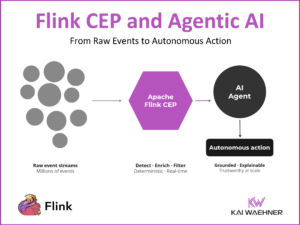
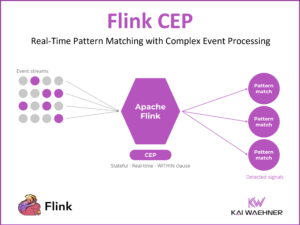
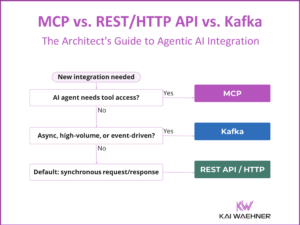
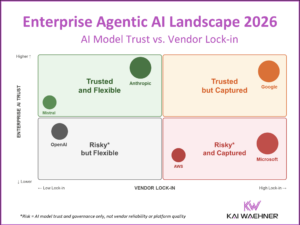
Apache Kafka became the de facto standard for event streaming across the globe and industries. Machine Learning (ML) includes model training on historical data and model deployment for scoring and predictions. While training is mostly batch, scoring usually requires real-time capabilities at scale and reliability. Apache Kafka plays a key role in modern machine learning infrastructures. The next-generation architecture leverages a Kafka-native streaming model server instead of RPC (HTTP/gRPC) calls:
This blog post explores the architectures and trade-offs between three options for model deployment with Kafka: Embedded model into the Kafka application, model server and RPC, model server, and Kafka-native communication.
Kafka and Machine Learning Architecture
Model deployment is usually completely separated from model training (from the process and the technology perspective). The model training is often executed in elastic cloud infrastructure or data lakes such as Hadoop or Spark. Model scoring (i.e., doing the predictions) is usually a mission-critical workload with different uptime SLAs and latency requirements:
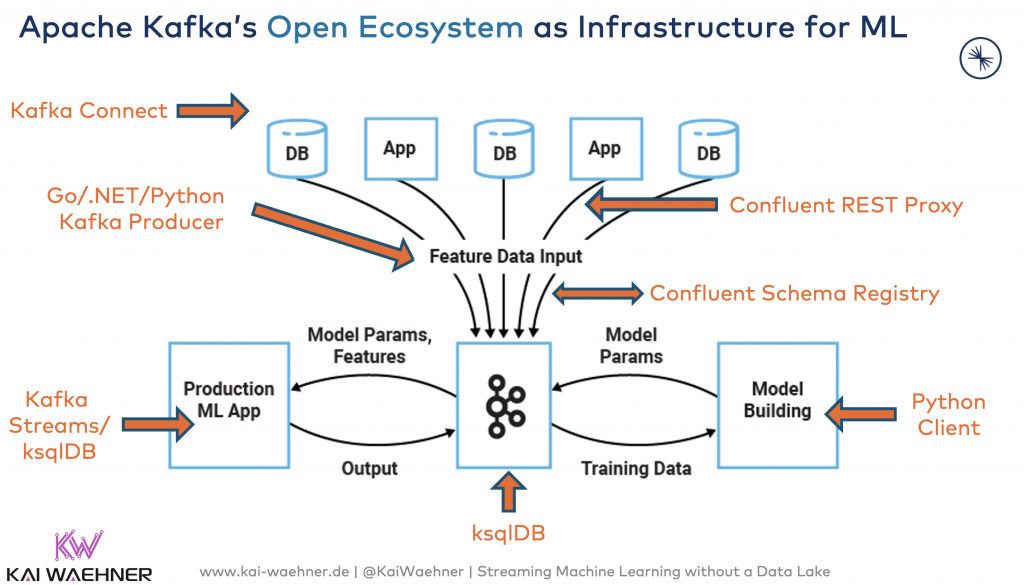
Learn more about this architecture and the relation to modern ML approaches such as Hybrid ML architectures or AutoML in the blog post “Using Apache Kafka to Drive Cutting-Edge Machine Learning“.
Two alternatives for model deployment in Kafka infrastructures: The model can either be embedded into the Kafka application, or it can be deployed into a separate model server. The blog post “Model Server and Model Deployment Options in a Kafka Infrastructure” covers the use cases and architectures in detail and explores some code examples.
The following explores both options’ trade-offs and introduces a third option: A Kafka-native streaming model server.
