A2A
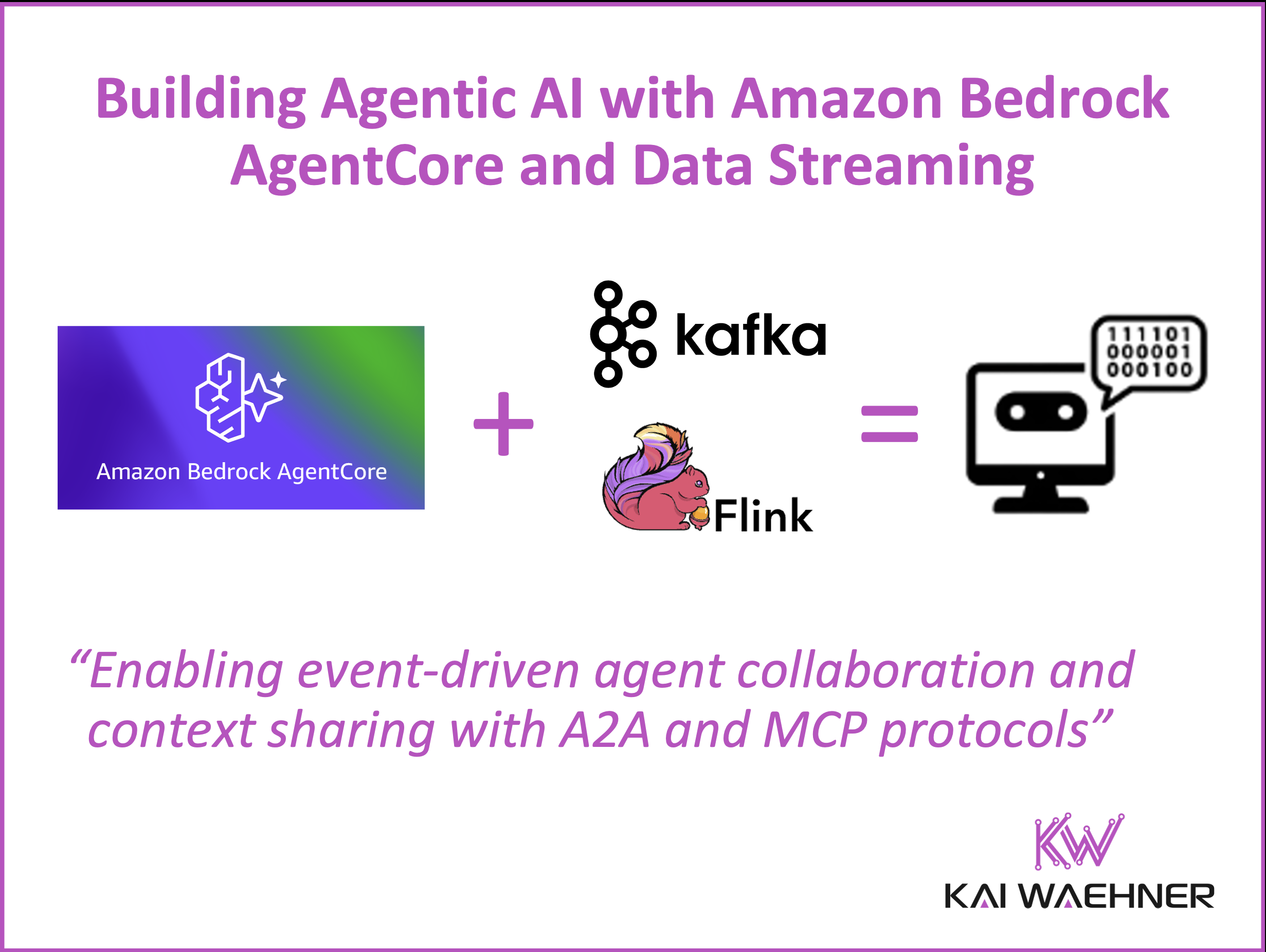
Agentic AI goes beyond chatbots. These are autonomous systems that observe, reason, and act—continuously and in real time. At AWS Summit New York 2025, Amazon

