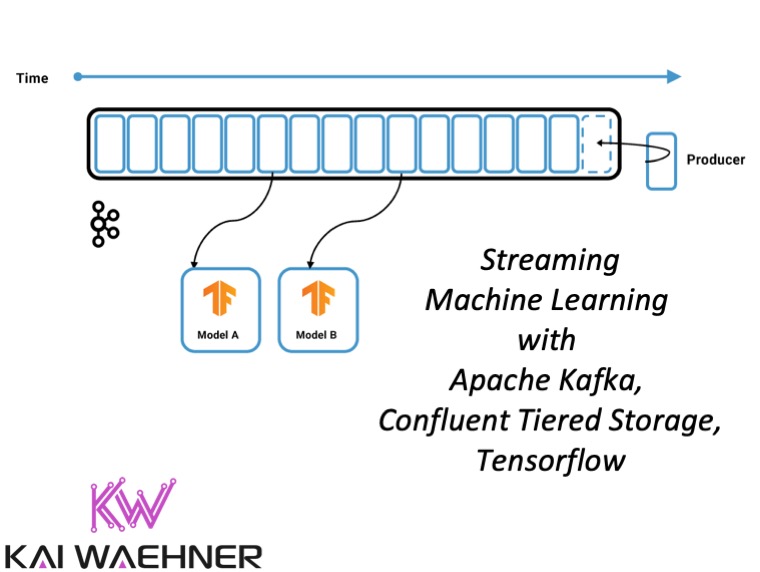
The combination of streaming machine learning (ML), Apache Kafka and Confluent Tiered Storage enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem and Confluent Platform.
This blog post is a primer for the full article I wrote for the Confluent Blog:
Streaming Machine Learning with Tiered Storage and Without a Data Lake
Agenda
Please read the full blog post for all details with the following agenda:
- The old way: Kafka as an ingestion layer into a data lake
- The new way: Kafka for streaming machine learning without a data lake
- Streaming machine learning at scale with the Internet of Things (IoT), Kafka, and TensorFlow
- Kafka is not a data lake, right?
- Confluent Tiered Storage
- Data ingestion, rapid prototyping, and data preprocessing
- Model training and model management both with or without a data lake
- Model deployment for real-time predictions
- Real-time monitoring and analytics
The connected car example I use to enable predictive maintenance in real time is discussed and demo’ed in this post:
IoT Live Demo – 100.000 Connected Cars with Kubernetes, Kafka, MQTT, TensorFlow
The following two sections explain the main concepts: Streaming Machine Learning and Tiered Storage as add-on for Apache Kafka.
Apache Kafka for streaming machine learning without a data lake
Let’s take a look at a new approach for model training and predictions that do not require a data lake. Instead, streaming machine learning is used: direct consumption of data streams from Confluent Platform into the machine learning framework.
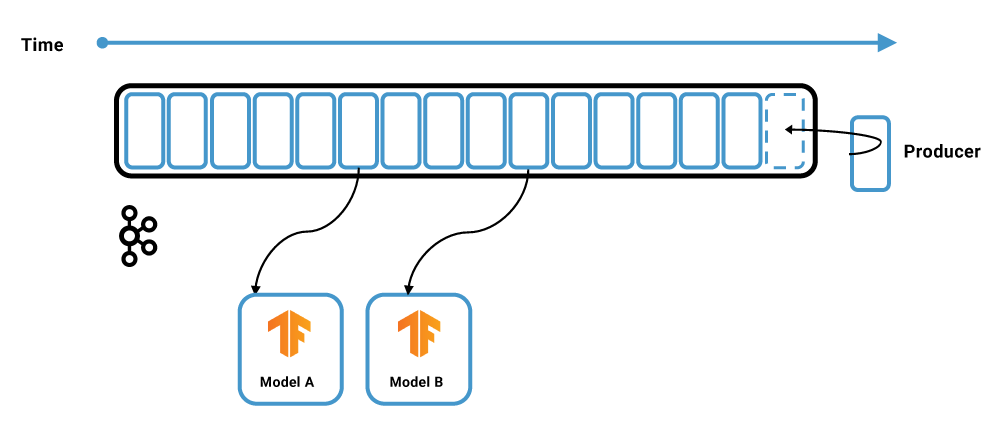
This example features the TensorFlow I/O and its Kafka plugin. The TensorFlow instance acts as a Kafka consumer to load new events into its memory. Consumption can happen in different ways:
- In real time directly from the page cache: not from disks attached to the broker
- Retroactively from the disks: this could be either all data in a Kafka topic, a specific time span, or specific partitions
- Falling behind: even if the goal might always be real-time consumption, the consumer might fall behind and need to consume “old data” from the disks. Kafka handles the backpressure
Most machine learning algorithms don’t support online model training today, but there are some exceptions like unsupervised online clustering. Therefore, the TensorFlow application typically takes a batch of the consumed events at once to train an analytic model.
