Apache Kafka has become the backbone of real-time data streaming in many enterprises. With built-in features for encryption, authentication, and access control, and with additional enterprise capabilities in a complete data streaming platform like Confluent Cloud, Kafka already covers a wide range of security and governance needs.
However, there are a small number of use cases where these built-in capabilities are not enough. Highly regulated industries, multi-tenant SaaS platforms, or platforms exposed to both internal and external clients may require more advanced or more centralized policy enforcement. In these specific scenarios, a Kafka proxy can provide additional controls that are difficult to implement directly in Kafka or would require significant changes to client applications or broker configurations.
A Kafka proxy acts as an intermediary between clients and brokers. It introduces a central enforcement layer for tasks like record-level encryption, tenant isolation, audit logging, and routing. This makes it easier to apply consistent policies across different environments, tenants, or user groups – without changing the core Kafka infrastructure or applications.
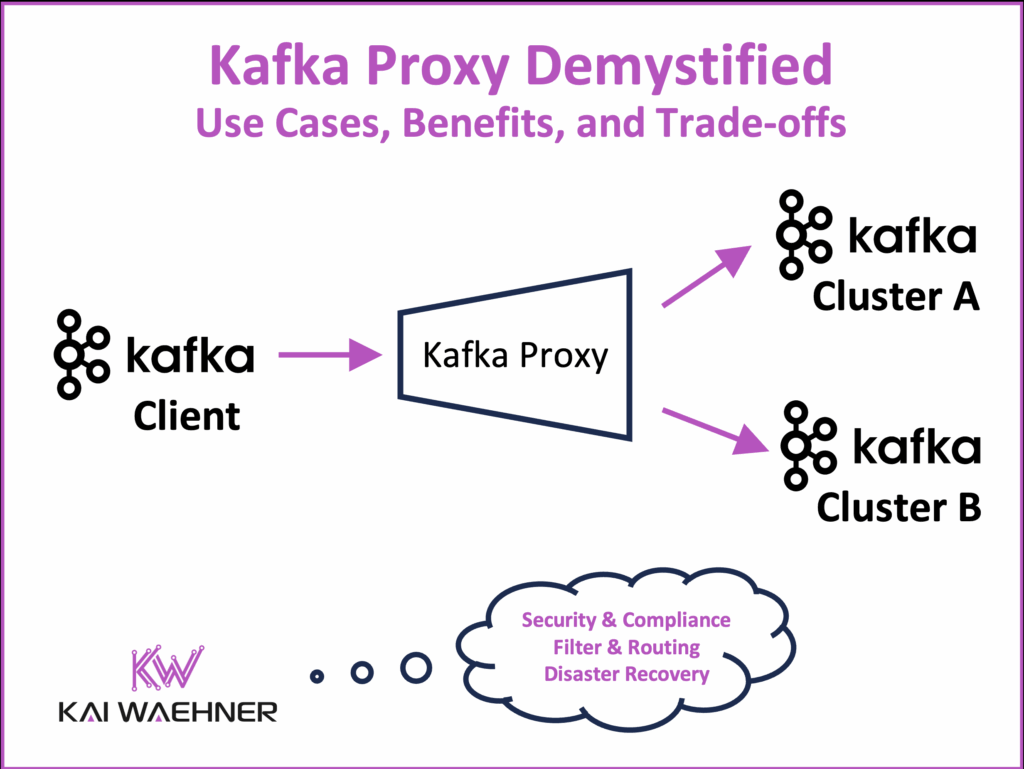
Kafka proxies are not a requirement for every deployment. But when used for the right reasons, they can help address important security, compliance, and governance challenges that Kafka alone may not solve in a clean or scalable way.
API gateways like Kong and API management platforms like Apigee or Mulesoft have been around for many years. They are mature and well established for governing REST APIs. Service meshes such as Envoy or Istio serve a different purpose. While their decentralized setup introduces operational complexity, Envoy has become a common choice for teams managing large fleets of microservices. It is well suited for environments that need fine-grained traffic control, observability, and security between services. That said, this remains a relatively specialized use case. And service meshes are not designed for Kafka’s event-driven protocol. Their focus is on stateless, synchronous communication, which makes them a poor fit for managing long-lived, stateful Kafka connections.
This post explains why Kafka proxies are becoming a key component in modern data streaming architectures. It compares their role to API gateways and service meshes, outlines core use cases, highlights leading solutions, and shares best practices for secure and compliant deployments.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various relevant examples across industries.
