
Apache Kafka became the de facto standard for processing data in motion across enterprises and industries. Cybersecurity is a key success factor across all use cases. Kafka is not just used as a backbone and source of truth for data. It also monitors, correlates, and proactively acts on events from real-time and batch data sources to detect anomalies and respond to incidents. This blog series explores use cases and architectures for Kafka in the cybersecurity space, including situational awareness, threat intelligence, forensics, air-gapped and zero trust environments, and SIEM / SOAR modernization. This post is part six: SIEM / SOAR Modernization.

Blog series: Apache Kafka for Cybersecurity
This blog series explores why security features such as RBAC, encryption, and audit logs are only the foundation of a secure event streaming infrastructure. Learn about use cases, architectures, and reference deployments for Kafka in the cybersecurity space:
- Part 1: Data in Motion as cybersecurity backbone
- Part 2: Situational awareness
- Part 3: Threat intelligence
- Part 4: Forensics
- Part 5: Air-gapped and zero trust environments
- Part 6 (THIS POST): SIEM / SOAR modernization
What are SIEM and SOAR?
SIEM (Security information and event management) and SOAR (security orchestration, automation and response) are terms coined by Gartner (like so often in the industry).
SIEM combines security information management (SIM) and security event management (SEM). They provide analysis of security alerts generated by applications and network hardware. Vendors sell SIEM as software, as appliances, or as managed services; these products are also used for logging security data and generating reports for compliance purposes.
SOAR tools automate security incident management investigations via a workflow automation workbook. The cyber intelligence API enables the playbook to automate research related to the ticket (lookup potential phishing URL, suspicious hash, etc.). The first responder determines the criticality of the event. At this level, it is either a normal or an escalation event. SOAR includes security incident response platforms (SIRPs), Security orchestration and automation (SOA), and threat intelligence platforms (TIPs).
In summary, SIEM and SOAR are key pieces of a modern cybersecurity infrastructure. The capabilities, use cases, and architectures are different for every company.
SIEM and SOAR Vendors
In practice, many products in this area will mix these functions, so there will often be some overlap. Many commercial vendors also promote their own terminology.
The leaders in Gartner’s Magic Quadrant for SIEM 2021 are Exabeam, IBM, Securonix, Splunk, Rapid, LogRhythm. Elastic is a niche player for SIEM but very prevalent in Kafka architectures for other use cases.
The Gartner Market Guide for SOAR 2020 includes Anomali, Cyware, D3 Security, DFLabs, EclecticIQ, FireEye, Fortinet (CyberSponse), Honeycomb.
These are obviously not complete lists of SIEM and SOAR vendors. Even more complex: Gartner says, “SIEM vendors are adopting and acquiring/integrating SOAR solutions in their ecosystems”. Now, if you ask another research analyst or the vendors themselves, you will get even more different opinions 🙂
Hence, as always in the software business, do your own evaluation to solve your business problems. Instead of evaluating vendors, you might first check your pain points and capabilities that solve the problems. Capabilities include data aggregation, correlation, dashboards, alerting, compliance, forensic analysis to implement log analytics, threat detection, and incident management.
If you read some of the analyst reports or vendor websites/whitepapers, it becomes clear that the Kafka ecosystem also has many overlaps regarding capabilities.
