
This blog post discusses the benefits of a Digital Twin in Industrial IoT (IIoT) and its relation to Apache Kafka. Kafka is often used as central event streaming platform to build a scalable and reliable digital twin for real time streaming sensor data.
In November 2019, I attended the SPS Conference in Nuremberg. This is one of the most important events about Industrial IoT (IIoT). Vendors and attendees from all over the world fly in to make business and discuss new products. Hotel prices in this region go up from usually 80-100€ to over 300€ per night. Germany is still known for its excellent engineering and manufacturing industry. German companies drive a lot of innovation and standardization around Internet of Things (IoT) and Industry 4.0.
The article discusses:
- The relation between Operational Technology (OT) and Information Technology (IT)
- The advantages and architecture of an open event streaming platform for edge and global IIoT infrastructures
- Examples and use cases for Digital Twin infrastructures leveraging an event streaming platform for storage and processing in real time at scale
SPS – A Trade Show in Germany for Global Industrial IoT Vendors
“SPS covers the entire spectrum of smart and digital automation – from simple sensors to intelligent solutions, from what is feasible today to the vision of a fully digitalized industrial world“. No surprise almost all vendors show software and hardware solutions for innovative use cases like
- Condition monitoring in real time
- Predictive maintenance using artificial intelligence (AI) – I prefer the more realistic term “machine learning”, a subset of AI
- Integration of legacy machines and proprietary protocols in the shop floors
- Robotics
- New digital services
- Other related buzzwords.
Digital Twin as Huge Value Proposition
New software and hardware needs to improve business processes, increase revenue or cut costs. Many booths showed solution for a digital twin as part of this buzzword bingo and value proposition. Most vendors exhibited complete solutions as hardware or software products. Nobody talked about the underlying implementation. Not all vendors could explain in detail how the infrastructure really scales and performs under the hood.
This post starts from a different direction. It begins with definition and use cases of a digital twin infrastructure. The challenges and requirements are discussed in detail. Afterwards, possible architectures and combinations of solutions show the benefits of an open and scalable event streaming platform as part of the puzzle.
The value proposition of a digital twin always discusses the combination of OT and IT:
- OT: Operation Technology; dealing with machines and devices
- IT: Information Technology, dealing with information
Excursus: SPS == PLC —> A Core Component in each IoT Infrastructure
A funny, but relevant marginal note for non-German people: The event name of the trade fair and acronym “SPS” stands for “smart production solutions”. However, in Germany “SPS” actually stands for “SpeicherProgrammierbare Steuerung”. The English translation might be very familiar for you: “Programmable Logic Controller” or shortened “PLC“.
PLC is a core component in any industrial infrastructure. This industrial digital computer has been ruggedized and adapted for the control of manufacturing processes, such as:
- Assembly lines
- Robotic devices
- Any activity that requires high reliability control and ease of programming and process fault diagnosis
PLCs are built to withstand extreme temperatures, strong vibrations, high humidity, and more. Furthermore, since they are not reliant on a PC or network, a PLC will continue to independently function without any connectivity. PLC is OT. This is very different from the IT hardware a software engineers knows from developing and deploying “normal” Java, .NET or Golang applications.
Digital Twin – Merging the Physical and the Digital World
A digital twin is a digital replica of a living or non-living physical entity. By bridging the physical and the virtual world, data is transmitted seamlessly allowing the virtual entity to exist simultaneously with the physical entity. The digital twin therefore interconnects OT and IT.
Digital Replica of Potential and Actual Physical Assets
Digital twin refers to a digital replica of potential and actual physical assets (physical twin), processes, people, places, systems and devices. The digital replica can be used for various purposes. The digital representation provides both the elements and the dynamics of how an IoT device operates and lives throughout its life cycle.
Definitions of digital twin technology used in prior research emphasize two important characteristics. Firstly, each definition emphasizes the connection between the physical model and the corresponding virtual model or virtual counterpart. Secondly, this connection is established by generating real time data using sensors.

Digital Twins Link Internet of Things and Artificial Intelligence
Digital twins connect internet of things, artificial intelligence, machine learning and software analytics to create living digital simulation models. These models update and change as their physical counterparts change. A digital twin continuously learns and updates itself from multiple sources to represent its near real-time status, working condition or position.
This learning system learns from
- itself, using sensor data that conveys various aspects of its operating condition.
- human experts, such as engineers with deep and relevant industry domain knowledge.
- other similar machines
- other similar fleets of machines
- the larger systems and environment in which it may be a part of.
A digital twin also integrates historical data from past machine usage to factor into its digital model.
Use Cases for a Digital Twin in Various Industries
In various industrial sectors, digital twins are used to optimize the operation and maintenance of physical assets, systems and manufacturing processes. They are a formative technology for the IIoT. A digital twin in the workplace is often considered part of Robotic Process Automation (RPA). Per Industry-analyst firm Gartner, a digital twin is part of the broader and emerging hyperautomation category.
Some industries that can leverage digital twins include:
- Manufacturing Industry: Physical manufacturing objects are virtualized and represented as digital twin models seamlessly and closely integrated in both the physical and cyber spaces. Physical objects and twin models interact in a mutually beneficial manner. Therefore, the IT infrastructure also sends control commands back to the actuators of the machines (OT).