Why a Proxy for Apache Kafka?
Apache Kafka has become the standard for data streaming. Many enterprises use it as the central nervous system of their data architecture. But as usage grows, new requirements appear. Compliance, multi-tenant SaaS, and protection against insider threats require stronger security and governance.
A Kafka proxy provides a central enforcement point. It sits between clients and brokers. Applications connect to the proxy, not directly to Kafka. This allows teams to add controls without touching either client code or the Kafka cluster.
This article explores why organizations deploy Kafka proxies. It covers the main use cases, the leading products in the ecosystem, and practical best practices for adoption.
A Kafka Proxy in Action: Secure Record-Level Encryption with Kroxylicious
To get started, let’s look at an example architecture using Kroxylicious for record-level encryption. Kroxylicious is an open-source wire protocol proxy for Apache Kafka. It is backed by Red Hat (now IBM) and developed under the umbrella of the Commonhaus Foundation. While still a relatively young project, it has already built an active community of contributors and users.
In this example, Kroxylicious is used to encrypt Kafka records as they are sent by the client. The proxy applies encryption before the data reaches the Kafka broker, ensuring that even if someone has access to the Kafka cluster (such as an internal operator or a cloud administrator) they cannot inspect the sensitive payloads stored at rest. On the consumer side, the proxy decrypts the records before they are delivered to the application. This setup allows for full end-to-end encryption without modifying the Kafka clients or brokers, and without exposing unencrypted data within the Kafka infrastructure itself.
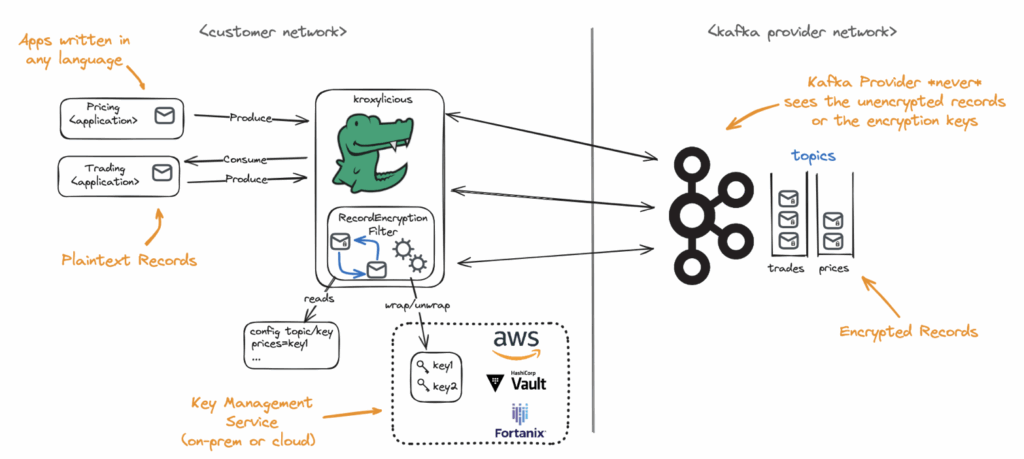
This demonstrates how a Kafka proxy can fit into a modern data streaming architecture, providing stronger security guarantees by adding capabilities that are hard to achieve directly within Kafka.
Key Use Cases for a Kafka Proxy
The main use cases for introducing a Kafka proxy include:
- Schema Validation and Projections: Enforce schema validation at the proxy layer to ensure only compliant records are accepted, and optionally apply projections to reduce or reshape payloads before they reach the broker or consumer.
- Compliance: Meet strict regulations such as PCI DSS or GDPR by enforcing encryption, audit logging, and fine-grained access control.
- Multi-Tenancy: Provide secure namespaces in a shared Kafka cluster, for example in SaaS environments.
- Insider Threat Protection: Ensure sensitive data remains protected even from privileged internal users.
- Managed Entry Point: Abstract Kafka clusters behind a proxy layer, giving clients a simplified and consistent entry point.
- External vs. Internal Access: Enable different authentication mechanisms for external clients than for internal services.
- Custom Domains: Route traffic through custom domains for separate business units or use cases.
- Policy Control per Route: Apply tailored policies (e.g., rate limits, transformations, encryption) per route for greater flexibility and security.
- Multiple Kafka Clusters: Define multiple routes in a single gateway, with each route pointing to a separate Kafka cluster. This enables simplified management of multi-cluster environments.
