Industrial IoT and Industry 4.0 enable digitalization and innovation. SCADA control systems are a vital component of IT/OT modernization. The SCADA evolution started with monolithic applications and moved to networked and web-based platforms. This blog post explores building the 5th generation: A cloud-native SCADA infrastructure with Apache Kafka. A real-world case study explores the journey of a German system operator for electricity to show how such a journey to open and scalable real-time workloads and edge-to-cloud integration progressed.

What is a SCADA system?
Supervisory control and data acquisition (SCADA) is a control system architecture comprising computers, networked data communications, and graphical user interfaces for high-level supervision of machines and processes. It also covers sensors and other devices, such as programmable logic controllers, which interface with process plants or machinery.
While many people refer to specific commercial products, SCADA is a concept or architecture. It can include various components, functions, and products (from different vendors) on different levels:
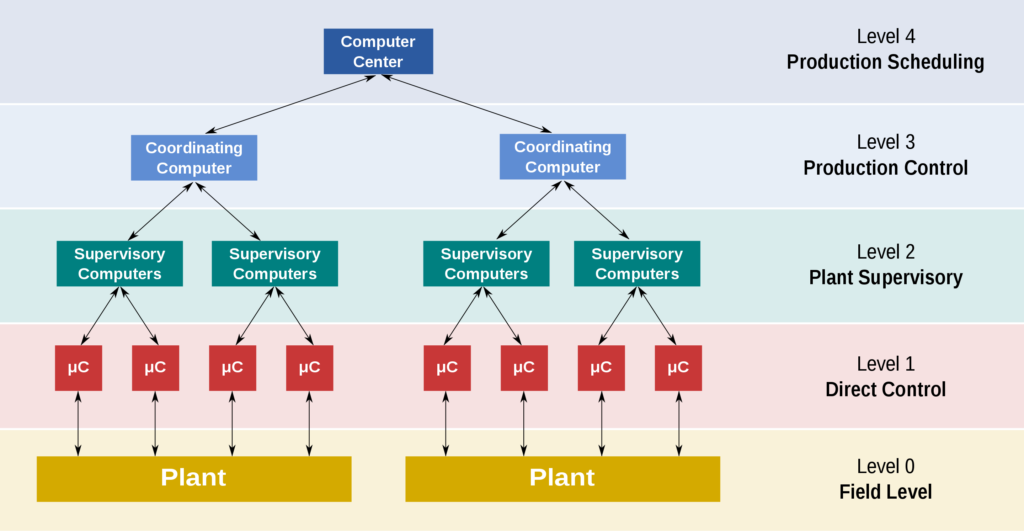
Wikipedia has a detailed article explaining the terms, history, components, and functions of SCADA. The evolution describes four generations of SCADA systems:
- First generation: Monolithic
- Second generation: Distributed
- Third generation: Networked
- Fourth generation: Web-based
The evolution did not stop here. The following explores the 5. generation: Cloud-native and open SCADA systems.
How does Apache Kafka help in Industrial IoT?
Industrial IoT (IIoT) and Industry 4.0 create a few new challenges across industries:
- The need for a much bigger scale
- The demand for real-time information
- Hybrid architectures with mission-critical workloads at the edge and analytics in elastic public cloud infrastructure.
- A flexible Open API culture and data sharing across OT/IT environments, and between partners (e.g., supplier, OEM, and mobility service).
Apache Kafka is unique in its characteristics for IoT infrastructures, being very scalable (for transactional and analytical requirements and SLAs), reliable, and open. Hence, many new Industrial IoT projects adopt Apache Kafka for various use cases, including data hub between OT and IT, global integration of smart factories for analytics, predictive maintenance, customer 360, and many other scenarios.
Cloud-native data historian powered by Apache Kafka (operating at the edge or in the cloud)
Data Historian is a well-known concept in Industrial IoT. It helps to ensure and improve the Overall Equipment Effectiveness (OEE). The term often overlaps with SCADA. Some people even use it as a synonym.
