
Introducing new features in Confluent Platform 5.4 and Apache Kafka 2.4… I just want to share a presentation I did recently as part of the “Confluent Kitchen Tour” in response to the global travel ban and Corona crisis.

Confluent Platform 5.4 (with Apache Kafka 2.4)
CP 5.4 (based on AK 2.4) brings some awesome new features to build scalable, reliable and secure event streaming deployments:
- Security: Role-Based Access Control (RBAC) and Structured Audit Logs
- Resilience: Multi-Region Clusters (MRC)
- Data Compatibility: Server-side Schema Validation for Schema Registry
- Management & Monitoring: Control Center enhancements, RBAC management, Replicator monitoring
- Performance & Elasticity: Tiered Storage (preview)
- Stream Processing: New ksqlDB features like Pull Queries and Kafka Connect Integration (preview)
Rapid Pace of Innovation for Mission-Critical Event Streaming
Confluent Platform (CP), the commercial offering from #1 Kafka vendor Confluent, gets more powerful and mature with every release (no surprise). CP releases are tightly coupled to the latest Apache Kafka release to leverage bug fixes and new features from the open source community.
Let’s take a looks at my favorite new features: RBAC, Multi-Region Stretched Clusters and Tiered Storage for Apache Kafka.
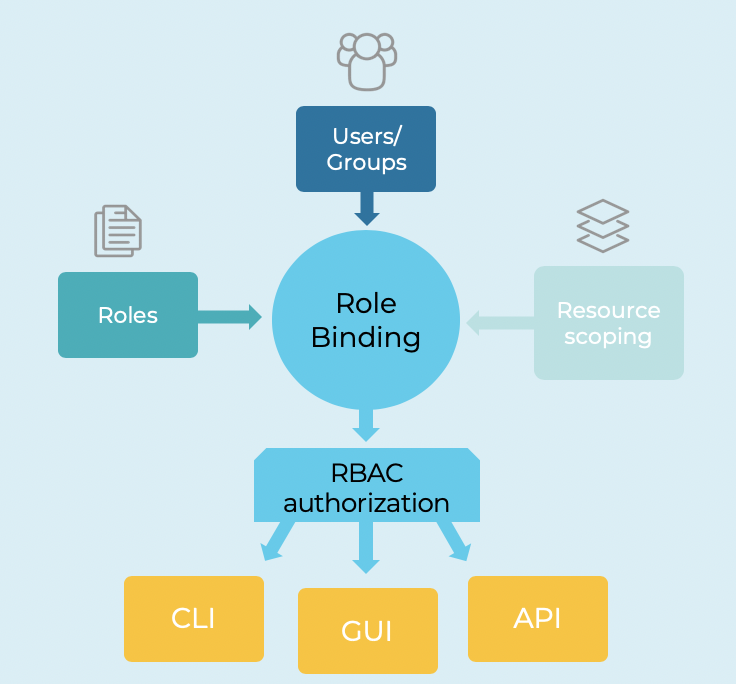
Role Based Access Control (RBAC) for Apache Kafka
Kafka provides Access Control Lists (ACL). This is a low level feature and misses higher level, scalable configuration options.
Role-Based Access Control (RBAC) provides platform-wide security with fine-tuned granularity:
- Granular control of access permissions
- Clusters, topics, consumer groups, connectors
- Efficient management at large scale
- Delegate authorization management to true resource owners
- Platform-wide standardization
- Enforced via GUI, CLI and APIs
- Enforced across all CP components: Connect, KSQL, Schema Registry, REST Proxy, Control Center and MQTT Proxy
- Integration with LDAP and Active Directory
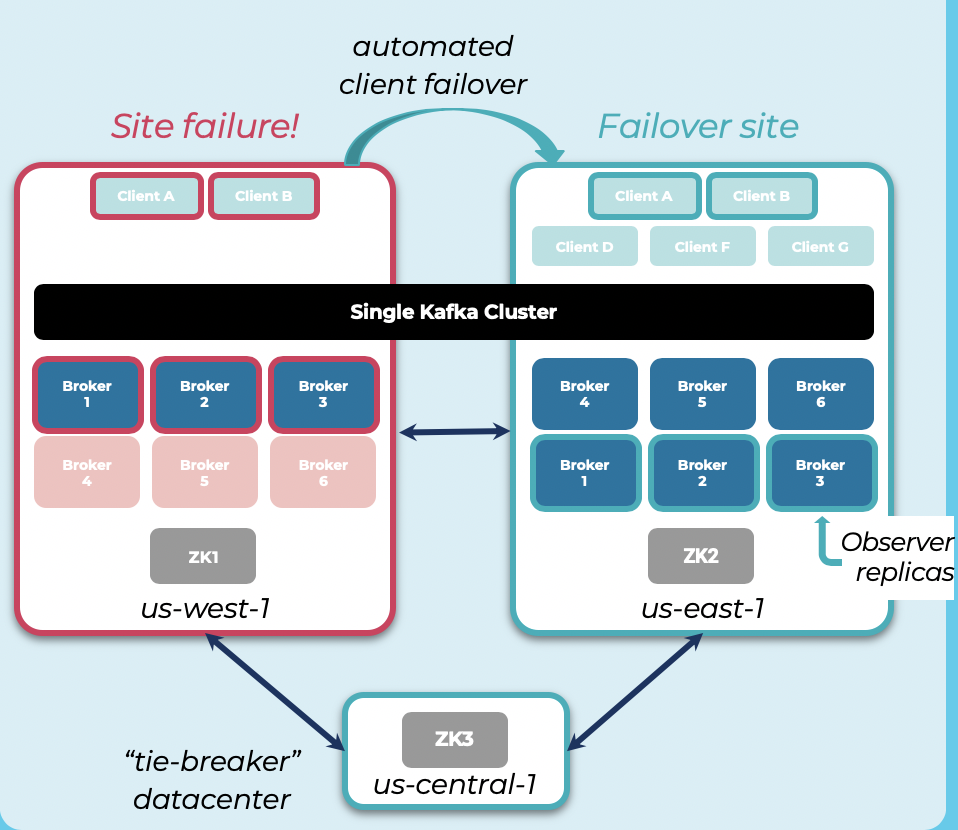
Multi-Region Replication (MRC) for Reliable Stretched Deployments
Stretched Clusters are a common deployment option for Kafka. However, this setup is hard to operate and cannot spread over different regions.