- Seamless Disaster Recovery & Migration: Support disaster recovery and cluster migration without requiring client-side changes.
- Bridging On-Prem and Cloud Environments: Use the proxy as a controlled access point between Kafka clusters running in different environments, such as on-premises data centers and public cloud, enabling hybrid or phased cloud migrations.
Technical Perspective of a Kafka Proxy
A Kafka proxy introduces an extra layer that decouples governance and security from business logic. It enables platform teams to enforce policies and controls without requiring changes to Kafka clients or brokers.
Proxies can be deployed in different ways depending on the use case:
- Client-side: The proxy runs close to the producer or consumer application. This is often used for capabilities like record-level encryption, where data must be protected before it enters the Kafka cluster.
- Server-side (reverse proxy): The proxy sits in front of the Kafka cluster and acts as a centralized entry point. This is common for tasks such as routing, policy enforcement, multi-tenancy, and traffic shaping.
Key architectural benefits include:
- Decoupling: Developers can keep producing and consuming events without changing their applications. The proxy enforces governance transparently.
- Centralization: Policies for encryption, audit, authentication, and access control are managed in one place.
- Flexibility: Security and routing rules can be updated independently of the Kafka cluster or client deployments, which simplifies operations and reduces risk.
Overview of Kafka Proxy Options
Kafka proxies are becoming an important category in the data streaming ecosystem. They address security, compliance, and governance needs that Kafka itself does not solve out of the box. Both open source and commercial options are available today.
Open Source and Commercial Kafka Proxies
Several Kafka proxy projects exist with different focus areas, deployment options, and licensing strategies:
- Kroxylicious: Open source, filter-based design. Supports encryption, multi-tenancy, policy enforcement, and audit. Proxy only, Kafka infrastructure is separate.
- Grepp Labs: Inspired by the design of Google’s Cloud SQL Proxy. This open source Kafka Proxy enables services to connect to Kafka brokers without managing SASL/PLAIN authentication or SSL certificates manually.
- Confluent Private Cloud (CPC): Based on Kroxylicious, this product provides various built-in proxy features. Proxy and Kafka infrastructure as part of the complete data streaming platform.
- Conduktor Gateway: Commercial solution with a focus on governance, security, and observability. Proxy only, Kafka infrastructure is separate.
- Other Approaches: Some vendors and open source communities have explored running Kafka traffic through general-purpose infrastructure tools. For example, the Envoy Kafka filter project attempts to extend Envoy’s support to the Kafka protocol. However, adoption has been limited, as these tools were not originally designed for Kafka’s binary, stateful, event-driven protocol and often lack the semantics required for robust Kafka governance.
Make sure to evaluate the frameworks, solutions, and vendors based on your requirements. Here are some best practices to keep in mind when evaluating a Kafka Proxy deployment.
Best Practices for Kafka Proxies
A few principles have proven useful when deploying Kafka proxies:
- Filter chain: Compose multiple filters for different tasks, such as encryption, audit, and policy checks.
- Pass-through design: If no filters are active, traffic should flow with minimal parsing for maximum performance.
- Simplicity: Avoid deploying separate proxies. Some enterprises operate multiple Kafka clusters, often a mix of open source Kafka, Amazon MSK, and Confluent. Running separate governance layers for each increases complexity and leads to policy fragmentation. A better approach is to allow the proxy to register and manage external Kafka clusters as metadata assets. This creates a unified source of truth for governance and discovery, even across hybrid or multi-cloud environments.
- Stateless vs. stateful: Stateless capabilities, such as routing or encryption, fit naturally into a proxy because they require no coordination and scale out horizontally. Stateful logic, on the other hand, adds operational complexity and limits scalability. For applications that need to scale, the best practice is to avoid placing stateful logic in the proxy and keep it in dedicated downstream systems, like a stream processing application using Apache Flink. For example, joining two Kafka topics to enrich event streams requires maintaining state over time and is better handled by Flink or Kafka Streams rather than in the proxy layer.
- Do not implement business logic: Keep proxies focused on infrastructure-level concerns. Application transformations belong elsewhere.