The Challenge with SIEM / SOAR Platforms
SIEM and SOAR platforms provide you with various challenges:
- Proprietary forwarders can only send data to a single tool
- Data is locked from being shared
- Difficult to scale with growing data volumes
- High indexing costs of proprietary tools hinder wide adoption
- Filtering out noisy data is complex and slows response
- No one tool can support all security and SIEM / SOAR requirements
The consequence is a complex and expensive spaghetti architecture with different proprietary protocols:
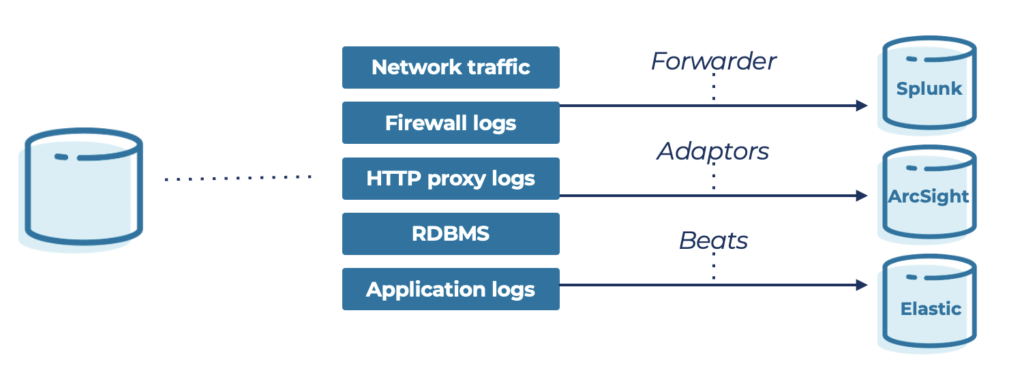
The first post of this blog series explored why Kafka helps a central streaming backbone to avoid such a costly and complex spaghetti architecture. But let’s dig deeper into this discussion.
Kafka for SIEM and SOAR Modernization
A modern cybersecurity architecture has the following requirements:
- Real-time data access to all your security experts
- Historical and contextual data access for forensic reporting
- Rapid detection of vulnerabilities and malicious behavior
- Predictive modeling of security incidents using newer capabilities like ML/AI
Flexible Enterprise Architecture including Kafka, SIEM and SOAR:
Kafka is NOT a SIEM or SOAR. But it enables an open, real-time, and portable data architecture:
- Ingest diverse, voluminous, and high-velocity data at scale
- Scalable platform that grows with your data needs
- Reduce indexing costs and OPEX managing legacy SIEM
- Enable data portability to any SIEM tool or downstream application
The following diagram how the event streaming platform fits into the enterprise architecture together with SIEM/SOAR and other applications:
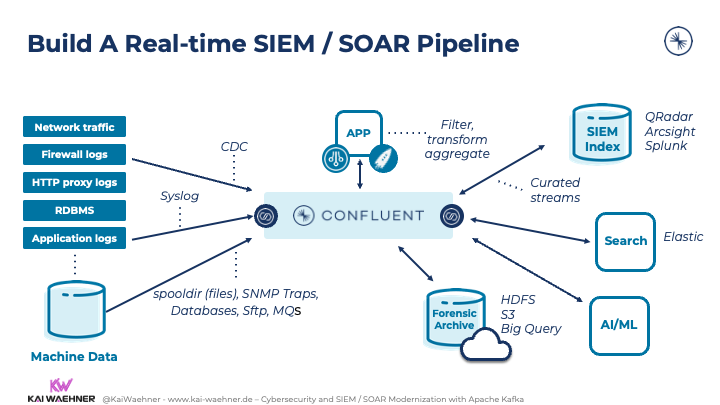
Here are the benefits of this approach for an enterprise architecture:
- Data integration just once, ingest and aggregate events from everywhere: Web / Mobile, SaaS, Applications, Datastores, PoS Systems, loT Sensors, Legacy Apps, and Systems, Machine data
- Data correlation independent from specific products: Join, enrich, transform and analyze data in real-time to convert raw events into clean, usable data, avoid the “shit in shit out” issue from raw data lake architectures
- Standardized, open, and elastic integration layer: Standardize schemas to ensure data compatibility to all downstream apps
- Long-term storage: Store and persist events in a highly available and scalable platform for real-time analytics and forensics
- Integration with one or more SIEM/SOAR tools
- Additional truly decoupled consumers (real-time, batch, request-response): Choose the right tool or technology for the job with a domain-driven design
Reference Architectures for Kafka-powered SIEM and SOAR Infrastructures
Kafka-powered enterprise architecture is open and flexible—no need to try a big bang change. Business units change solutions based on their current need. Often, a combination of different technologies and migration from legacy to modern tools is the consequence. Streaming ETL as ingestion and pre-processing layer for SIEM/SOAR is one use case for Kafka.