Agentic AI goes beyond chatbots. These are autonomous systems that observe, reason, and act—continuously and in real time. At AWS Summit New York 2025, Amazon
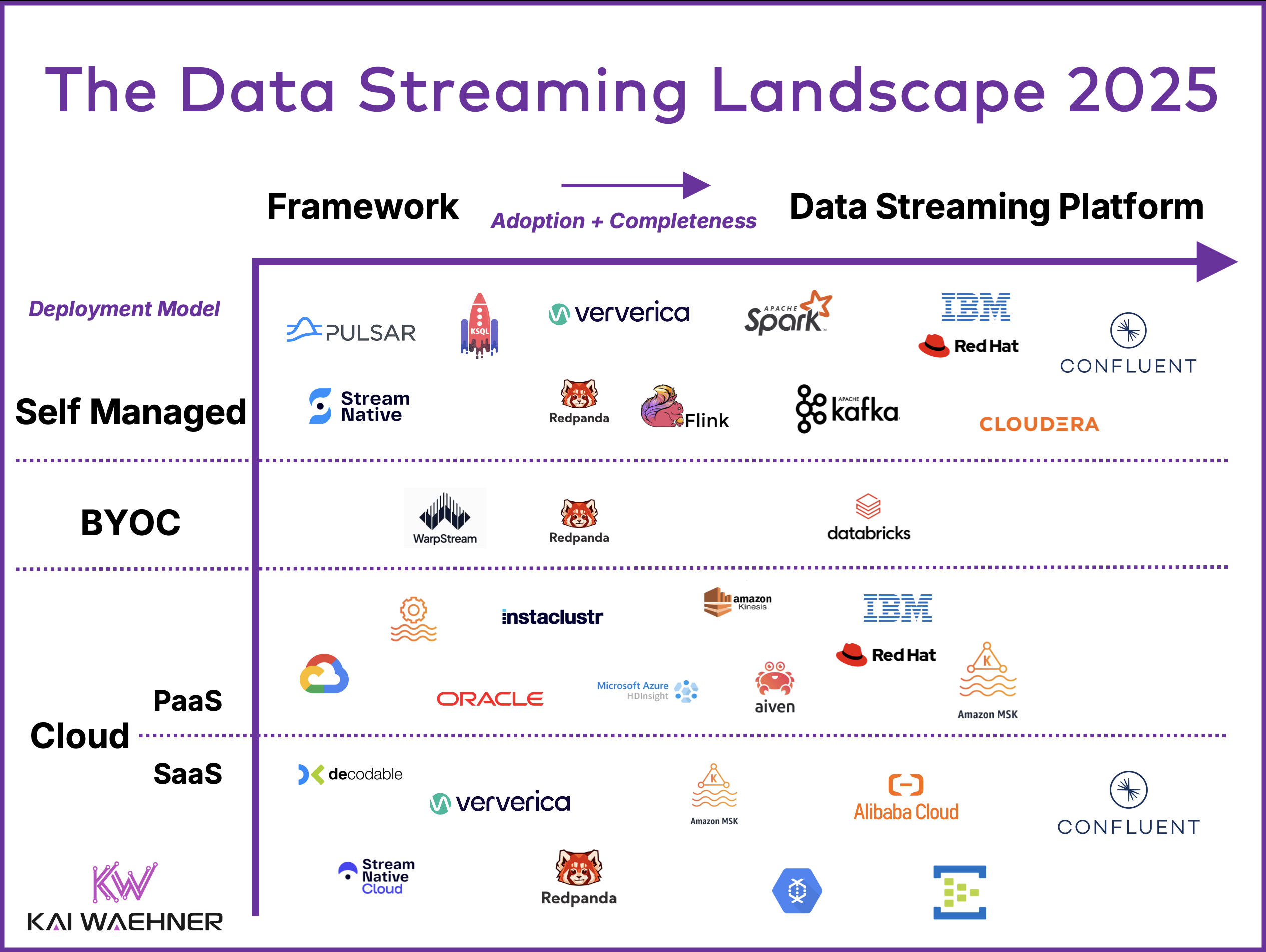
Data streaming is a new software category. It has grown from niche adoption to becoming a fundamental part of modern data architecture, leveraging open source