RPC between Kafka App and Model Server
The analytic model is deployed into a model server. The streaming Kafka application does a request-response call to send the input data to the model and to receive the prediction in return:
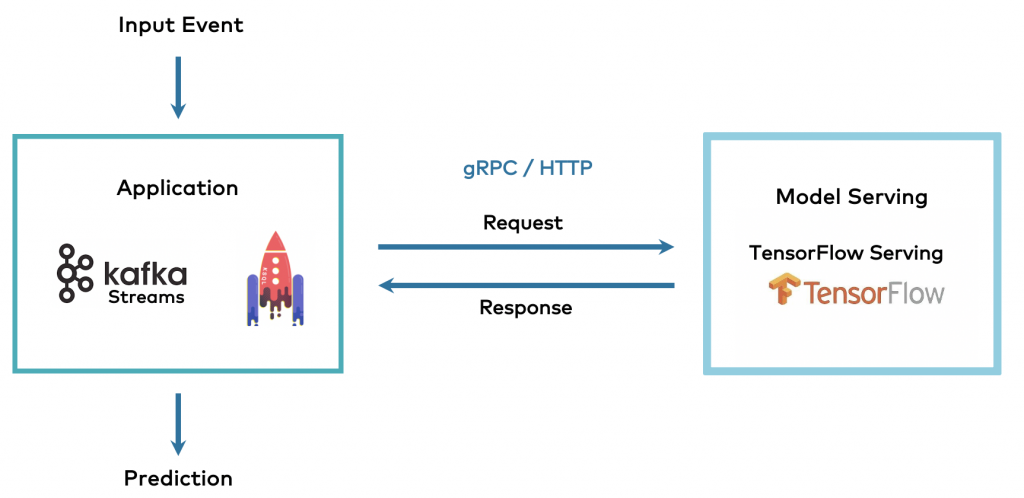
Almost every ML product or framework provides a model server. This includes open-source frameworks such as TensorFlow and the related model server TF Serving, but also proprietory tools such as SAS, AutoML vendors such as DataRobot, and cloud ML services from all major cloud providers such as AWS, Azure, GCP.
Pros and Cons of a Model Server with RPC
Trade-offs using Kafka in conjunction with an RPC-based model server and HTTP/gRPC:
- Simple integration with existing technologies and organizational processes
- Easiest to understand if you come from a non-streaming world
- Tight coupling of the availability, scalability, and latency/throughput between application and model server
- Separation of concerns (e.g. Python model + Java streaming app)
- Limited scalability and robustness
- Later migration to real streaming is also possible
- Model management built-in for different models, versioning, and A/B testing
- Model monitoring built-in
Example: TensorFlow Serving with GRPC and Kafka Streams
An example of this approach is available on Github: “TensorFlow Serving + gRPC + Java + Kafka Streams“. In this case, the TensorFlow model is exported and deployed into a TensorFlow Serving infrastructure.
Embedded Model into Kafka Application
An analytic model is just a binary, i.e., a file stored in memory or persistent storage.
The data type differs and depends on the ML framework. But it does not matter if it is Java (e.g., with H2O), Protobuf (e.g., with TensorFlow), or proprietary (with many commercial ML tools).
Any model can be embedded into a Kafka application (if the ML solution provides programmatic APIs – but almost every tool does):
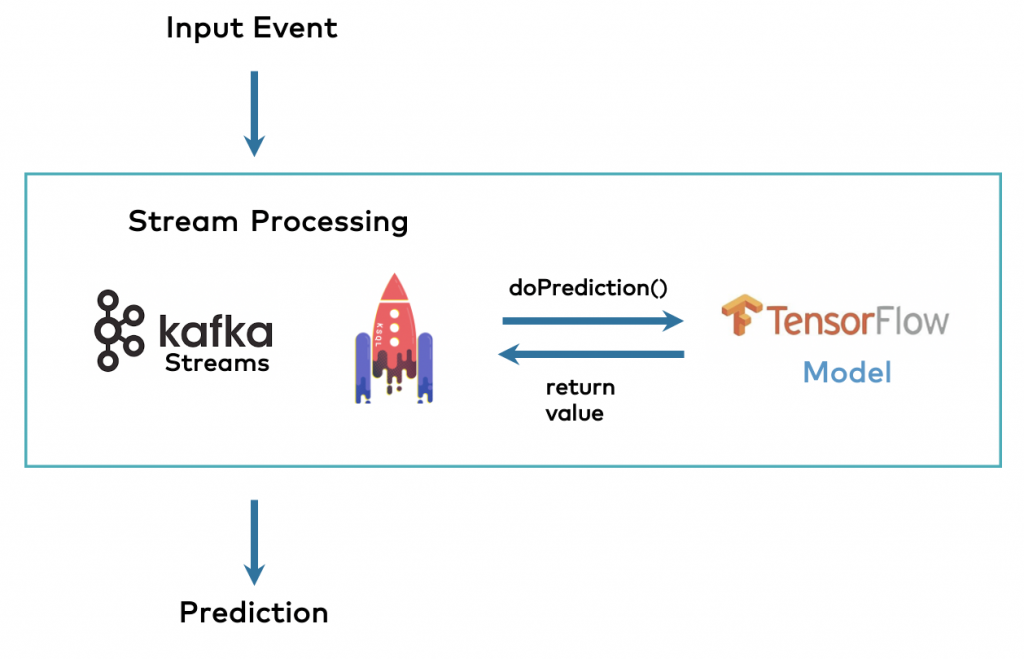
The Kafka application for embedding the model can either be a Kafka-native stream processing engine such as Kafka Streams or ksqlDB, or a “regular” Kafka application using any Kafka client such as Java, Scala, Python, Go, C, C++, etc.