- Automotive Industry: Digital twins in the automobile industry use existing data in order to facilitate processes and reduce marginal costs. They can also suggest incorporating new features in the car that can reduce car accidents on the road.
- Healthcare Industry: Lives can be improved in terms of medical health, sports and education by taking a more data-driven approach to healthcare. The biggest benefit of the digital twin on the healthcare industry is the fact that healthcare can be tailored to anticipate on the responses of individual patients.
Examples for Digital Twins in the Industrial IoT
Digital twins are used in various scenarios. For example, they enable the optimization of the maintenance of power generation equipment such as power generation turbines, jet engines and locomotives. Further examples of industry applications are aircraft engines, wind turbines, large structures (e.g. offshore platforms, offshore vessels), heating, ventilation, and air conditioning (HVAC) control systems, locomotives, buildings, utilities (electric, gas, water, waste water networks).
Let’s take a look at some use cases in more detail:
Monitoring, Diagnostics and Prognostics
A digital twin can be used for monitoring, diagnostics and prognostics to optimize asset performance and utilization. In this field, sensory data can be combined with historical data, human expertise and fleet and simulation learning to improve the outcome of prognostics. Therefore, complex prognostics and intelligent maintenance system platforms can use digital twins in finding the root cause of issues and improve productivity.
Digital twins of autonomous vehicles and their sensor suite embedded in a traffic and environment simulation have also been proposed as a means to overcome the significant development, testing and validation challenges for the automotive application. In particular when the related algorithms are based on artificial intelligence approaches that require extensive training data and validation data sets.
3D Modeling for the Creation of Digital Companions
Digital twins are used for 3D modeling to create digital companions for the physical objects. It can be used to view the status of the actual physical object. This provides a way to project physical objects into the digital world. For instance, when sensors collect data from a connected device, the sensor data can be used to update a “digital twin” copy of the device’s state in real time.
The term “device shadow” is also used for the concept of a digital twin. The digital twin is meant to be an up-to-date and accurate copy of the physical object’s properties and states. This includes information such as shape, position, gesture, status and motion.
Embedded Digital Twin
Some manufacturers embed a digital twin into their device. This improves quality, allows earlier fault detection and gives better feedback on product usage to the product designers.
How to Build a Digital Twin Infrastructure?
TL;DR: You need to have the correct information in real time at the right location to be able to analyze the data and act properly. Otherwise you will have conversations like the following:
Challenges and Requirements for Building a Scalable, Reliable Digital Twin
The following challenges have to be solved to implement a successful digital twin infrastructure:
- Connectivity: Different machines and sensors typically do not provide the same interface. Some use a modern standard like MQTT or OPC-UA. Though, many (older) machines use proprietary interfaces. Furthermore, you also need to integrate to the rest of the enterprise.
- Ingestion and Processing: End-to-end pipelines and correlation of all relevant information from all machines, devices, MES, ERP, SCM, and any other related enterprise software in the factories, data center or cloud.
- Real Time: Ingestion of all information in real time (this is a tough term; in this case “real time” typically means milliseconds, sometimes even seconds or minutes are fine).
- Long-term Storage: Storage of the data for reporting, batch analytics, correlations of data from different data sources, and other use cases you did not think at the time when the data was created.
- Security: Trusted data pipelines using authentication, authorization and encryption.
- Scalability: Ingestion and processing of sensor data from one or more shop floors creates a lot of data.
- Decoupling: Sensors produce data continuously. They don’t ask if the consumers are available and if they can keep up with the input. The handling of backpressure and decoupling if producers and consumers is mandatory.
- Multi-Region or Global Deployment: Analysis and correlation of data in one plant is great. But it is even better if you can correlate and analyze the data from all your plants. Maybe even plants deployed all over the world.
- High Availability: Building a pipeline from one shop floor to the cloud for analytics is great. However, even if you just integrate a single plant, the pipeline typically has to run 24/7. In some cases without data loss and with order guarantees of the sensor events.
- Role-Based Access Control (RBAC): Integration of tens or hundreds of machines requires capabilities to manage the relation between the hardware and its digital twin. This includes the technical integration, role-based access control, and more.
The above list covers technical requirements. On top, business services have to be provided. This includes device management, analytics, web UI / mobile app, and other capabilities depending on your use cases.
So, how do you get there? Let’s discuss three alternatives in the following sections.
Solution #1 => IoT / IIoT COTS Product
COTS (commercial off-the-shelf) is software or hardware products that are ready-made and available for sale. IIoT COTS products are built for exactly one problem: Development, Deployment and Operations of IoT use cases.
Many IoT COTS solutions are available on the market. This includes products like Siemens MindSphere, PTC IoT, GE Predix, Hitachi Lumada or Cisco Kinetic for deployments in the data center or in different clouds.
Major cloud providers like AWS, GCP, Azure and Alibaba provide IoT-specific services. Cloud providers are a potential alternative if you are fine with the trade-offs of vendor lock-in. Main advantage: Native integration into the ecosystem of the cloud provider. Main disadvantage: Lock-in into the ecosystem of the cloud provider.
At the SPS trade show, 100+ vendors presented their IoT solution to connect shop floors, ingest data into the data center or cloud, and do analytics. Often, many different tools, products and cloud services are combined to solve a specific problem. This can either be obvious or just under the hood with OEM partners. I already covered the discussion around using one single integration infrastructure versus many different middleware components in much more detail.
