
The combination of Apache Kafka and Machine Learning / Deep Learning are the new black in Banking and Finance Industry. This blog post covers use cases, architectures and a fraud detection example.
Event Streaming in the Finance Industry
Various different (typically mission-critical) use cases emerged to deploy event streaming in the finance industry. Here are a few companies leveraging Apache Kafka for banking projects:
Here are a few concrete examples:
- Capital One: Becoming truly event driven – offering a service other parts of the bank can use.
- ING: Significantly improved customer experience – as a differentiator + Fraud detection and cost savings.
- Nordea: Able to meet strict regulatory requirements around real-time reporting + cost savings.
- Paypal: Processing 400+ Billion events per day for user behavioral tracking, merchant monitoring, risk & compliance, fraud detection, and other use cases.
- Royal Bank of Canada (RBC): Mainframe off-load, better CX & fraud detection – brought many parts of the bank together
This is just a very short list of companies in the financial sector using Apache Kafka as event streaming platform for the heart of their business. Plenty of other examples are available by tens of global banks leveraging Apache Kafka for many use cases.
Apache Kafka as Middleware in Banking
One of the key use cases I see in banking is actualIy NOT the reason for this post: Apache Kafka as modern, scalable, reliable middleware:
- Building a scalable 24/7 middleware infrastructure with real time processing, zero downtime, zero data loss and integration to legacy AND modern technologies, databases and applications
- Integration with existing legacy middleware (ESB, ETL, MQ)
- Replacement of proprietary integration platforms
- Offloading from expensive systems like Mainframes
For these scenarios, please check out my blogs, slides and videos about Apache Kafka vs. Middleware (MQ, ETL, ESB).
Let’s now focus on another very interesting topic I see more and more in the finance industry: Apache Kafka + Event Streaming + Machine Learning. Let’s discuss how this fits together from use case and technical perspective…
Machine Learning in Banking and Financial Services
Machine Learning (ML) allows computers to find hidden insights without
being explicitly programmed where to look. Different algorithms are applied to historical data to find insights and patterns. These insights are then stored in an analytic model to do predictions on new events. Some example for ML algorithms:
- Linear Regression
- Decision Trees
- Naïve Bayes
- Clustering
- Neural Networks (aka Deep Learning) like CNN, RNN, Transformer, Autoencoder
If you need more details about Machine Learning / Deep Learning, check out other resources on the web.
We want to find out how to leverage Machine Learning together with Kafka to improve traditional and to build new innovative use cases in the finance industry:
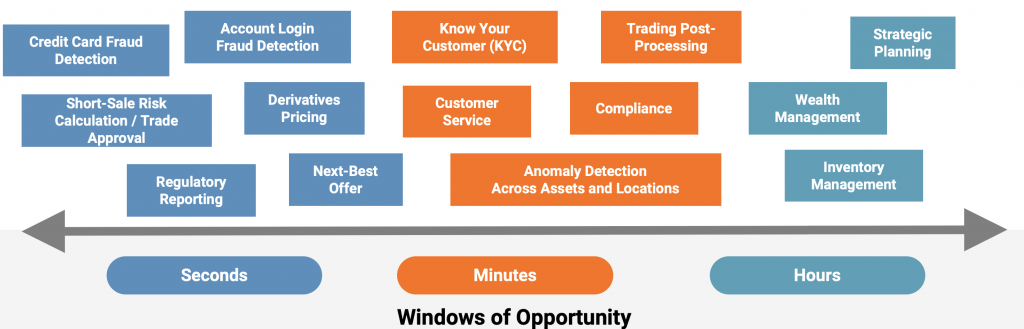
Machine Learning Pipelines for Model Training, Scoring and Monitoring
In general, you need to create a pipeline for model training, model scoring (aka predictions) and monitoring, like the following: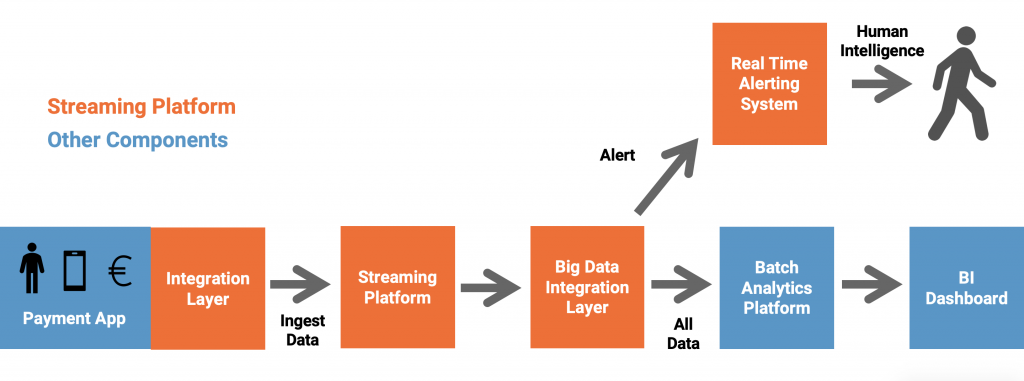 Some key requirements for most ML pipelines:
Some key requirements for most ML pipelines:
- Real time processing
- Ingestion and data processing at scale (often very high throughput)
- Scalability and reliability (often zero downtime AND zero data loss)
- Integration with various technologies, databases and applications (typically legacy and modern interfaces)
- Decoupling of data producers and data consumers (some are real time, but others are near real time, batch or request-response)
Does this sound familiar to you? I guess you can imagine why Apache Kafka comes into play here…
Apache Kafka and Machine Learning / Deep Learning
I talked about the relation between Apache Kafka and Machine Learning / Deep Learning more than enough in the past two years. As a recap, here is how a Kafka+ML architecture could look like:
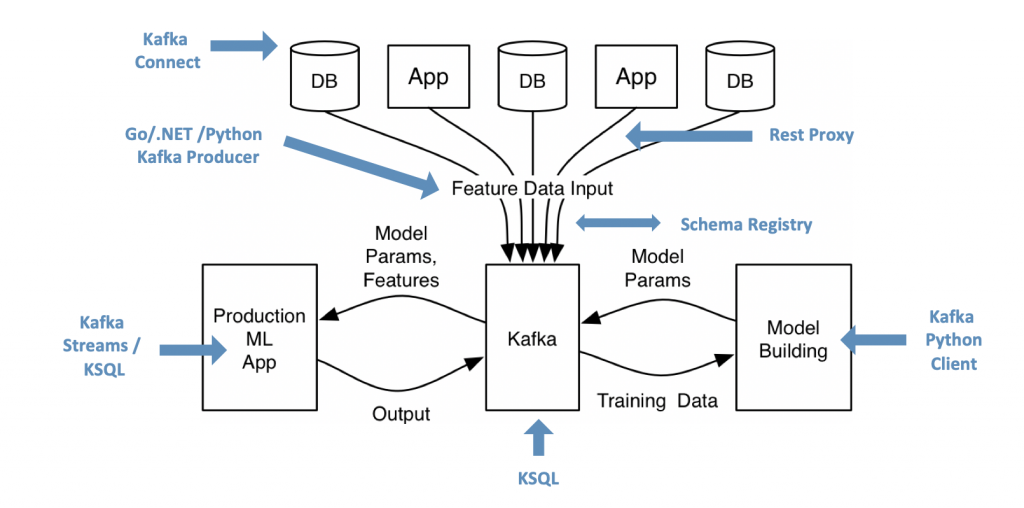
I recommend the following blog posts to learn more about building a scalable and reliable real time infrastructure for ML:
- Intro: How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka
- Focus on model deployment (Embedded vs. model server): Machine Learning and Real-Time Analytics in Apache Kafka Applications
- Cutting Edge ML without the need for a data lake: Streaming Machine Learning with Kafka, Tiered Storage and Without a Data Lake
Let’s now take a look at a concrete example…
Fraud Detection – Helping the Finance Industry with Event Streaming and AI / Machine Learning
Fraud is a billion-dollar business and it is increasing every year. The PwC global economic crime survey of 2018 found that half (49 percent) of the 7,200 companies they surveyed had experienced fraud of some kind.