Pros and Cons of Embedding an Analytic Model into a Kafka Application
Trade-offs of embedding analytic models into a Kafka application:
- Best latency as local inference instead of remote call
- No coupling of the availability, scalability, and latency/throughput of your Kafka Streams application
- Offline inference (devices, edge processing, etc.)
- No side-effects (e.g., in case of failure), all covered by Kafka processing (e.g., exactly once)
- No built-in model management and monitoring
Example: Kafka Python Application with Embedded TensorFlow Model
A robust and scalable example of the embedded model approach is presented in Github project “Streaming Machine Learning with Kafka, MQTT, and TensorFlow for 100000 Connected Cars“. This demo uses Python for both model training and model deployment in separate, scalable containers in a Kubernetes infrastructure.
Several other (more simple) demos to try out this approach are available here: “Machine Learning + Kafka Streams Examples“. The examples use TensorFlow, H2O.ai, and DeepLearning4J (DL4J) in conjunction with Kafka Streams and ksqlDB.
Kafka-native Streaming Model Server
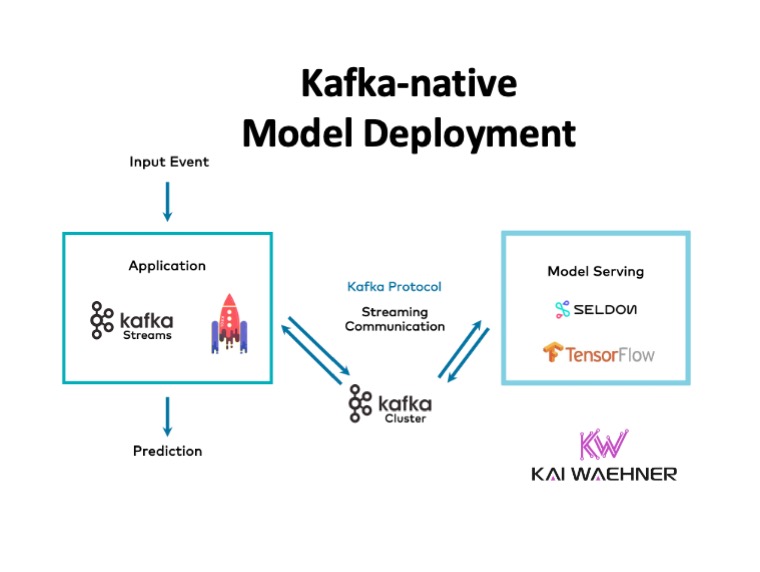
A Kafka-native streaming model server combines some characteristics from both approaches discussed above. It enables the separation of concerns by providing a model server with all the expected features. But the model server does not use RPC communication via HTTP/gRPC and all the drawbacks this creates for a streaming architecture. Instead, the model server communicates via the native Kafka protocol and Kafka topics with the client application:
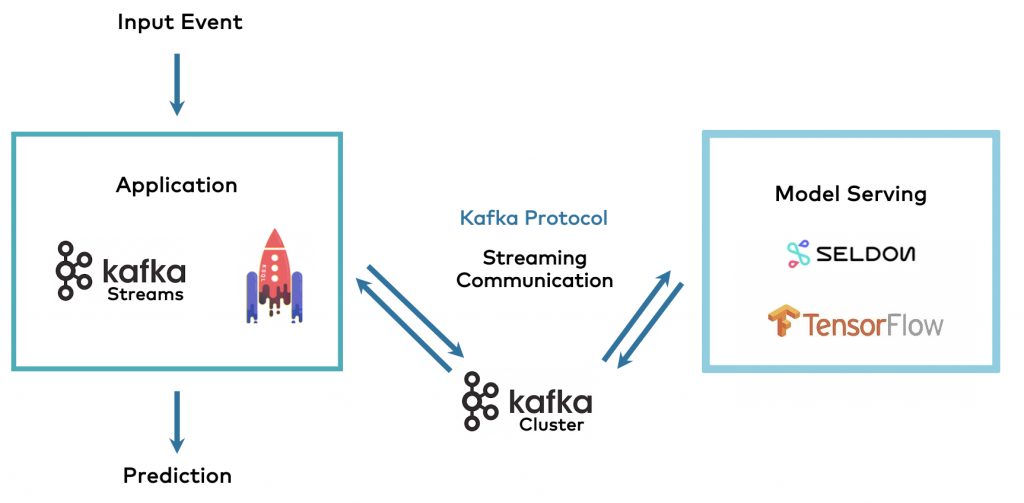
Pros and Cons of a Kafka-native Streaming Model Server
Trade-offs of a Kafka-native streaming model server:
- Good latency via Kafka-native streaming communication
- Some coupling of the availability, scalability, and latency/throughput of your Kafka Streams application
- Some side-effects (e.g., in case of failure), but most potential issues covered by Kafka processing (e.g., decoupling and persistence via Kafka topics)
- Model management built-in for different models, versioning, and A/B testing
- Model monitoring built-in
- Separation of concerns (e.g. Python model + Java streaming app)
- Scalability and robustness of the model server not necessarily Kafka-like (because the underlying implementation is often not Kafka-native yet)
A Kafka-native streaming model server provides many advantages of a streaming architecture and the features of a model server. Just be aware that a Kafka-native interface does NOT mean that the model server itself is implemented with Kafka under the hood. Hence, test your scalability, robustness, and latency requirements to decide if an embedded model might be a better approach.