Apache Kafka can be used as a component of a Data Historian to improve the OEE and reduce/eliminate the most common causes of equipment-based productivity loss in manufacturing (aka Six Big Losses):
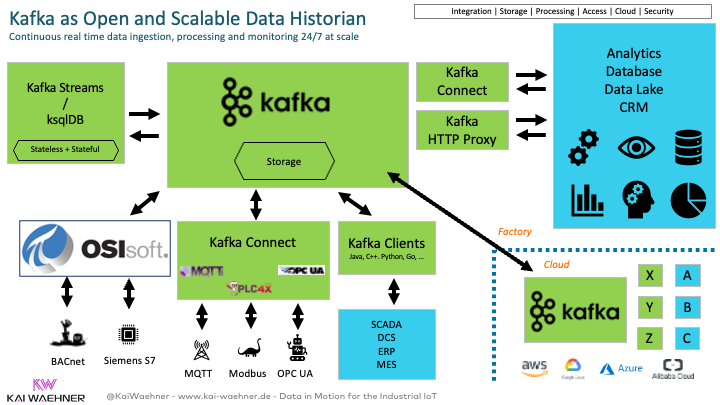
Continuous real-time data ingestion, processing, and monitoring 24/7 at scale is a crucial requirement for thriving Industry 4.0 initiatives. Data Streaming with Apache Kafka and its ecosystem brings enormous value to implementing these modern IoT architectures.
Let’s explore a concrete example of a cloud-native SCADA system.
50hertz: A case study for a cloud-native SCADA system built with Apache Kafka
50hertz is a transmission system operator for electricity in Germany. The company secures electricity supply to 18 million people in northern and eastern Germany.
The infrastructure must operate 24 hours, seven days a week. Various shift teams and a mission-critical SCADA infrastructure supervise and control the OT systems.
50hertz presented their OT/IT and SCADA modernization leveraging data streaming with Apache Kafka at the Confluent Data in Motion tour 2021. The on-demand video recording is available (the speech is in German, unfortunately).
The Journey of 50hertz in a big picture
Look at this fantastic picture of 50hertz’s digital transformation journey from monolithic and proprietary legacy technology to a modern cloud-native integration platform powered by Kafka to modernize their IoT ecosystem, such as SCADA systems:
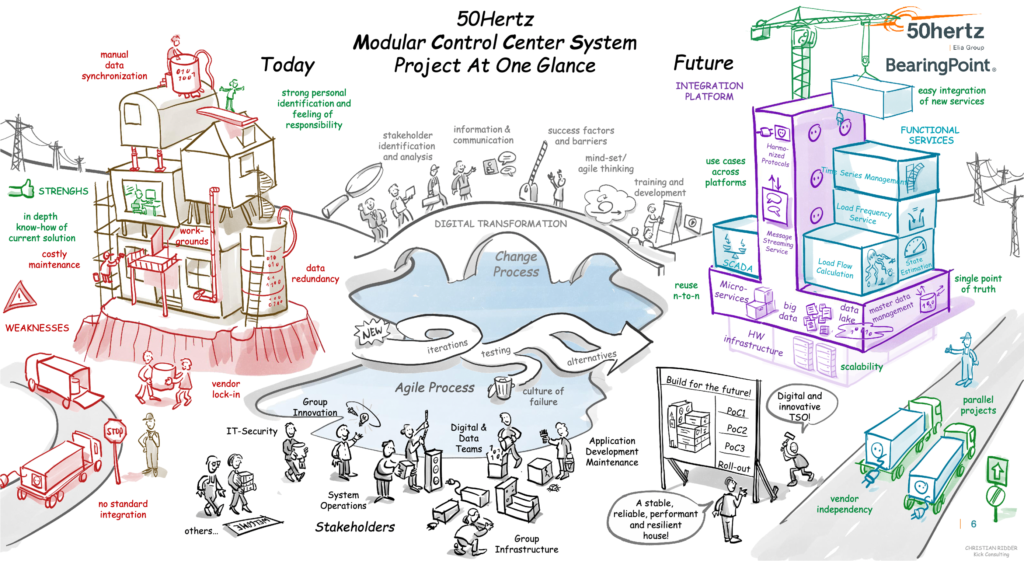
Notice the details in the above picture:
- The legacy infrastructure on the left side glues and patches together different components. It almost breaks together. No changes are possible to existing components.