Read Gartner’s Magic Quadrant for Industrial IoT Platforms 2019. The analyst report describes the mess under the hood of most IIoT products. Plenty of acquisitions and different code bases are the foundation of many commercial products. Scalability and automated rollouts are key challenges. Download of the report is possible with a paid Gartner account or via free download from any vendor with distribution rights, like PTC.
Proprietary and Vendor-specific Features and Products
Automation industry typically uses proprietary and expensive products. All of them are marketed as flexible cloud products. The truth is that most of them are not really cloud-native. This means they are not scalable and not extendible like you would expect it from a cloud-native service. Some problems I have heard in the past from end users:
- Scalability is not given. Many products don’t use a scalable architecture. Instead, additional black boxes or monoliths are added if you need to scale. This challenges uptime SLAs, burden of operations and cost.
- Some vendors just deploy their legacy on premise solution into AWS EC2 instances and call it a cloud product. This is far away from being cloud native.
- Even IoT solutions from some global cloud providers do not scale good enough to implement large IoT projects (e.g. to connect to one million cars). I saw several companies which evaluate a cloud-native MQTT solution. They then went to a specific MQTT provider afterwards (but still used the cloud provider for its other great services, like computing resources, analytics services, etc).
- Most complete IoT solutions use many different components and code bases under the hood. Even if you buy one single product, the infrastructure usually uses various technologies and (OEM) vendors. This makes development, testing, roll-out and 24/7 end-to-end operations much harder and more costly.
Long Product Lifecycles with Proprietary Protocols
In automation industry, product lifecycles are very long (tens of years). Simple changes or upgrades are not possible.
IIoT usually uses incompatible protocols. Typically, not just the products, but also these protocols are proprietary. They are just built for hardware and machines of one specific vendor. Siemens S7, Modbus, Allen Bradley, Beckhoff ADS, to name a few of these protocols and “standards”.
OPC-UA is supported more and more. This is a real standard. However, it has all the pros and cons of an open standard. It is often poorly implemented by the vendors and requires an app server on top of the PLC.
In most scenarios I have seen, connectivity to machines and sensors from different vendors is required, too. Even in one single plant, you typically have many different technologies and communication paradigms to integrate.
There is More than just the Machines and PLCs…
No matter how you integrate to the shop floor machines; this is just the first step to get data correlated with other systems from your enterprise. Connectivity to all the machines in the shop floors is not sufficient. Integration and combination of the IoT data with other enterprise applications is crucial. You also want to provide and sell additional services in the data center or cloud. In addition, you might even want to integrate with partners and suppliers. This adds additional value to your product. You can provide features you don’t sell by yourself.
Therefore, an IoT COTS solution does not solve all the challenges. There is huge demand to build an open, flexible, scalable platform. This is the reason why Apache Kafka comes into play in many projects as event streaming platform.
Solution #2 => Apache Kafka as Event Streaming Platform for the Digital Twin Infrastructure
Apache Kafka provides many business and technical characteristics out-of-the-box:
- Cost reduction due to open core principle
- No vendor lock-in
- Flexibility and Extensibility
- Scalability
- Standards-based Integration
- Infrastructure-, vendor- and technology-independent
- Decoupling of applications and machines
Apache Kafka – An Immutable, Distributed Log for Real Time Processing and Long Term Storage
I assume you already know Apache Kafka: The de-facto standard for real-time event streaming. Apache Kafka provides the following characteristics:
- Open-source (Apache 2.0 License)
- Global-scale
- High volume messaging
- Real-time
- Persistent storage for backup and decoupling of sources and sinks
- Connectivity (via Kafka Connect)
- Continuous Stream processing (via Kafka Streams)
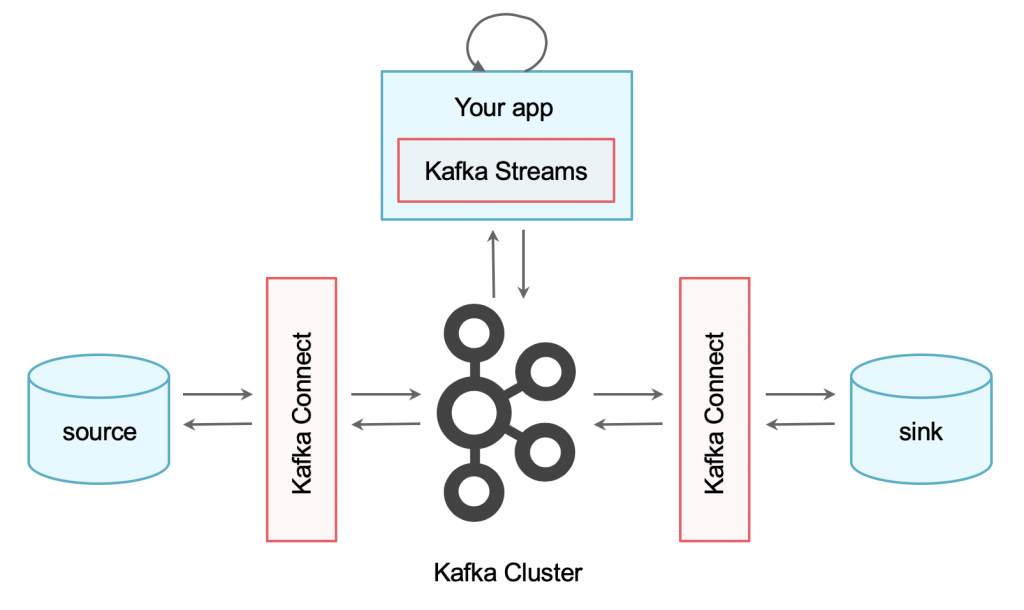
This is all included within the Apache Kafka framework. Fully independent of any vendor. Vibrant community with thousands of contributors from many hundreds of companies. Adoption all over the world in any industry.