However, ingestion and preprocessing for SIEM/SOAR is a tiny fraction of what Kafka can do with the traffic. Other business applications, ML platforms, BI tools, etc., can also consume the data from the event-based central nervous system. At their own speed. With their own technology. That’s what makes Kafka so unique and successful.
This section shows a few reference architectures and migration scenarios for SIEM and SOAR deployments.
SIEM Modernization: Kafka and Elasticsearch
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine. Elasticsearch is developed in Java and dual-licensed under the source-available Server Side Public License and the Elastic license. Other parts fall under the proprietary (source-available) Elastic License.
The open-source Elasticsearch project is NOT a complete SIEM but often a key building block. That’s why it comes up in SIEM discussions regularly.
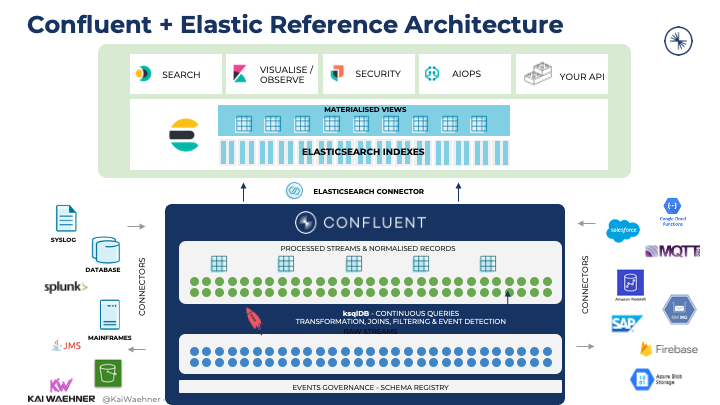
Most scalable Elasticsearch architectures leverage Kafka as the ingestion layer. Other tools like Logstash or Beam are okay for small deployments. But Kafka provides various advantages:
- Scalable: Start small, but scale up without changing the architecture
- Decoupling: Elastic is one sink, but the integration layer provides the events to every consumer
- Out-of-the-box integration: The Kafka Connect connector for Elastic is battle-tested and used in hundreds of companies across the globe.
- Fully managed: In the cloud, the complete integration pipeline including Kafka, Kafka Connect, and Elastic is truly serverless end-to-end.
- Backpressure handling: Elastic is not built for real-time ingestion but is a so-called slow consumer. Kafka handles the backpressure. Elastic indexes the events at its own speed, no matter how fast the data source produces events. Elastic Data Streams is actually improving this to provide more native streaming ingestion.
The following diagram shows the reference architecture for an end-to-end integration from data sources via Kafka into Elastic:
SIEM Modernization: Kafka and Splunk
Splunk provides proprietary software. It is a leading SIEM player in the market. Splunk makes machine data accessible across an organization by identifying data patterns, providing metrics, diagnosing problems, and providing intelligence for business operations. The biggest complaint I hear about Splunk regularly is the costly licensing model. Also, the core of Splunk (like almost every other SIEM) is based on batch processing.