- The new infrastructure on the ride side is based on flexible, standardized containers. It is easy to scale, add, or remove applications. The communication happens via standard sizes and schemas.
- The bridge in the middle shows the journey. This is a brownfield approach where the old and new world has to communicate with each other for many years. Over time, the company can shut down more and more of the legacy infrastructure.
A great example of innovation in the energy sector! Let’s explore the details of building a cloud-native SCADA system with Apache Kafka:
Challenges of the monolithic legacy IoT infrastructure
The old IT/OT infrastructure and SCADA system are monolithic, proprietary, not scalable, and miss open APIs based on standard interfaces:
A very common infrastructure setup. Most existing OT/IT infrastructures have exactly the same challenges. This is how factories and production lines were built in the past decades.
The consequence is inflexibility regarding software updates, hardware changes, security fixes, and no option for scalability or innovation. Applications run in disconnected mode and are air-gapped from the internet because the old Windows servers are not even supported and no longer get security patches.
Digital transformation in the industrial space requires modernization. Legacy infrastructure still needs to be integrated into most scenarios. Not every company starts from scratch like Tesla, building brand new factories that are built with automation and digitalization from scratch.
Cloud-native SCADA with Kafka to enable innovation (and legacy integration)
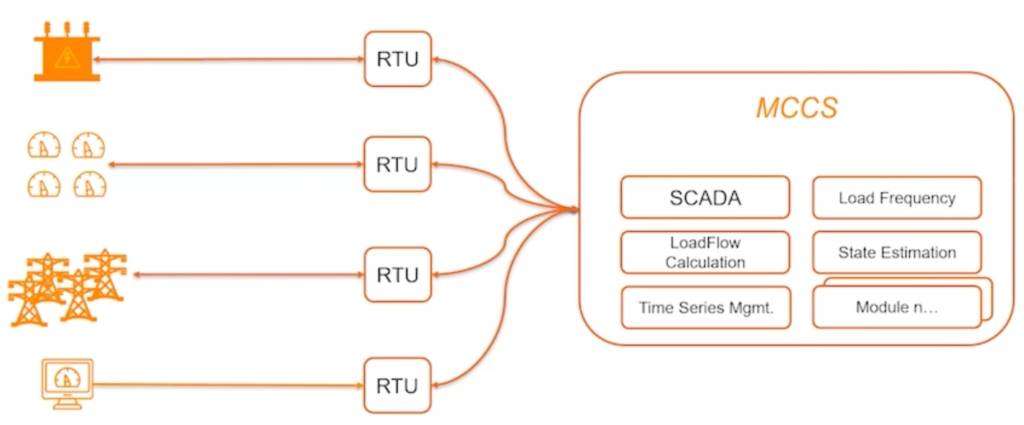
50hertz next-generation Modular Control Center System (MCCS) leverages a central, scalable, event-based integration platform based on Confluent:
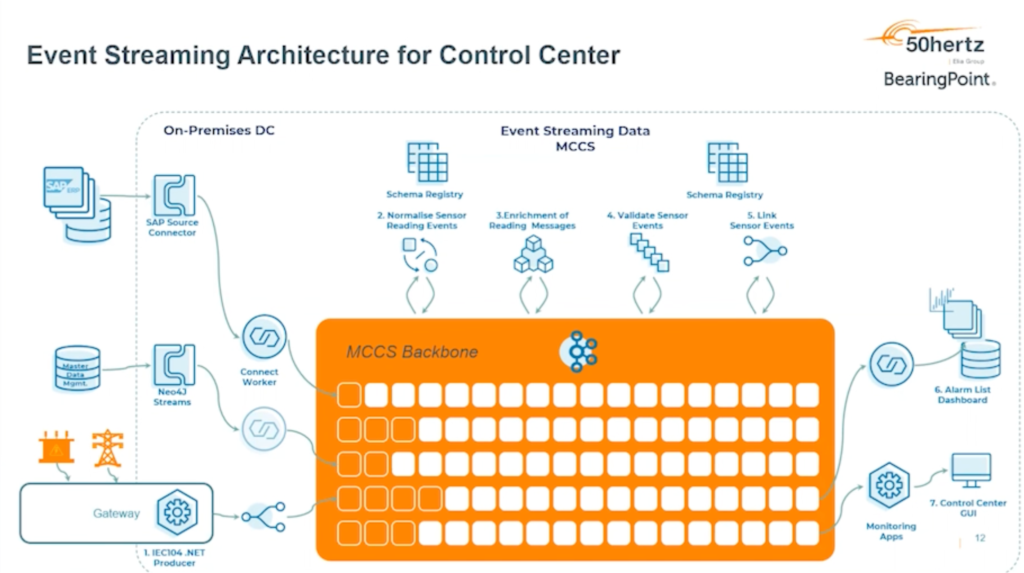
The first four containers include the Supervisory & Control (SCADA), Load Frequency Control (LFC), and Time Series Management & Forecasting applications. Each container can have multiple services/functions that follow the event-based microservices pattern.
50hertz provides central governance for security, protocols, and data schemas (CIM compliant) between platform containers/ modules. The cloud-native 24/7 SCADA system is developed in the cloud and deployed in safety-critical edge environments.