If you need more details about Apache Kafka, check out the Kafka website, the extensive Confluent documentation, or hundreds of free video recordings and slide decks from all Kafka Summit events to learn about the technology and use cases.
How is Kafka related to Industrial IoT, shop floors and building digital twins? Let’s take a quick look at Kafka’s capabilities for integration and continuous data processing at scale.
Connectivity to Industrial Control Systems (ICS)
Kafka can connect to different functional levels of a manufacturing control operation:
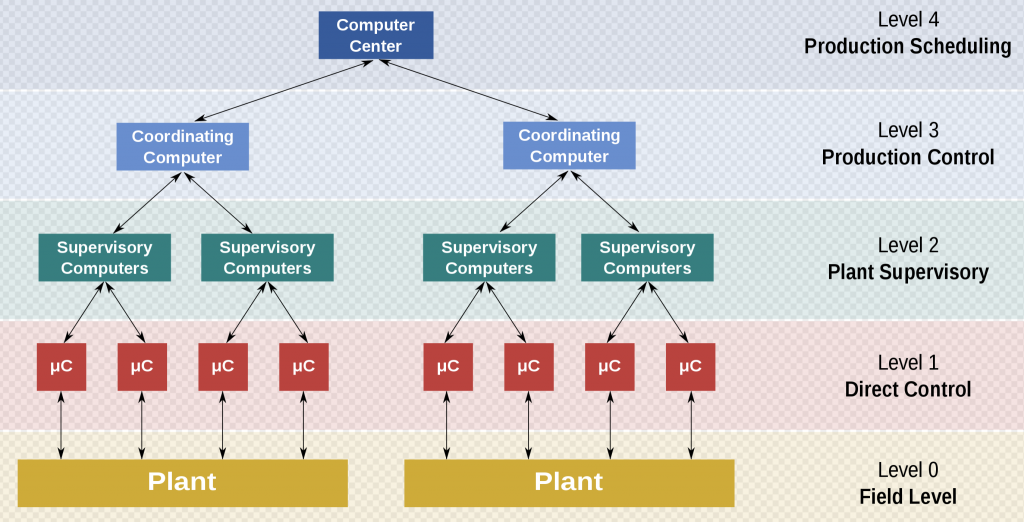
- Integrate directly to Level 1 (PLC / DCS): Kafka Connect or any other Kafka Clients (Java, Python, .NET, Go, JavaScript, etc.) can connect directly to PLCs or an OPC-UA server. The the data gets directly ingested from the machines and devices. Check out “Apache Kafka, KSQL and Apache PLC4X for IIoT Data Integration and Processing” for an example to integrate with different PLC protocols like Siemens S7 and Modbus in real time at scale.
- Integrate on level 2 (Plant Supervisory) or even above on 3 (Production Control) or 4 (Production Scheduling): For instance, you integrate with MES / ERP / SCM systems via REST / HTTP interfaces or any MQTT-supported plant supervisory or production control infrastructure. The blog post “IoT and Event Streaming at Scale with MQTT” discusses a few different options.
-
What about level 0 (Field level)? Today, IT typically only connects to PLCs respectively DCS. IT does not directly integrate to sensors and actuators in the field bus, switch or end node. This will probably change in the future. Sensors get smarter and more powerful. And new standards for the “last mile” of the network emerge, like 10BASE-T1L.
We discussed different integration levels between IT and OT infrastructure. However, connecting from the IT to the PLC and shop floor is just half of the story…
Connectivity and Data Ingestion to MES, ERP, SCM, Big Data, Cloud and the Rest of the Enterprise
Kafka Connect enables reliable and scalable integration of Kafka with any other system. This is important as you need to integrate and correlate sensor data from PLCs with applications and databases from the rest of the enterprise. Kafka Connect provides sources and sinks to
- Databases like Oracle or SAP Hana
- Big Data Analytics like Hadoop, Spark or Google Cloud Machine Learning
- Enterprise Applications like ERP, CRM, SCM
- Any other application using custom connectors or Kafka clients
Continuous Stream Processing and Streaming Analytics in Real Time on the Digital Twin with Kafka
A pipeline from machines to other systems in real time at scale is just part of the full story. You also need to continuously process the data. For instance, you implement streaming ETL, real time predictions with analytic models, or execute any other business logic.
Kafka Streams allows to write standard Java apps and microservices to continuously process your data in real-time with a lightweight stream processing Java API. You could alos use ksqlDB to do stream processing using SQL semantics. Both frameworks use Kafka natively under the hood. Therefore, you leverage all Kafka-native features like high throughput, high availability and zero downtime out-of-the box.
