
Event streaming with Apache Kafka at the edge is getting more and more traction these days. It is a common approach to providing the same open, flexible, and scalable architecture in the cloud and at the edge outside the data center. Possible locations for Kafka edge deployments include retail stores, cell towers, trains, small factories, restaurants, hospitals, stadiums, etc. This post explores a checklist with infrastructure questions you need to check and evaluate if you want to deploy Kafka at the edge.

Apache Kafka at the Edge == Outside the Data Center
I already discussed the concepts and architectures of Kafka at the edge in detail in the past:
- Apache Kafka is the New Black at the Edge
- Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments
- Use Cases for Kafka at the Edge
- Kafka at the Edge in a Smart Factory with a Private 5G Campus Network
- A Hybrid Streaming Architecture for Smart Retail Stores with Apache Kafka
This blog post explores a checklist of common infrastructure questions you need to answer and doublecheck before planning to deploy Kafka at the edge.
What is the Edge?
The term ‘edge’ needs to be defined to have the same understanding. When I talk about the edge in the context of Kafka, it means:
- Edge is NOT a data center, i.e., limited compute, storage, network bandwidth
- Kafka clients AND the Kafka broker(s) deployed here, not just the client applications
- Offline business continuity, i.e., the workloads continue to work even if there is no connection to the cloud
- Often 100+ locations, like restaurants, coffee shops, or retail stores, or even embedded into 1000s of devices or machines
- Low-footprint and low-touch, i.e., Kafka can run as a normal highly available cluster or as a single broker (no cluster, no high availability); often shipped “as a preconfigured box” in OEM hardware (e.g., Hivecell)
- Hybrid integration, i.e., most use cases require uni- or bidirectional communication with a remote Kafka cluster in a data center or the cloud
Let’s recap one architecture example that deploys Kafka in the cloud and at the edge: A hybrid event streaming architecture for real-time omnichannel retail and customer 360:
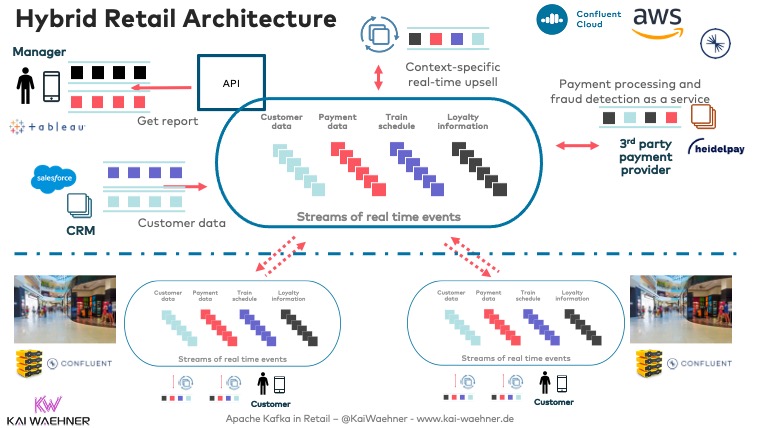
This definition of a ‘Kafka edge deployment‘ can also be summarized as an ‘autonomous edge‘ or ‘disconnected edge‘. On the other side, the ‘connected edge’ means that Kafka clients at the edge connect directly to a remote data center or cloud.
Infrastructure Checklist: How to Deploy Apache Kafka at the Edge?
I talked to 100+ customers and prospects across industries with the need to do edge computing for different reasons, including bad internet connection, reduced cost, low latency requirements, and security implications.
The following discussion points and questions come up all the time. Make sure to discuss them with your project team:
-
What are the use cases for Kafka at the edge? For instance, edge processing (e.g., business logic/analytics), replication to the cloud (uni- or bi-directional), data integration (e.g., 0 to devices, IoT gateways, local databases)?
-
What is the data model, and what the replication scenarios and SLAs (aggregation to “just gather data”, command&control to send data back to the edge, local analytics, etc.)? Check out Kafka-native replication tools, especially MirrorMaker 2 and Confluent’s Cluster Linking.
-
What is the main motivation for doing edge processing (vs. ingestion into a DC/cloud for all processing)? Examples: Low latency requirements, cost-efficiency, business continuity even when offline / disconnected from the cloud, etc.
-
How many “edge sites” do you plan to deploy to (e.g., retail stores, factories, restaurants, trains, …)? This needs to be considered from the beginning. If you want to roll out edge computing to thousands of restaurants, you need a different hardware and automation strategy than deploying to just ten smart factories worldwide.
-
What hardware do you use at the edge (e.g., hardware specifications)? How much memory, disk, CPU, etc., is available? Do you work with a specific hardware vendor? What are the support model and monitoring setup for the edge computers?
-
What network do you use? Is it stable? What is the connection to the cloud? If it is a stable connection (like AWS DirectConnect or Azure ExpressRoute), do you still need Kafka at the edge?
-
What is the infrastructure you plan to run Kafka on at the edge (e.g., operating system, container, Kubernetes, etc.)?
-
Do you need high availability and a ‘real’ Kafka cluster with 3+ brokers? Or is a single broker good enough? In many cases, the latter is good enough to decouple edge and cloud, handle backpressure, and enable business continuity even if the internet connection is gone for some time.
-
What edge protocols do you need to integrate with? is Kafka Connect sufficient with its connectors, or do you need a 3rd party IoT gateway? Common integration points at the edge are OPC UA, MQTT, proprietary PLC, traditional relational databases, files, IoT Gateways, etc.
- Do you need to process the data at the edge? Kafka-native stream processing with Kafka Streams or ksqlDB is usually a straightforward and lightweight, but still scalable and reliable option. Almost all use cases I have seen at least need some streaming ETL at the edge. For instance, preprocess and filter data so that you only send relevant, aggregated data over the network to the cloud. However, many customers also deploy business applications at the edge, for instance, for real-time model inference.
- How will fleet management work? Which part of the infrastructure or tool handles the management and operations of the edge machines. In most cases, this is not specific for Kafka but instead handled on the infrastructure level. For instance, if you run a Kubernetes cluster, Rancher might be used to provision and manage the edge clusters, including the Kafka ecosystem. Of course, specific Kafka metrics are also integrated here, for instance via Prometheus if you are using Kubernetes.
Discussing and answering these questions will help you with your planning for Kafka at the edge. Are there any key questions missing? Please let me know and I will update the list.
Kafka at the Edge is the new Black!
Apache Kafka at the edge is a common approach to providing the same open, flexible, and scalable architecture in the cloud and outside the data center. A huge benefit is that the same technology and architecture and be deployed everywhere across regions, sites, and clouds. This is a real hybrid architecture combing edge sites, data centers, and multiple clouds! Discuss the above infrastructure checklist with your team to be successful.
What are your experiences and plans for event streaming with Apache Kafka at the edge? Did you already deploy Apache Kafka on a small node somewhere, maybe even as a single broker setup? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