The combination of Kafka and Splunk reduces costs significantly. Here is the Confluent reference architecture:
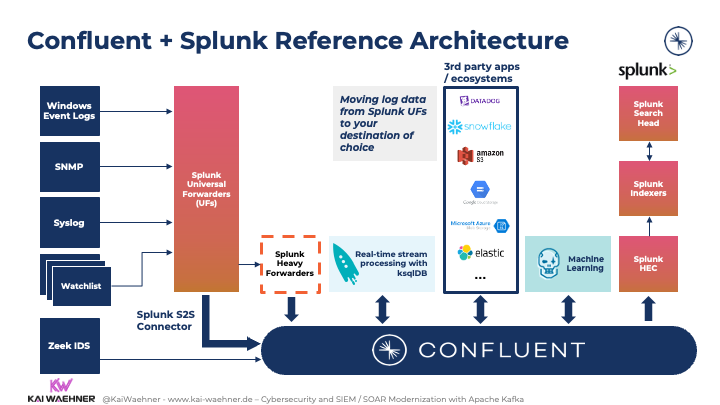
A prominent example of combining Confluent and Splunk is Intel’s Cyber Intelligence Platform (CIP), which I covered in part 3 of this blog series.
The above architecture shows an open, flexible architecture. Splunk provides several integration points. But at its core, Splunk uses the proprietary S2S (“Splunk-to-Splunk”) protocol. All universal forwarders (UF) broadcast directly to indexers or heavy forwarders (HF). The Confluent Splunk S2S Source Connector provides a way to integrate Splunk with Apache Kafka. The connector receives data from Splunk UFs.
This approach allows customers to cost-effectively & reliably read data from Splunk Universal Forwarders to Kafka. It enables users to forward data from universal forwarders into a Kafka topic to unlock the analytical capabilities of the data.
The direct S2S integration is beneficial if a company does not have Kafka out front and the data goes straight to Splunk indexers. To leverage Kafka, the connector “taps” into the Universal Forwarder infrastructure. Often, companies have 10,000s of UFs. If you are in the lucky situation of not having hundreds or thousands of Splunk UFs in place, then the regular Splunk sink connector for Kafka Connect might be sufficient for you.
The data is processed, filtered, aggregated in real-time at scale with Kafka-native tools such as Kafka Streams or ksqlDB. The processed data is ingested into Splunk; and potentially many other real-time or batch consumers that are completely decoupled from Splunk.
Using the right SIEM and SOAR for the Job
Most customers I talk to don’t use just one tool for solving their cybersecurity challenges. For that reason, Kafka is the perfect backbone for true decoupling and ingestion layer for different SIEM and SOAR tools:
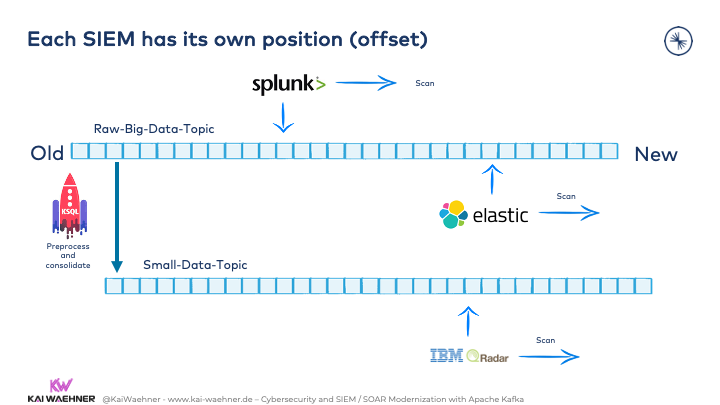
Kafka’s commit log stores the incoming data. Each consumer consumes the data as it can. In this example, different SIEM tools consume the same events. Elasticsearch and Splunk consume the same raw data in different near real-time or batch processes. Both are completely independent in how they consume the events.
IBM QRadar cannot process high volumes of data. Hence, ksqlDB continuously preprocesses the raw data and puts it into a new Kafka topic. QRadar consumes the aggregated data.
Obviously, SOAR can consume data similarly. As discussed earlier in this article, the SOAR functionality could also be part of one of the SIEMs. However, then it would (have to) consume the data in real-time to provide true situational awareness.