Apache Kafka and Apache Flink are leading open-source frameworks for data streaming that serve as the foundation for cloud services, enabling organizations to unlock the
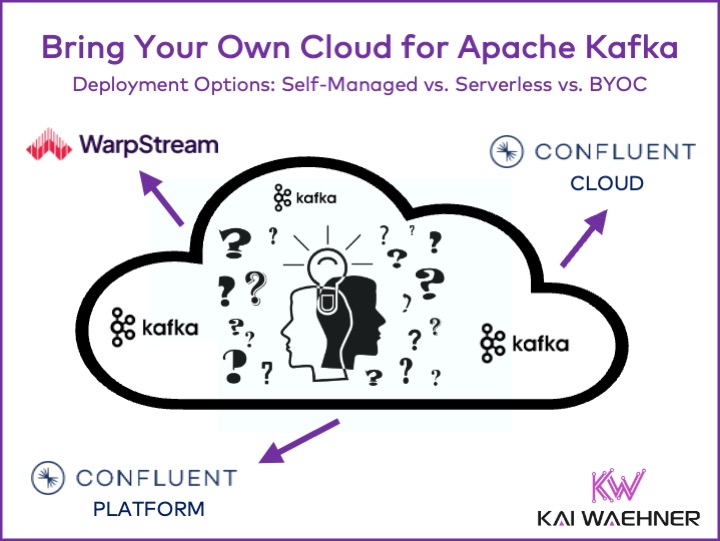
BYOC (Bring Your Own Cloud) is an emerging deployment model for organizations looking to maintain greater control over their cloud environments. Unlike traditional SaaS models,
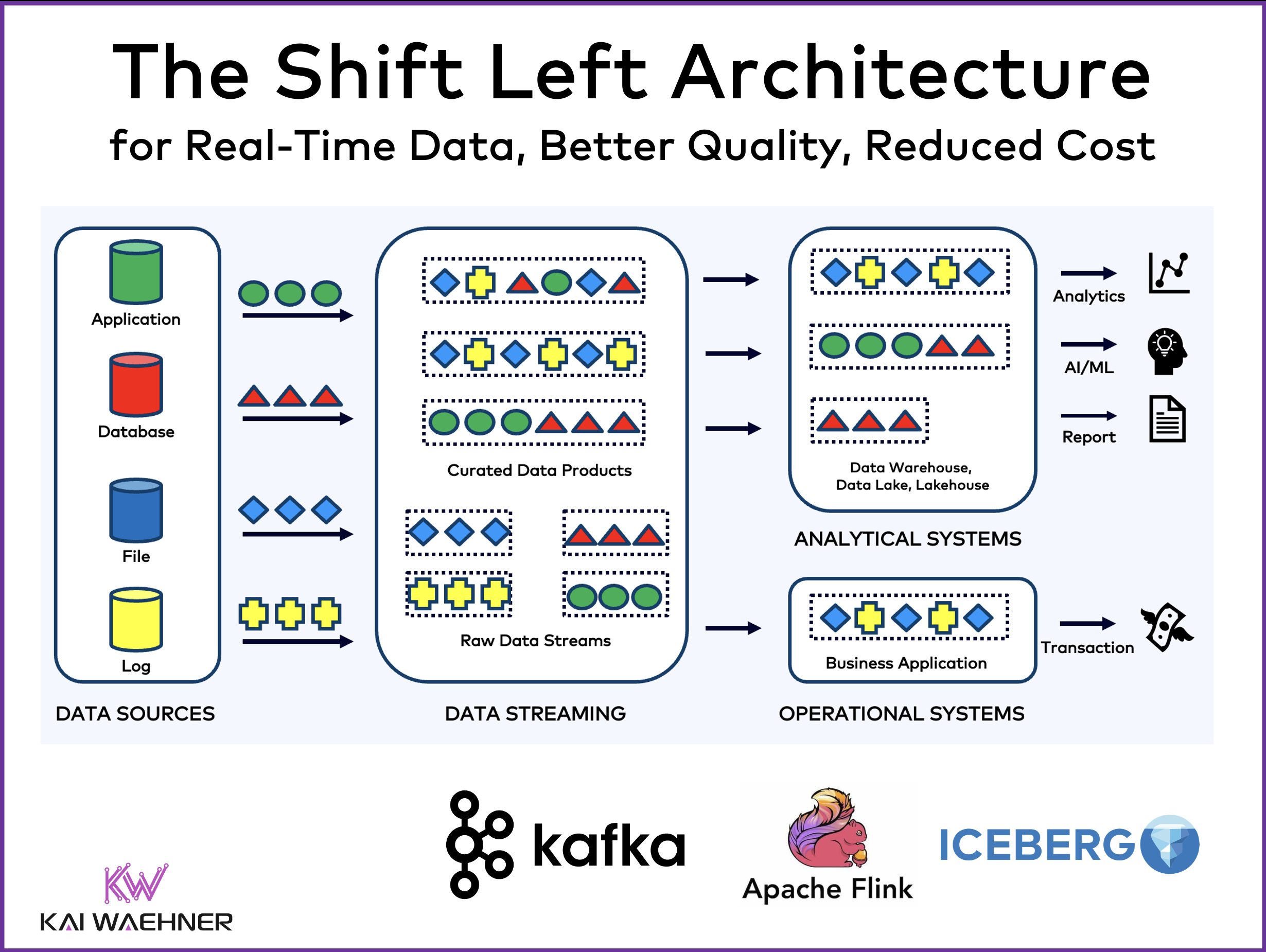
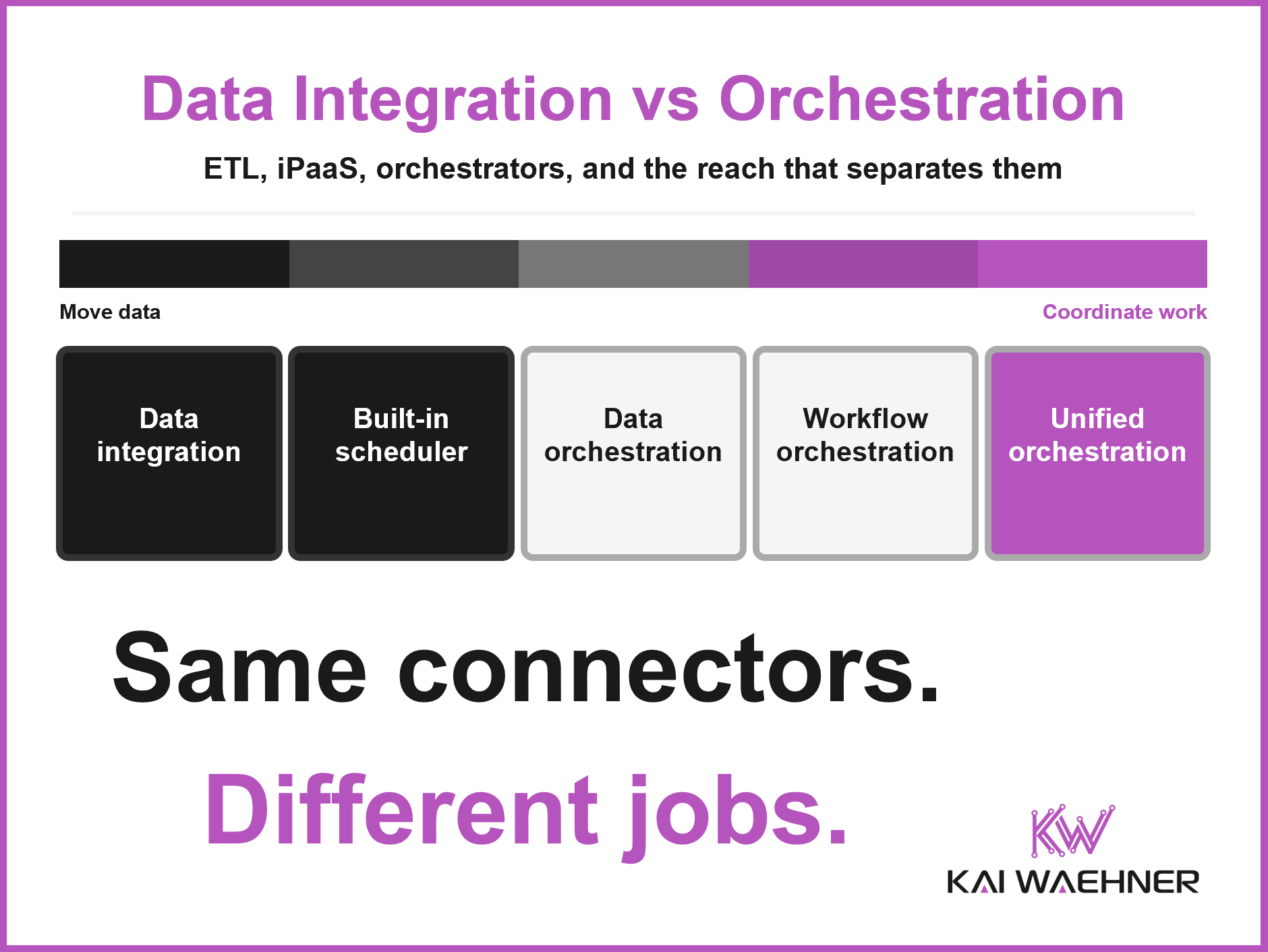
Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.

Data Streaming is not a race, it is a journey! Event-driven architectures and technologies like Apache Kafka or Apache Flink require a mind shift in

Apache Kafka became the de facto standard for data streaming. Various cloud offerings emerged and improved in the last years. Amazon MSK Serverless is the

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are

Comparing JMS-based message queue (MQ) infrastructures and Apache Kafka-based data streaming is a widespread topic. Unfortunately, the battle is an apple-to-orange comparison that often includes

IT modernization and innovative new technologies change the healthcare industry significantly. This blog series explores how data streaming with Apache Kafka enables real-time data processing




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information