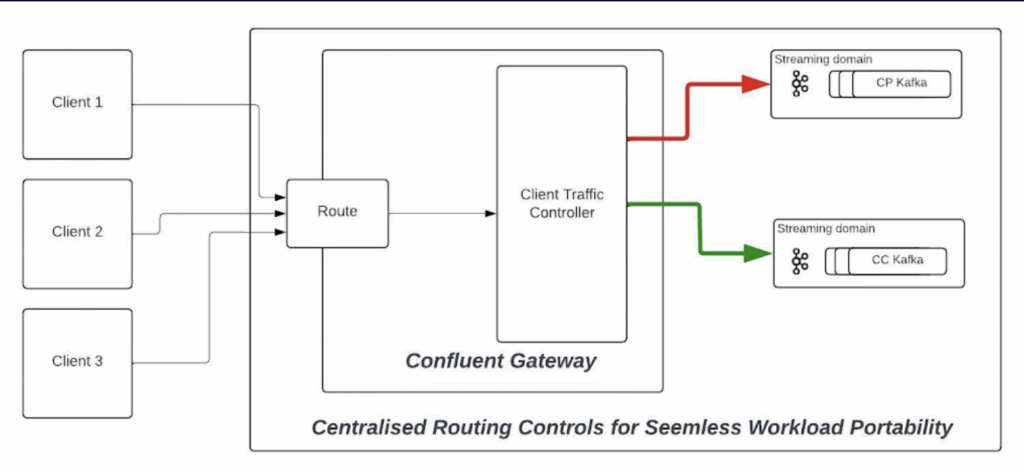
Here is an example architecture using Confluent Private Cloud’s Kafka proxy for a client switchover from a self-managed Confluent Platform cluster to a serverless Confluent Cloud cluster for disaster recovery:
Trade-offs and Risks – When (Not) to Use a Kafka Proxy
Kafka proxies add value, but they also introduce complexity. Key considerations include:
- Additional latency: A proxy adds an extra network hop between clients and brokers, which can slightly increase end-to-end latency.
- High availability requirements: Proxies must be deployed in a highly available and horizontally scalable way. Otherwise, they risk becoming a single point of failure.
- Operational overhead: Introducing a proxy adds another component to monitor, maintain, and troubleshoot. With more code in the critical path, there is more potential for bugs or unexpected behavior.
- Centralized enforcement: While powerful, centralizing control increases the blast radius of misconfigurations, bugs, or failures.
- Security exposure: Proxies operate in an extremely privileged position. They can inspect message batches, apply transformations, and enforce policies. This makes them a potential attack surface and a sensitive component from a security architecture perspective.
- Early maturity in some areas: Certain features, such as fine-grained multi-tenancy, are still evolving and may not yet be production-ready in all proxy implementations.
Kafka Proxy vs. API Management vs. Service Mesh
Kafka proxies, API gateways, service meshes, and AsyncAPI are often mentioned in the same breath, but they solve very different problems. Understanding their roles is essential to avoid forcing the wrong tool onto the wrong job.
API gateways manage synchronous REST traffic. Service meshes handle service-to-service communication at the network layer. Kafka proxies enforce governance and security for event streams.
AsyncAPI, meanwhile, is not a runtime component but a specification format used to document and design asynchronous APIs. It complements event-driven systems like Kafka by improving clarity and consistency, but it does not replace the need for a robust streaming platform or runtime governance layer.
Kafka Protocol vs. HTTP / REST
Kafka uses a binary protocol designed for high-throughput, low-latency event streaming. It is stateful by nature: producers send events to topics, consumers track offsets, and brokers coordinate partition assignment. This protocol enables scalable publish/subscribe communication and guarantees like ordering within partitions.
HTTP and REST, in contrast, are stateless request-response protocols. An HTTP gateway is excellent for synchronous APIs where a client makes a call and immediately receives a response. Gateways like Mulesoft or Apigee provide governance for REST traffic, such as authentication, routing, throttling, and caching, but they operate at the level of single requests.
A Kafka proxy is different because it understands the semantics of streaming:
- It can inspect topics, partitions, consumer groups, and offsets.
- It supports continuous streams of events, not one-off requests.
- It can enforce policies such as record encryption, tenant isolation, or filtering at the event level.
An HTTP gateway cannot provide these guarantees. It does not understand Kafka’s coordination protocol, offset management, or partitioning.
For a deeper discussion of how REST/HTTP and Kafka differ fundamentally, see Request-Response with REST/HTTP vs. Data Streaming with Apache Kafka. This article highlights why event streaming requires a different architectural approach, and why Kafka proxies are built protocol-aware, not protocol-agnostic.