Legacy SIEM Replacement and Hybrid Cloud Migration
In the field, I see several reasons to migrate workloads away from a deployed SIEM:
- Very high costs, usually with a throughput-based license model
- Scalability issues for the growing volumes of data in the enterprise
- Processing speed (batch) is not sufficient for real-time situational awareness and threat intelligence
- Migration from on-premise to (multi) cloud across regions and data centers
Groupon published an exciting success story: “We Replaced Splunk at 100TB Scale in 120 Days“:

The new platform leverages Kafka for high volume processing in real-time, migration, and backpressure handling. Elasticsearch provides reports, analytics, and dashboards.
The article also covers the repeating message that Logstash is not ideal for these kinds of workloads. Hence, the famous ELK stack with Elasticsearch, Logstash, and Kibana in most real-world deployments is actually an EKK stack with Elasticsearch, Kafka, and Kibana.
This story should make you aware that Logstash, FluentD, Sumo Logic, Cribl, and other log analytics platforms are built for exactly this use case. Kafka-native processing enables the same but also many other use cases.
Another key advantage of Kafka is the ability to operate as a resilient, hybrid migration pathway from on-premise to one or multiple clouds. Confluent can be deployed everywhere to coordinate log traffic across multiple data centers and cloud providers. I explored hybrid Kafka architectures in another blog post in detail.
Kafka-native SOAR: Cortex Data Lake from Palo Alto Networks (PANW)
I covered various SIEMs in this post. SOAR is a more modern concept than SIEM. Hence, the awareness and real-world deployments are still limited. I am glad that I found at least one public example I can show you in this post.
Cortex Data Lake is a Kafka-native SOAR that collects, transforms, and integrates enterprise security data at scale in real-time. Billions of messages pass through their Kafka clusters. Confluent Schema Registry enforces data governance. Palo Alto Networks (PANW) has multiple Kafka clusters in production with a size from 10 to just under 100 brokers each. Check out Palo Alto Networks’ engineering blog for more details.
Here is the architecture of Cortex Data Lake:
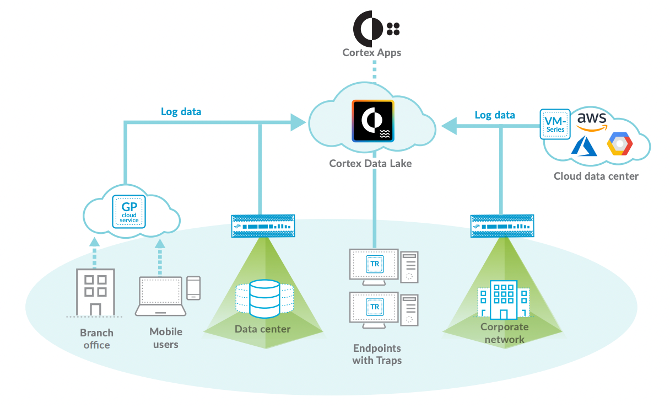
PANW’s design principles overlap significantly with the unique characteristics of Apache Kafka:
- Cloud agnostic infrastructure
- Massively scalable
- Aggressive ETA on integrations
- Schema versioning support
- Microservices architecture
- Operational efficiency
If you look at these design principles, it is obvious why the backbone of PANW’s product is Kafka.
Most Enterprises have more than one SIEM/SOAR
SIEM and SOAR are critical for every enterprise’s cybersecurity strategy. One SIEM/SOAR is typically not good enough. It is either not cost-efficient or includes scalability/performance issues.
Kafka-native SIEM/SOAR modernization is prevalent across industries. The central event-based backbone enables the integration with different SIEM/SOAR products. Other consumers (like ML platforms, BI tools, business applications) can also access the data. Innovative Kafka integrations like Confluent’s S2S connector enable the modernization of monolithic Splunk deployments and significantly reduce costs. Many next-generation SOARs such as PANW’s Cortex Data Lake are even based on top of Kafka.
Do you use any SIEM / SOAR? How and why do you use or plan to use the Kafka ecosystem together with these tools? How does your (future) architecture look like? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
