Hybrid cloud architectures are the new black for most companies. A cloud-first is obvious for many, but legacy infrastructure must be maintained, integrated, and (maybe) replaced over time. Event Streaming with the Apache Kafka ecosystem is a perfect technology for building hybrid replication in real-time at scale.

App Modernization and Streaming Replication with Apache Kafka at Bayer
Most enterprises require a reliable and scalable integration between legacy systems such as IBM Mainframe, Oracle, SAP ERP, and modern cloud-native applications like Snowflake, MongoDB Atlas, or AWS Lambda.
Application modernization benefits from the Apache Kafka ecosystem for hybrid integration scenarios. The pharmaceutical and life sciences company Bayer AG is a great example of a hybrid multi-cloud infrastructure. They leverage the Apache Kafka ecosystem as “middleware” to build a bi-directional streaming replication and integration architecture between on-premises data centers and multiple cloud providers:
Learn about Bayer’s journey and how they built their hybrid and multi-cloud Enterprise DataHub with Apache Kafka and its ecosystem: Bayer’s Kafka Summit talk.
Hybrid Cloud Architectures with Apache Kafka
I already explored “architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments” in 2020:
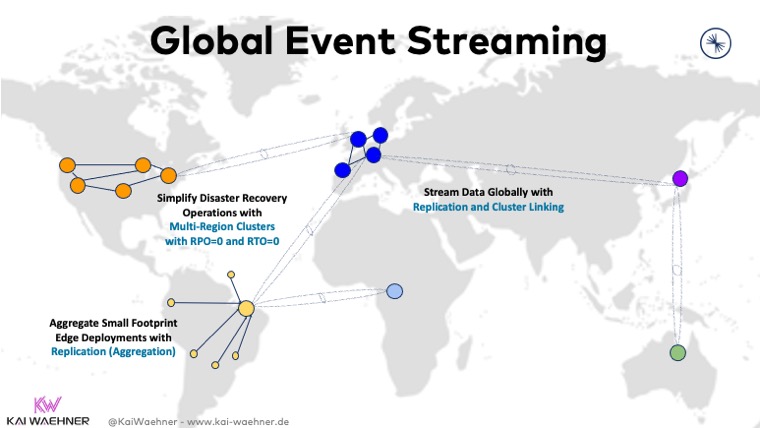
TL;DR: Various alternatives exist to deploy Apache Kafka across data centers, regions, and even continents. There is no single best architecture. It always depends on characteristics such as RPO / RTO, SLAs, latency, throughput, etc.
Some deployments focus on on-prem to cloud integration. Others link together Kafka clusters on multiple cloud providers. Technologies such as Apache Kafka’s MirrorMaker 2, Confluent Replicator, Confluent Multi-Region-Clusters, and Confluent Cluster Linking help building such an infrastructure.
Video and Live Demo of Hybrid Replication with Kafka
The following video recording discusses hybrid Kafka architectures in more detail. The focus is on the bi-directional replication between on-prem and cloud to modernize the infrastructure, integrate legacy with modern applications, and move to a more cloud-native architecture with all its benefits:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
If you want to see the live demo, go to minute 14:00. The demo shows the real-time replication between a Kafka cluster on-premise and Confluent Cloud, including stream processing with ksqlDB and data integration with Kafka Connect (using the fully-managed AWS S3 connector).
The live demo uses AWS, but the same architecture is possible on Azure and GCP, of course. Even more exciting is the option to use on-prem products from the cloud vendors, such as AWS Outpost or Google Anthos. As another example, currently, I am working with colleagues from Confluent and the AWS Wavelength team on a live demo for 5G use cases such as smart factories and connected vehicles. Apache Kafka’s beauty is the freedom to choose the right architecture and infrastructure for your use case!
Summary
Hybrid cloud architectures are the new black for most companies. Consequently, event streaming with the Apache Kafka ecosystem is a perfect technology for building hybrid replication in real-time at scale. It is battle-tested across industries and regions. Leverage Kafka to build a modern and cloud-native infrastructure with on-premise, cloud, and edge workloads!
What are your experiences and plans for building hybrid architectures? Did you already build infrastructure with Apache Kafka to connect your legacy and modern applications? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.