Kafka Proxy vs. API Management Products
API management platforms such as Mashery, Mulesoft, Apigee, or Kong are built for REST APIs. Their main role is to manage request-response traffic. They handle tasks like authentication, authorization, throttling, caching, and routing. This is critical for synchronous workloads where clients expect an immediate response.
Kafka, by design, is optimized for asynchronous, event-driven communication. That said, some teams implement synchronous request-response workflows on top of Kafka by using two topics, one for requests and another for responses. The client sends a message to the request topic and waits for a correlated reply on the response topic. While technically possible, this is considered an anti-pattern. It introduces tight coupling, complicates retry handling, and undermines the scalability benefits of event streaming. It appears in practice, but should be avoided where possible.
Kafka proxies serve a similar purpose like API Management platforms, but in a streaming-first architecture. Instead of handling one-off requests, they govern continuous flows of events. A Kafka proxy can:
- Intercept and filter records in real time
- Enforce policies on topics, partitions, and consumer groups
- Manage encryption and audit without changing client applications
- Understand stateful streaming concerns like offsets and ordering
This is a fundamental difference. API gateways do not speak Kafka’s binary protocol. They cannot manage offset tracking, partition assignment, or message ordering. A Kafka proxy, by contrast, is designed for the semantics of event-driven systems.
Think of it this way:
- API Management = Governance for synchronous REST APIs
- Kafka Proxy = Governance for asynchronous event streams
Both patterns are complementary. Many enterprises need both because they expose REST APIs externally while relying on Kafka internally. The governance mechanisms, however, must be tailored to the protocol and communication style.
For a detailed comparison of API gateways and Kafka as integration layers, see API Management vs. Apache Kafka. The article is already five years old, yet the concepts it covers remain fully valid. Organizations should still avoid trying to force-fit one technology into the other’s role.
Some API management vendors, such as Kong or Gravitee, have added support for the Kafka protocol to its API Gateway. However, there has not been wide adoption or meaningful evolution of this combination. Most organizations still separate API management for HTTP from Kafka-specific governance.
The other way round is a bit easier: A Kafka-based Data Streaming Platform like Confluent provides REST APIs and ready-to-use connectors. This approach allows API requests for producing or consuming data to be seamlessly integrated on top of the event-driven infrastructure. It combines the best of synchronous API access with the power of continuous event streams.
Kafka Proxy vs. Service Mesh
Service meshes such as Envoy with Istio or Linkerd were once a hot topic in the software engineering community. A few years ago, many expected them to become the default way of managing microservice-to-microservice communication. In practice, adoption has been far slower. Most organizations realized that the operational overhead was high, the benefits often limited, and that developers preferred to standardize on just a few core protocols such as HTTP for synchronous APIs and Kafka for event streaming.
A service mesh is decentralized. It deploys sidecar proxies next to every application or database instance. These sidecars handle networking concerns: service discovery, retries, routing, observability, and mTLS. The value is in providing uniform service-to-service communication, regardless of the application’s language or framework.
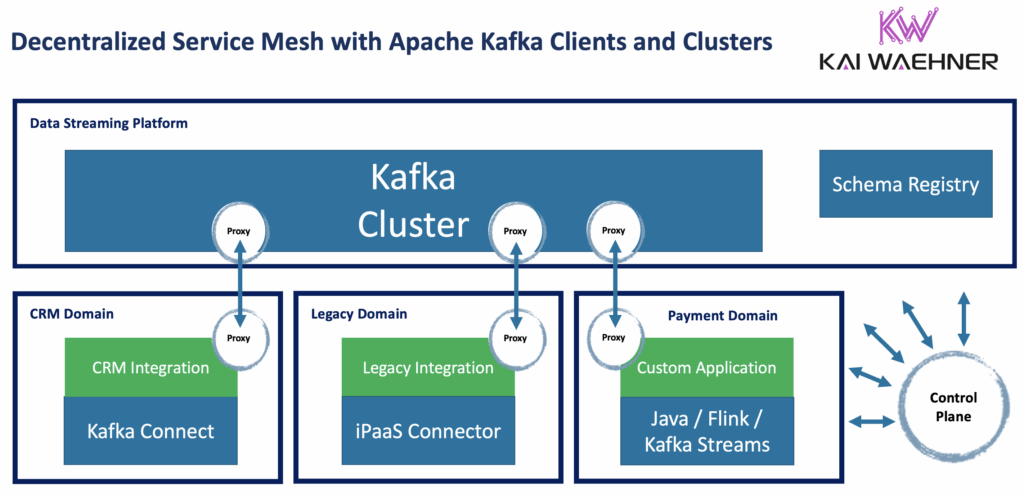
A Kafka proxy is typically centralized, running as a dedicated tier in front of the Kafka cluster. Its role is not generic networking but Kafka-specific governance and enforcement. It understands the Kafka protocol, topics, partitions, and consumer groups, enabling it to implement controls like record encryption, tenant isolation, or policy enforcement at the event level.