Traditional methods of data analysis have long been used to detect fraud. They require complex and time-consuming investigations that deal with different domains of knowledge like financial, economics, business practices and law. Fraud often consists of many instances or incidents involving repeated transgressions using the same method. Fraud instances can be similar in content and appearance but usually are not identical.
This is where machine learning and artificial intelligence (AI) come into play: These ML algorithms seek for accounts, customers, suppliers, etc. that behave ‘unusually’ in order to output suspicion scores, rules or visual anomalies, depending on the method.
Streaming Analytics for Real Time Fraud Detection
Let’s take a look at a possible architecture to implement real time streaming analytics for fraud detection at scale:
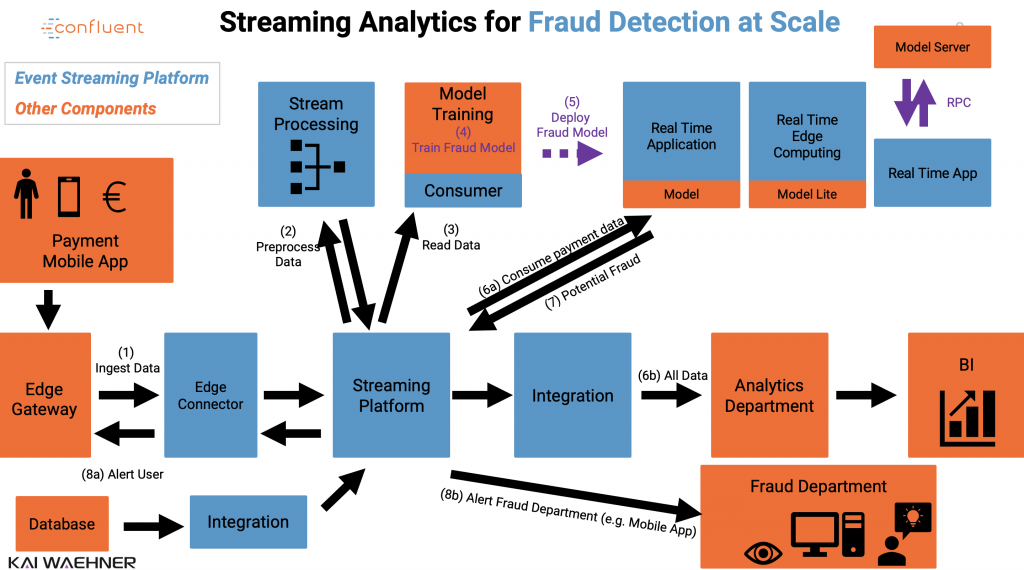
You can always choose between traditional and cutting-edge methods and algorithms for each use case you deploy to the event streaming platform.
Sometimes, existing business rules or statistical models work fine. Not everything needs to be a neural network – because it also has drawback like high requirements for computing power and big data sets. Not everything needs to be real time. Cutting edge technologies are awesome, but not need required for everything. BUT all of these technologies and concepts have to work with each other seamlessly and reliably.