The integration with other streaming solutions like Apache Flink, Spark Streaming, AWS Kinesis or other commercial products like TIBCO StreamBase, IBM Streams or Software AG’s Apama is possible, of course.
Kafka is so great and widely adopted because it decouples all sources and sinks from each other leveraging its distributed messaging and storage infrastructure. Smart endpoints and dumb pipes is a key design principle applied with Kafka automatically to decouple services through a Domain-Driven Design (DDD):
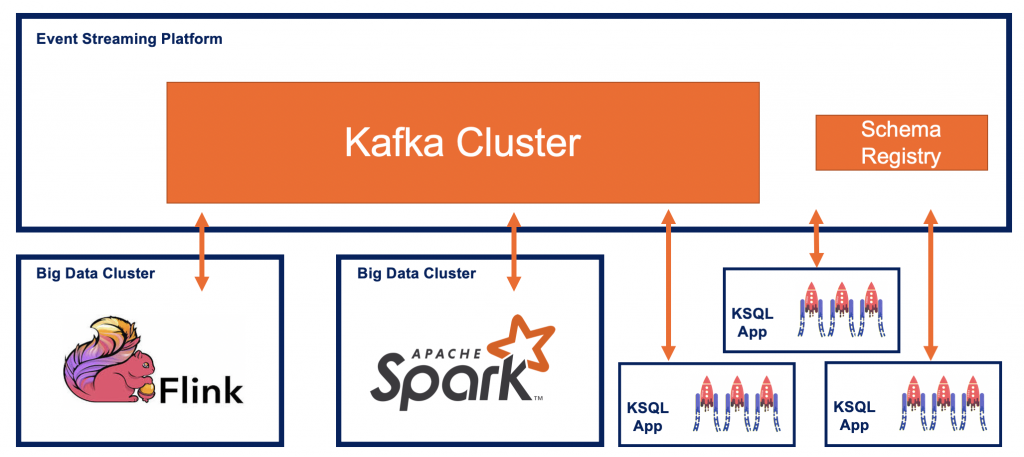
Kafka + Machine Learning / Deep Learning = Real Time Predictions in Industrial IoT
The combination of Kafka and Machine Learning for digital twins is not different from any other industry. However, IoT projects usually generate big data sets throught real time streaming sensor data. Therefore, Kafka + Machine Learning makes even more sense in IoT projects for building digital twins than in many other projects where you lack big data sets.
Analytic models need to be applied at scale. Predictions often need to happen in real time. Data preprocessing, feature engineering and model training also need to happen as fast as possible. Monitoring the whole infrastructure in real time at scale is a key requirement, too. This includes not just the infrastructure for the machines and sensors in the shop floor, but also the overall end-to-end edge-to-cloud infrastructure.
With this in mind, you quickly understand that Machine Learning / Deep Learning and Apache Kafka are very complementary. I have covered this in detail in many other blog posts and presentations. Get started here for more details:
- Blog Post: How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka
- Slide Deck: Apache Kafka + Machine Learning => Intelligent Real Time Applications
- Video Recording: Deep Learning in Mission Critical and Scalable Real Time Applications with Open Source Frameworks
Example for Kafka + ML + IoT: Embedded System at the Edge using an Analytic Model in the Firmware
Let’s discuss a quick example for Kafka + ML + IoT Edge: Embedded systems are very inflexible. It is hard to change code or business rules. The code in the firmware applies between input and out of the hardware. The code is embedded which implements business rules. However, new code or business rules cannot be simply deployed with a script or continuous delivery like you know it from your favorite Java / .NET / Go / Python application and tools like Maven and Jenkins. Instead, each change requires a new, long development lifecycle including tests, certifications and a manufacturing process.
There is another option Instead of writing and embedding business rules in code with a complex and costly process: Analytic models can be trained on historical data. This can happen anywhere. For instance, you can ingest sensor data into a data lake in the cloud via Kafka. The model is trained in the elastic and flexible cloud infrastructure. Finally, this model is deployed to an embedded system respectively a new firmware version is created with this model (using the long, expensive process). However, updating (i.e. improving) the model (which is already deployed on the embedded system) gets much easier because no code has to be changed. The mode is “just” re-trained and improved.
This way, business rules can be updated and improved by improving the already deployed model in the embedded system. No new development lifecycle, testing and certification and manufacturing process are required. DNP/AISS1 from SSV Software is one example of a hardware starter kit with pre-installed ML algorithms.
Solution #3 => Kafka + IIoT COTS Product as Complementary Solutions for the Digital Twin
The above sections described how to use either an IoT COTS product or an event streaming platform like Apache Kafka and its ecosystem for building a digital twin infrastructure. Interestingly, Kafka and IoT COTS are actually combined in most deployments I have seen so far.
Most IoT COTS products provide out-of-the-box Kafka connectors because end users are asking for this feature all the time. Let’s discuss the combination of Kafka and other IoT products in more detail.
Kafka is Complementary to Industry Solutions such as Siemens MindSphere or Cisco Kinetic
Kafka can be used in very different scenarios. It is s best for building a scalable, reliable and open infrastructure to integrate IoT at the edge and the rest of the enterprise.