More on data streaming and Industrial IoT
If you want to learn more about real-world case studies, use cases, and technical architectures for data streaming with Apache Kafka in IIoT scenarios, check out these articles:
- Use cases and architectures for Apache Kafka for Industrial IoT and Manufacturing 4.0
- Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real Time Data Lake
- OPC UA, MQTT, and Apache Kafka – The Trinity of Data Streaming in IoT
- Use cases and architecture for Kafka and MQTT
- Apache Kafka Landscape for Industrial IoT in the Automotive Industry
- Data streaming in air-gapped and zero-trust environments
- Real-Time Logistics, Shipping, and Transportation with Apache Kafka
- A Real-Time Supply Chain Control Tower powered by Kafka
- A postmodern ERP system built with Kafka
If this is insufficient, please let me know what else you need to know… 🙂
Cloud-native architectures and Open API are the future of Industrial IoT
50hertz is a tremendous real-world case study about the modernization of the OT/IT world. A modern SCADA architecture requires real-time data processing at any scale, true decoupling between data producers and consumers (no matter what API these apps use), and open interfaces to integrate with any other application like MES, ERP, cloud services, and so on.
From the IT side, this is nothing new. The last decade brought up scalable open source technologies like Kafka, Spark, Flink, Iceberg, and many more, plus related fully managed, elastic cloud services like Confluent Cloud, Databricks, Snowflake, and so on.
However, the OT side has to change. Instead of using monolithic legacy systems, unsupported and unstable Windows servers, and proprietary protocols, next-generation SCADA systems need to use the same cloud-native IT systems, adopt modern OT hardware/software combinations, and integrate the old and new world to enable digitalization and innovation in industry verticals like manufacturing, automotive, military, energy, and so on.
What role plays data streaming in your Industrial IoT environments and OT/IT modernization? Do you run everything around Kafka in the cloud or operate hybrid edge scenarios? What tasks does Kafka take over – is it “just” the data hub, or are IoT use cases built with it, too? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.