Example: Streaming Model Deployment with Kafka and Seldon
Seldon is a robust and scalable open-source model server. It allows us to manage, serve, and scale models in any language or framework on Kubernetes.
In mid of 2020, Seldon added a key differentiator compared to many other model servers on the market: Seldon added support for Kafka. Hence, Seldon combines the advantages of a separate model server with the streaming paradigm of Kafka:
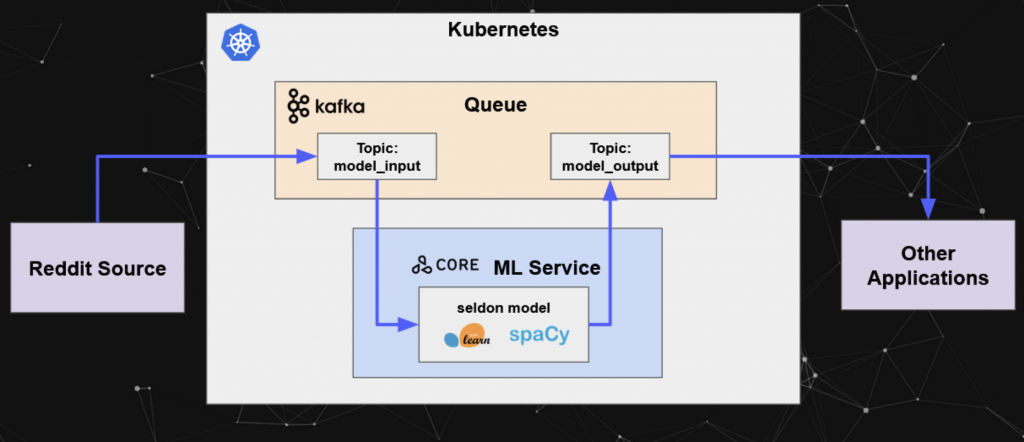
The Jupyter notebook demonstrates this example using scikit-learn, the NLP framework spaCy, Seldon, and Kafka-native integration with producer and consumer applications. Check out the blog post “Real-Time Machine Learning at Scale using SpaCy, Kafka & Seldon Core” for more details.
All Model Deployment Options have Trade-Offs in Streaming Machine Learning Architectures
This blog post covered three alternatives for model deployment in a Kafka infrastructure: A model server with RPC, embedding models into the Kafka application, and a Kafka-native model server. All three have their trade-offs. Know them, and evaluate the right choice for your project. The good news is that it is also pretty straightforward to change from one approach to another one.
UPDATE May 2021: Dataiku also provides a native Kafka interface in the meantime (including support for Schema Registry). Great to see different model servers adopting this architecture.
If you want to learn more details about Kafka-native model deployment, check out the following video recording and slide deck from Kafka Summit:
 The talk does not cover the “streaming model server” approach (because no model server provided a Kafka-native interface in 2019). But you can still learn a lot about the different architectures and best practices.
The talk does not cover the “streaming model server” approach (because no model server provided a Kafka-native interface in 2019). But you can still learn a lot about the different architectures and best practices.
If you want to learn more about “Streaming Machine Learning with Kafka – without another Data Lake“, check out the following video recording and slide deck. It explores a simplified architecture and the advantages of Tiered Storage for Kafka:
What are your experiences with Kafka and model deployment? What are your use cases? Which approach works best for you? What is your strategy? Let’s connect on LinkedIn and discuss it!