However, Kafka is not the silver bullet for every problem. A specific IoT product might be the better choice for integration and processing of IoT interfaces and shop floors. This depends on the specific requirements, existing ecosystem and already used software. Complexity and cost of solutions need to be evaluated. “Build vs. buy” is always a valid question. Often, the best choice and solution is a mix of building an open, flexible, self-built central streaming infrastructure and buying COTS for specific integration and processing scenarios.
Different Combinations of Kafka and IoT Solutions
The combination of an even streaming platform like Kafka with one or more other IoT products or frameworks is very common:
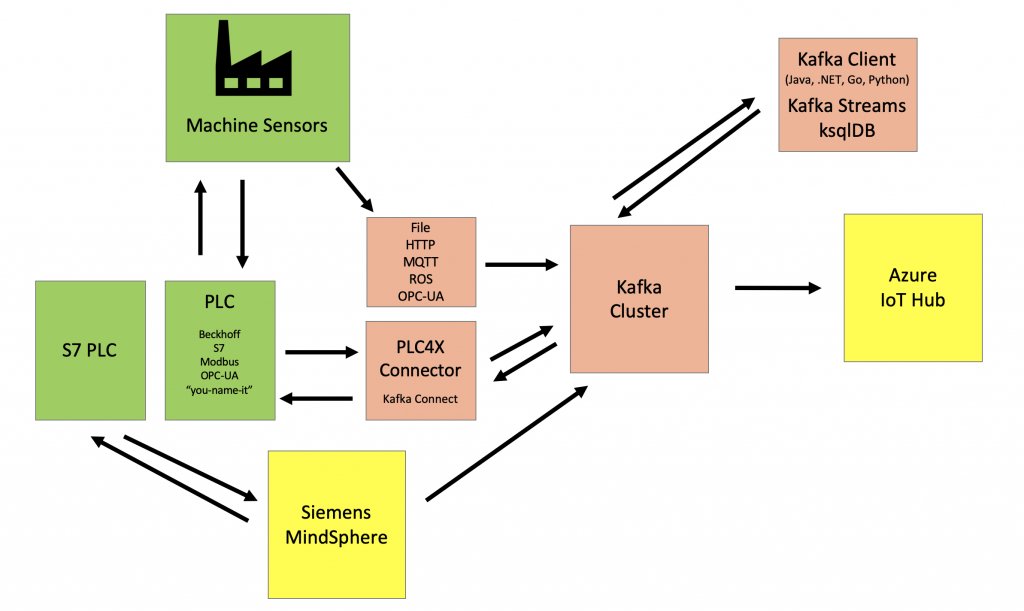
Sometimes, the shop floor is connecting to an IoT solution. The IoT solution is used as gateway or proxy. This can be a broad, powerful (but also more complex and expensive) solution like Siemens MindSphere. Or the choice is to deploy “just” a specific solution, more lightweight solution to solve one problem. For instance, HiveMQ could be deployed as scalable MQTT cluster to connect to machines and devices. This IoT gateway or proxy connects to Kafka. Kafka is either deployed in the same infrastructure or in another data center or cloud. The Kafka cluster connects to the rest of the enterprise.
In other scenarios, Kafka is used as IoT gateway or proxy to connect to the PLCs or Distributed Control System (DCS) directly. Kafka then connects to an IoT Solution like AWS IoT or Google Cloud’s MQTT Bridge where further processing and analytics happen.
Communication is often bidirectional. No matter what architecture you choose. This means the data is ingested from the shop floor, processed and correlated, and finally control events are sent back to the machines. For instance, in predictive analytics, you first train analytic models with tools like TensorFlow in the cloud. Then you deploy the analytic model at the edge for real time predictions.
Eclipse ditto – An Open Source Framework Dedicated to the Digital Twin; with Kafka Integration
There is not just commercial IoT solutions on the market, of course. Kafka is complementary to COTS IoT solutions and to open source IoT frameworks. Eclipse IoT alone provides various different IoT frameworks. Let’s take a look at one of them, which fits perfectly into this blog post:
Eclipse ditto – an open source framework for building a digital twin. With the decoupled principle of Kafka, it is straightforward to leverage other frameworks for specific tasks.
ditto was created to help realizing digital twins with an open source API. It provides features like like Device-as-a-Service, state management for digital twins, and APIs to organize your set of digital twins. Kafka integration is built-in into ditto out-of-the-box. Therefore, ditto and Kafka complement each other very well to build a digital twin infrastructure.
The World is Hybrid and Polyglot
The world is hybrid and polyglot in terms of technologies and standards. Different machines use different technologies and protocols. Each plant uses its own frameworks, products and standards. Business units use different analytics tools and not always the same clouds provider. And so on…
Global Kafka Architecture for Edge / On Premises / Hybrid / Multi Cloud Deployments of the Digital Twin
Kafka is often not just the backbone to integrate IoT devices and the rest of the enterprise. More and more companies deploy multiple Kafka clusters in different regions, facilities and cloud providers.