Multi-Region Clusters (MRC) change the game for disaster recovery for Kafka:
- Zero downtime and zero data loss for critical Kafka Topics
- Automated client fail-over
- Streamlined DR operations
- Leverages Kafka’s internal replication
- No separate Connect clusters
- Single multi-region cluster with high write throughput
- Asynchronous replication using “Observer” replicas
- Low bandwidth costs and high read throughput
- Remote consumers read data locally, directly from Observers
Check out “Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments” to understand the trade-offs between a “normal stretched cluster” and Confluent’s Multi-Region Clusters (MRC)”.
MRC is really a game-changer for mission-critical Kafka deployments to guarantee zero downtime and zero data loss (also known as RPO=0 and RTO=0).
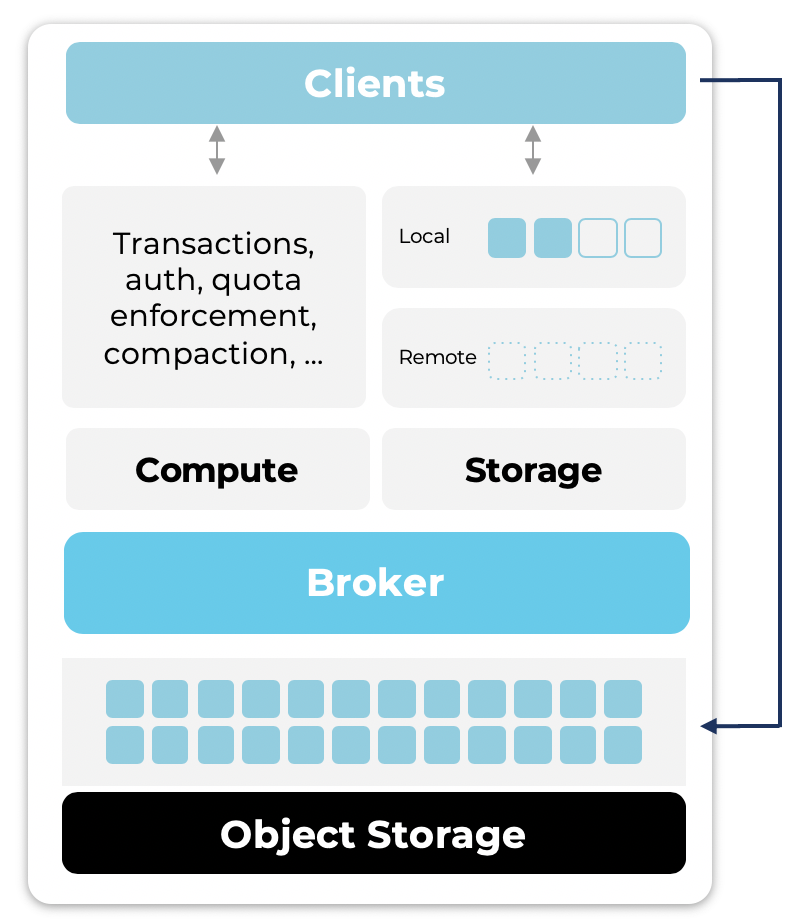
Tiered Storage for Better Scalability and Long Term Storage
Tiered Storage (preview release) enables Kafka with infinite retention cost-effectively and elastic scalability / data rebalancing:
- Infinite retention
- Older data is offloaded to inexpensive object storage, accessible at any time
- Reduced storage costs
- Storage limitations, like capacity and duration, are effectively uncapped
- Elastic scalability
- “Lighter” Kafka brokers enable instantaneous load balancing when scaling up
“Streaming Machine Learning with Tiered Storage and Without a Data Lake” shows a concrete example to leverage Tiered Storage for real time analytics and machine learning using TensorFlow.
Confluent Platform 5.4 (Slides + Video)
Here are the slides with an overview about the new features:
https://www.slideshare.net/KaiWaehner/confluent-platform-54-apache-kafka-24-overview-rbac-tiered-storage-multiregion-clusters-audit-logs-and-more
Here is a link to the video recording. Please note that this was delivered in German language.
Confluent Cloud – The Fully-Managed Alternative
Oh, and if you prefer a cloud service instead of self-managed Kafka deployments, please check out Confluent Cloud – the only really fully-managed Kafka-as-a-Service offering on the market with consumption-based pricing and mission critical SLAs.
Available on all major cloud providers (AWS, GCP and Azure). Leveraging the latest release of Kafka and providing tons of additional features (like fully managed connectors, Schema Registry and ksqlDB).