Fraud Detection with Apache Kafka, Kafka Streams Kafka Connect, ksqlDB and TensorFlow
The following shows the above use case mapped to technologies:
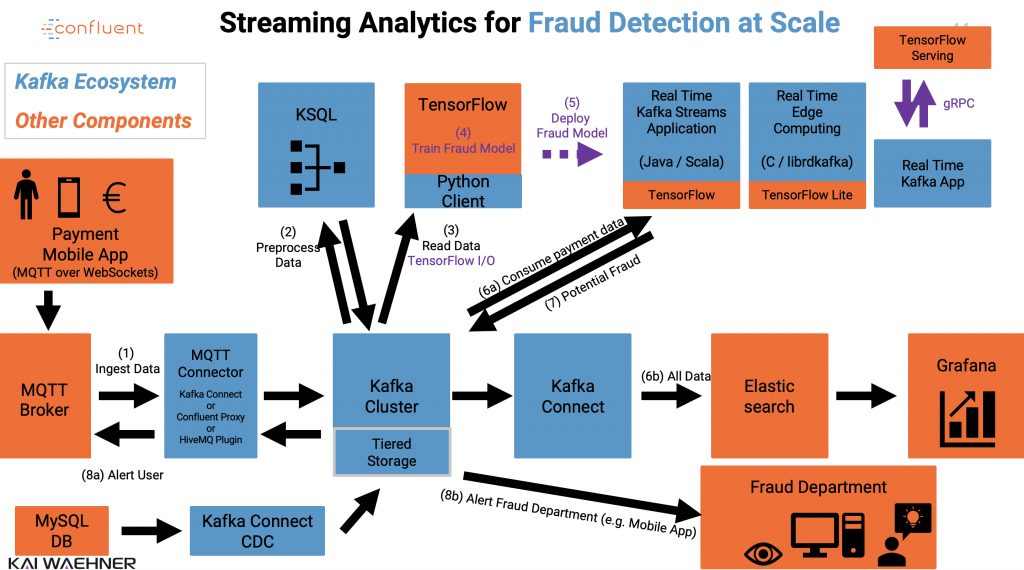
We leverage the following technologies:
- Apache Kafka as central, scalable and reliable Event Streaming platform
- Kafka Connect to integrate with data sources and data sinks (some real time, some batch, some request-response via REST / HTTP)
- Kafka Streams / ksqlDB to implement continuous data processing (streaming ETL, business rules, model scoring)
- MQTT over WebSockets to connect to millions of users via web and mobile apps
- TensorFlow for model training and model scoring
- TensorFlow IO for streaming ingestion from a Kafka topic for model training (another approach not shown here is to ingest the data from Kafka into a data lake like Hadoop or AWS S3 to do model training with ML cloud services, Spark or any other ML tool)
Any other technology can be added / replaced / removed depending on your use case. For instance, it is totally fine and common to complement the above architecture
- with legacy middleware already in place
- by re-processing the data from the commit log with different ML technologies like open source H2O.ai or the AutoML tool DataRobot
- integrating with other stream processing engines like Apache Flink
This sounds pretty cool? You want to try it out by yourself?
Demos and Code Examples for Apache Kafka + Machine Learning
Please check out my Github page. The repositories provide various demos and code examples for Apache Kafka + Machine Learning using different ML technologies like TensorFlow, DL4J and H2O.
These examples do not focus on the finance industry. But you can easily map this to your use cases; I have seen various deployments in the financial sector doing exactly the same as the examples below implement.
Here are some highlights of my Github repository:
- Getting started: Different models embedded into Kafka Streams microservices
- Model scoring with SQL: Deep Learning UDF for KSQL for Streaming Anomaly Detection
- Kafka combined with a model server: TensorFlow Serving + gRPC + Java + Kafka Streams
- Rapid Prototyping: Kafka + ML using Python in a Jupyter Notebook
- ML at scale: Streaming Machine Learning at Scale from 100000 IoT Devices with HiveMQ, Apache Kafka and TensorFLow
Slides / Video Recording: Kafka + ML in Finance Industry
Take a look at these slides and video recording to understand in more details how to build a ML infrastructure with the Kafka ecosystem and your favorite ML tools, cloud services, and other infrastructure components.
I explain in more detail how and why Apache Kafka has become the de facto standard for reliable and scalable streaming infrastructures in the finance industry.
AI / Machine learning and the Apache Kafka ecosystem are a great combination for training, deploying and monitoring analytic models at scale in real time. They are showing up more and more in projects, but still feel like buzzwords and hype for science projects. Therefore, I discuss in detail:
- Connecting the dots! How are Kafka and Machine Learning related?
- How can these concepts and technologies be combined to productionize analytic models in mission-critical and scalable real time applications?
- A step-by-step approach to build a scalable and reliable real time infrastructure for fraud detection in an instant-payment application using Deep Learning and an Autoencoder for anomaly detection
We build a hybrid ML architecture using technologies such as Apache Kafka, Kafka Connect, Kafka Streams, ksqlDB, TensorFlow, TF Serving, TF IO, Confluent Tiered Storage, Google Cloud Platform (GCP), Google Cloud Storage (GCS), and more.