The right architecture for Kafka deployments depends on the use cases, SLAs and many other requirements. If you want to build a digital twin architecture, you typically have to think about edge AND data centers / cloud infrastructure:
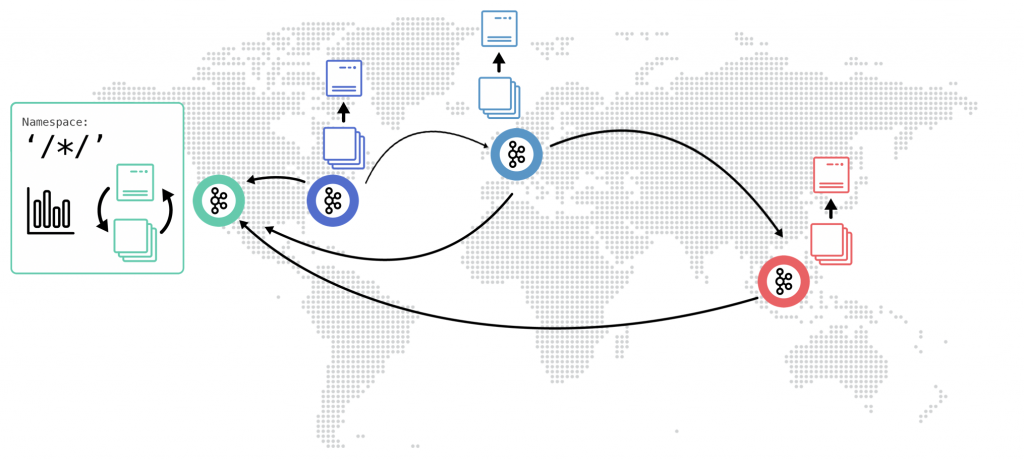
Apache Kafka as Global Nervous System for Streaming Data
Using Kafka as global nervous system for streaming data typically means you spin up different Kafka clusters. The following scenarios are very common:
- Local edge Kafka clusters in the shop floors: Each factory has its own Kafka cluster to integrate with the machines, sensors and assembly lines. But also with ERP systems, SCADA monitoring tools, and mobile devices from the workers. This is typically a very small Kafka cluster with e.g. three Brokers (which still can process ~100+ MB/sec). Sometimes, one single Kafka broker is deployed. This is fine if you do not need high availability and prefer low cost and very simple operations.
- Central regional Kafka clusters: Kafka clusters are deployed in different regions. Each Kafka cluster is used to ingest, process and aggregate data from different factories in that region or from all cars within a region. These Kafka clusters are bigger than the local Kafka clusters as they need to integrate data from several edge Kafka clusters. The integration can be realized easily and reliable with Confluent Replicator or in the future maybe with MirrorMaker 2 (if it matures over time). Don’t use Mirrormaker 1 at all – you can find many good reasons on the web. Another option is to directly integrate Kafka clients deployed at the edge to a central regional Kafka cluster. Either with a Kafka Client using Java, C, C++, Python, Go or another programming language. Or using a proxy in the middle, like Confluent REST Proxy, Confluent MQTT Proxy, or any MQTT Broker outside the Kafka environment. Find out more details about comparing different MQTT and HTTP-based IoT integration options for Kafka here.
- Multi-region or global Kafka clusters: You can deploy one Kafka cluster in each region or continent. Then replicate the data between each other (one- or bidirectional) in real time using Confluent Replicator. Or you can leverage the multi-data center replication Kafka feature from Confluent Platform to spin up one logical cluster over different regions. The latter provides automatic fail-over, zero data loss and much easier operations of server and client side.
This is just a quick summary of deployment options for Kafka clusters at the edge, on premises or in the cloud. You typically combine different options to deploy a hybrid and global Kafka infrastructure. Often, you start small with one pipeline and a single Kafka cluster. Scaling up and rolling out the global expansion should be included into the planning from the beginning. I will speak in more detail about different “architecture patterns and best practices for distributed, hybrid and global Apache Kafka deployments” at DevNexus in Atlanta in February 2020. This is a good topic for another blog post in 2020.
Polyglot Infrastructure – There is no AWS, GCP or Azure Cloud in China and Russia!
For global deployments, you need to choose the right cloud providers or build your own data centers in some different regions.
For example, you might leverage Confluent Cloud. This is a fully managed Kafka service with usage-based pricing and enterprise-ready SLAs in Europe and the US on Azure, AWS or GCP. Confluent Cloud is a real serverless approach. No need to think about Kafka Brokers, operations, scalability, rebalancing, security, fine tuning, upgrades.
US cloud providers do not provide cloud services in China. Alibaba is the leading cloud provider. Kafka can be deployed on Alibaba cloud. Or choose a generic cloud-native infrastructure like Kubernetes. Confluent Operator, a Kubernetes Operator including CRD and Helm charts, is a tool to support and automate provisioning and operations on any Kubernetes infrastructure.
No public cloud is available in Russia at all. The reasons is mainly legal restrictions. Kafka has to be deployed on premises.
In some scenarios, the data from different Kafka clusters in different regions is replicated and aggregated. Some anonymous sensor data from all continents can be correlated to find new insights. But some specific user data might always just stay in the country of origin and local region.
Standardized Infrastructure Templates and Automation
Many companies build one general infrastructure template on a specific abstraction level. This template can then be deployed to different data centers and cloud providers the same way. This standardizes and eases operations in global Kafka deployments.
