, added value often comes from combining the data from different sites to use it for real time decisions. IoT Kafka infrastructures often combine small edge deployments with bigger Kafka deployments in the data center or public cloud. In the meantime, you can even run a single Apache Kafka cluster across multiple datacenters to build regional and global Kafka infrastructures – and connect these to the local edge Kafka clusters.
What are your thoughts about Kafka at the edge and in hybrid architectures? Please let me know. Also, check out the “Infrastructure Checklist for Apache Kafka at the Edge” if you plan to go that direction!
Let’s connect on LinkedIn and discuss your use cases, architectures, and requirements. Also, stay informed about new blog posts by subscribing to my newsletter.