That said, not all Kafka proxies are deployed centrally. In some cases, such as record-level encryption or migration between clusters, a proxy may run client-side, close to the producer or consumer. This approach enables sensitive logic to be applied before data enters the Kafka infrastructure. Even in these cases, the configuration and policy management of the proxy fleet can still be centralized for consistency and control.
While Envoy can technically route Kafka’s TCP traffic, it has no understanding of Kafka semantics. It operates at the transport and network layers (Layers 4 and below in the OSI model), but Kafka governance requires visibility at the application layer (Layer 7), where topics, partitions, consumer groups, and message contents are understood. Envoy cannot manage offsets, preserve ordering, or enforce policies at the streaming layer. This is why Kafka is almost never run “inside” a service mesh. Instead, organizations separate concerns: HTTP traffic flows through a service mesh or API gateway, while Kafka traffic is handled by a Kafka proxy that operates at the protocol and application layer, where it can apply streaming-aware governance and control.
For more context, see Cloud-Native Apache Kafka on Kubernetes with Envoy, Istio, and Linkerd Service Mesh. That article highlights early experiments with combining Kafka and service meshes — and why, in the end, most enterprises chose to simplify by standardizing on HTTP and Kafka as independent but complementary and integrated protocols for data sharing.
AsyncAPI and Kafka: Bridging API Design and Event Streaming
As event-driven architectures gain adoption, many teams look for ways to design and document their asynchronous communication patterns. AsyncAPI has become the leading standard for describing event-based APIs, much like OpenAPI is used for REST. It helps define topics, schemas, and message formats in a consistent, machine-readable format.
AsyncAPI provides native support for Apache Kafka, which makes it a natural fit for describing event-driven architectures. Kafka is inherently asynchronous and built around a publish-subscribe pattern, where producers send events to topics and consumers process them independently. With AsyncAPI, teams can clearly define these interfaces, making it easier to develop, test, and onboard new services.
However, adding AsyncAPI support is not enough. Many platforms stop at syntax-level compatibility without offering the scale, reliability, and governance needed for production use. Documenting an event stream is useful, but it does not replace critical features like schema validation, data lineage, tenant isolation, or disaster recovery. While most platforms today support REST and events separately, there are still no products that offer a unified design experience for both synchronous and asynchronous APIs.
Kafka Support for AsyncAPI in Confluent Cloud
Let’s explore a concrete example: Confluent Cloud supports this approach through tools and open standards that integrate with AsyncAPI workflows. For example, developers can define AsyncAPI contracts and generate client code or documentation that matches the underlying Kafka topics and schemas in the platform.
A key component in this flow is the Schema Registry, which manages the schemas associated with Kafka topics. When an AsyncAPI document is exported from Confluent Cloud, it includes references to both the Kafka cluster and the Schema Registry cluster, along with topic configurations, compatibility rules, and tagged metadata. This enables teams to version and govern their event definitions centrally, while tools like the Confluent CLI allow importing these specs back into the platform to configure topics and schemas programmatically. This makes schema evolution and governance a seamless part of the API lifecycle.
The Future of Secure and Compliant Data Streaming
Kafka proxies are a growing category. They address problems that native open source Apache Kafka does not solve out of the box: compliance, data protection, and centralized governance. Unlike service meshes or API gateways, they are protocol-aware and focused on Kafka-specific semantics.
Most organizations will not need a Kafka proxy on day one. But for regulated industries, SaaS providers, or large-scale platforms, the value is clear. Expect this space to evolve quickly. Kroxylicious, Conduktor, and Confluent are leading the way. These proxy capabilities are designed to close key operational and architectural gaps: simplifying credential management, hiding broker topology, enabling fine-grained authorization, and supporting use cases like tenant isolation or outbound-only connections.
Future blogs will go deeper into the different proxy implementations, their architectures, and real-world use cases. Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various relevant examples across industries.