Cloud-Native Kubernetes for Robust IoT and Self-Healing, Scalable Kafka Cluster
Today, Kubernetes is often choosen as the abstraction layer. Kubernetes is deployed and managed by the cloud provider (e.g. GKE on GCP) or an operations team on premises. All required infrastructure on top of Kubernetes is scripted and automated with a template framework (e.g. Terraform). This can then be rolled out to different regions and infrastructures in the same standardized and automated way.
The same is applicable for the Kafka infrastructure on top of Kubernetes. Either you leverage existing tools like Confluent Operator or build your own scripts and custom resource definitions. The Kafka Operator for Kubernetes has several features built-in, like automated handling of fail-over, rolling upgrades and security configuration.
Find the right abstraction level for your Digital Twin infrastructure:
You can also use tools like the open source Kafka Ansible scripts to deploy and operate the Kafka ecosystem (including components like Schema Registry or Kafka Connect), of course.
However, the beauty of a cloud-native infrastructure like Kubernetes is its self-healing and robust characteristics. Failure is expected. This means that your infrastructure continues to run without downtime or data loss in case of node or network failures.
This is quite important if you deploy a digital twin infrastructure and roll it out to different regions, countries and business units. Many failures are handled automatically (in terms of continuous operations without downtime or data loss).
Not every failure requires a P1 and call to the support hotline. The system continues to run while an ops team can replace defect infrastructure in the background without time pressure. This is exactly what you need to deploy robust IoT solutions to production at scale.
Apache Kafka as the Digital Twin for 100000 Connected Cars
Let’s conclude with a specific example to build a Digital Twin infrastructure with the Kafka ecosystem. We use an implementation from the automotive industry. But this is applicable to any scenario where you want to build and leverage digital twins. Read more about “Use Cases for Apache Kafka in Automotive Industry” here.
Honestly, this demo was not built with the idea of creating a digital twin infrastructure in mind. However, think about it (and take a look at some definitions, architectures and solutions on the web): Digital Twin is just a concept and software design pattern. Remember our definition from the beginning of the article: A digital twin is a digital replica of a living or non-living physical entity. Therefore, the decision of the right architecture and technology depends on the use case(s).
We built a demo which shows how you can integrate with tens or hundreds of thousands IoT devices and process the data in real time. The demo use case is predictive maintenance (i.e. anomaly detection) in a connected car infrastructure to predict motor engine failures: “Building a Digital Twin for Streaming Machine Learning at Scale from 100000 IoT Devices with HiveMQ, Apache Kafka and TensorFlow“.
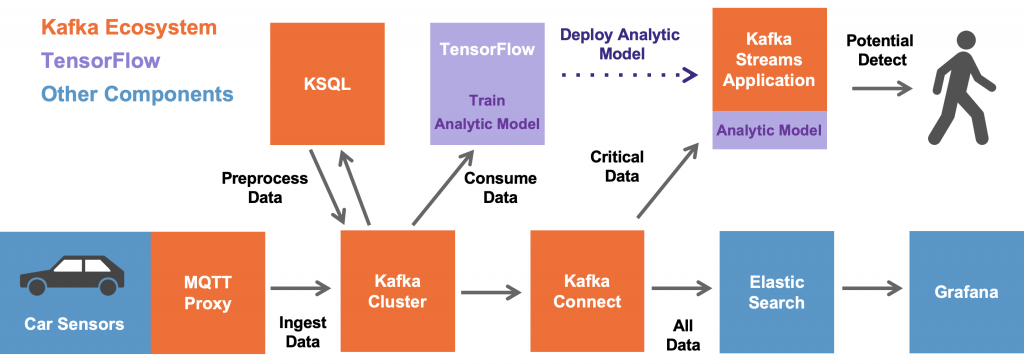
In this example, the data from 100000 cars is ingested and stored in the Kafka cluster, i.e. the digital twin, for further processing and real time analytics.
Kafka client applications consume the data for different use cases and in different speed:
- Real time data pre-processing and data engineering using the data from the digital twin with Kafka Streams and KSQL / ksqlDB.
- Streaming model training (i.e. without a data lake in the middle) with the Maschine Learning / Deep Learning framework TensorFlow and its Kafka plugin (part of TensorFlow I/O). In our example, we train two neural networks: An unsupervised Autoencoder for anomaly detection and a supervised LSTM.
- Model deployment for inference in real time on new car sensor events to predict potential failures in the motor engine.
- Ingestion of the data into another batch system, database or data lake (Oracle, HDFS, Elastic, AWS S3, Google Cloud Storage, whatever).
- Another consumer could be a real time time series database like InfluxDB or TimescaleDB.
Build your own Digital Twin Infrastructure with Kafka and its Open Ecosystem!
I hope this post gave you some insights and ideas. I described three options to build the infrastructure for a digital twin: 1) IoT COTS, 2) Kafka, 3) Kafka + Iot COTS. Many companies leverage Apache Kafka as central nervous system for their IoT infrastructure in one way or the other.
Digital Twin is just one of many possible IoT use cases for an event streaming platform. Often, Kafka is “just” part of the solution. Pick and choose the right tools for your use cases. Evaluate the Kafka ecosystem and different IoT frameworks / solutions to find the best combination for your project. Don’t forget to include the vision and long-term planning into your decisions! If you plan it right from the beginning, it is (relative) straightforward to start with a pilot or MVP. Then roll it out to the first plant into production. Over time, deploy a global Digital Twin infrastructure… 🙂