Check out the slide deck:
https://www.slideshare.net/KaiWaehner/apache-kafka-and-deep-learning-in-banking-and-financial-services
Here is the video recording walking through the above slides:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Multi-Region Disaster Recovery
The most critical infrastructures require 24/7 availability and zero data loss even in case of disaster, i.e. outage of a complete data center or cloud region.
From ML perspective, an outage might be acceptable for model training. However, model scoring and monitoring (e.g. for fraud detection in your instant payment application) should run continuously with zero downtime and zero data loss (aka RPO = 0 and RTO = 0).
Machine Learning Architecture with Zero Down Time and Zero Data Loss
Banking and finance industry is where I see the highest number of critical use cases across all industries. Kafka is highly available by nature. However, disaster recovery without downtime and without data loss is still not easy to solve. Tools like MirrorMaker 2 or Confluent Replicator are good enough for some scenarios. If you need guaranteed zero downtime and zero data loss, additional tooling is required.
Confluent provides Multi-Region Clusters (MRC) to solve this problem. Let’s take a look at the architecture of a large FinServ customer:
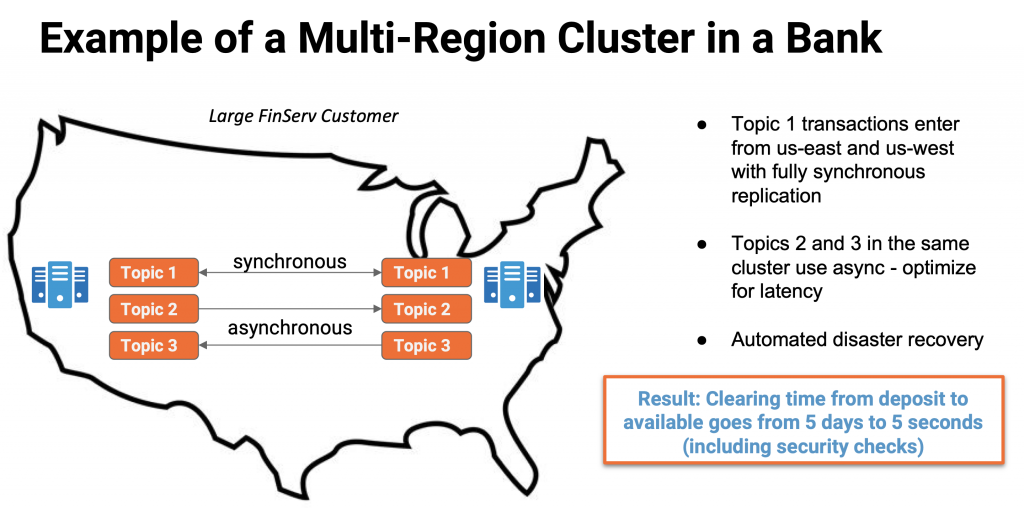
This architecture provides business continuity with RPO = 0 and RTO = 0 as the data is replicated synchronously between US East and US West regions with Kafka-native technologies. This architecture has various advantages, including:
- No need for additional tools
- Automatic fail-over handling of clients (no need for custom client logic)
- No data loss or downtime even in case of disaster
This banking use case was about clearing time from ‘deposit’ to ‘available’ in real time. Exactly the same architecture can be deployed for your mission-critical ML use cases (like fraud detection).
Pretty cool, isn’t it? There is much more to learn about “Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments“.
Kafka + Machine Learning = 24/7 + Real Time
No matter if financial services or any other industry, here are the key lessons learned for implementing scalable, realiable real time ML infrastructures:
- Don’t underestimate the hidden technical debt in Machine Learning systems
- Leverage the Apache Kafka open source ecosystem to build a scalable and flexible real time ML platform
- The market provides some cutting edge solutions helping to deploy Kafka and ML together, like Tiered Storage for Kafka and TensorFlow’s IO Plugin for streaming ingestion into TensorFlow to simplify your big data architecture
What use cases, challenges architectures do you have? Please share your insights and let’s discuss… And let’s connect on LinkedIn to stay in touch!