Confluent Tiered Storage
At a high level, the idea is very simple: Tiered Storage in Confluent Platform combines local Kafka storage with a remote storage layer. The feature moves bytes from one tier of storage to another. When using Tiered Storage, the majority of the data is offloaded to the remote store.
Here is a picture showing the separation between local and remote storage:
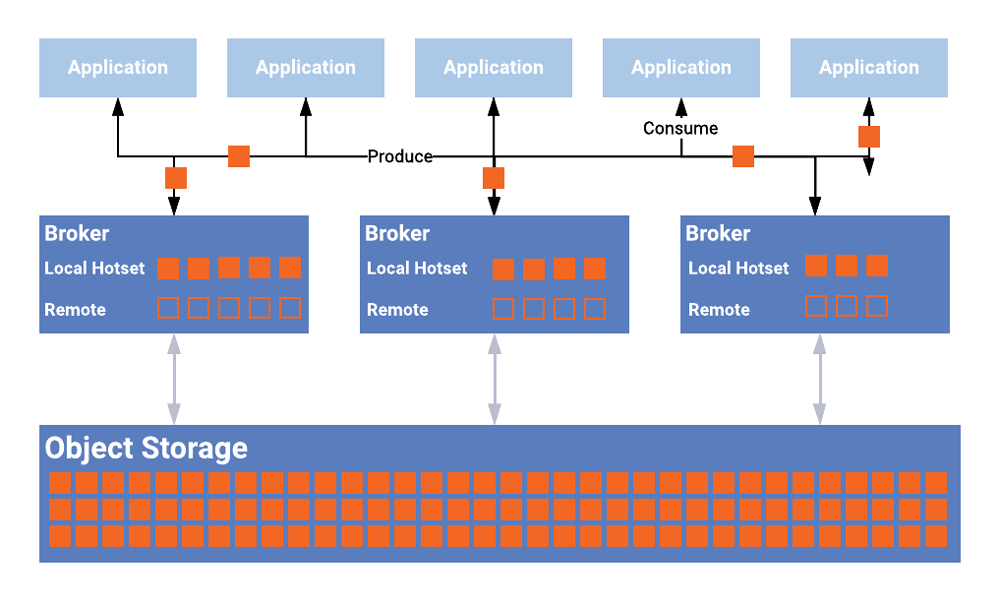
Tiered Storage allows the storage of data in Kafka long-term without having to worry about high cost, poor scalability, and complex operations. You can choose the local and remote retention time per Kafka topic. Another benefit of this separation is that you can now choose a faster SSD instead of HDD for local storage because it only stores the “hot data,” which can be just a few minutes or hours worth of information.
In the Confluent Platform 5.4-preview release, Tiered Storage supports the S3 interface. However, it is implemented in a portable way that allows for added support of other object stores like Google Cloud Storage and filestores like HDFS without requiring changes to the core of your implementation. For more details about the motivation behind and implementation of Tiered Storage, check out the blog post by our engineers.
Why Tiered Storage as add-on for Apache Kafka?
Storing data long-term in Kafka allows you to easily implement use cases in which you’d want to process data in an event-based order again:
- Replacement/migration from an old to a new application for the same use case; for example, The New York Times can create a completely new website simply by making the desired design changes (like CSS) and then reprocessing all their articles in Kafka again for re-publishing under the new style
- Reprocessing data for compliance and regulatory reasons
- Adding a new business application/microservice that is interested in some older data; for instance, this could be all events for one specific ID or all data from the very first event
- Reporting and analysis of specific time frames for parts of the data using traditional business intelligence (BI) tools
- Big data analytics for correlating historical data using machine learning algorithms to find insights that shape predictions
I am really excited about Tiered Storage as add-on for Apache Kafka. What do you think? What are the use cases you see? Please let me know and share your feedback via LinkedIn, Twitter or Email.





