
In the IoT world, MQTT (Message Queue Telemetry Transport protocol) and OPC UA (OPC Unified Architecture) have established themselves as open and platform-independent standards for data exchange in Internet of Things (IIoT) and Industry 4.0 use cases. Data Streaming with Apache Kafka is the data hub for integrating and processing massive volumes of data at any scale in real-time. This blog post explores the relationship between Kafka and the IoT protocols, when to use which technology, and why sometimes HTTP/REST is the better choice. The end explores real-world case studies from Audi and BMW.

Industry 4.0: Data streaming platforms increase overall plant effectiveness and connect equipment
Machine data must be transformed and made available across the enterprise as soon as it is generated to extract the most value from the data. As a result, operations can avoid critical failures and increase the effectiveness of their overall plant.
Automotive manufacturers such as BMW and Tesla have already recognized the potential of data streaming platforms to get their data moving with the power of the Apache Kafka ecosystem. Let’s explore the benefits of data streaming and how this technology enriches data-driven manufacturing companies.
The goals of increasing digitization and automation of the manufacturing sector are many:
- To make production processes more efficient
- Faster and cheaper overall
- To minimize error rates.
Manufacturers are also striving to increase overall equipment effectiveness (OEE) in their production facilities – from product design and manufacturing to maintenance operations. This confronts them with equally diverse challenges. Industry 4.0 respectively Industrial IoT (IIoT) means that the amount of data generated daily is increasing and needs to be transported, processed, analyzed, and made available through systems in near real-time.
Complicating matters further is that legacy IT environments continue to live in today’s manufacturing facilities. This limits manufacturers’ ability to efficiently integrate data across operations. Therefore, most manufacturers require a hybrid data replication and synchronization strategy.
An adaptive manufacturing strategy starts with real-time data
Automation.com published an excellent article explaining the need for real-time processes and monitoring to provide a flexible production line. TL;DR: Processes should be real-time when possible, but real-time is not always possible, even within an application. Think about just-in-time production fighting with the supply chain issues because of the Covid pandemic and the Suez Canal block in 2021.
The theory of just-in-time production does not work with supply chain issues! You need to provide flexibility and be able to switch between different approaches:
- Just-in-time (JIT) vs. make to forecast
- Fixed vs. variable price contracts
- Build vs. buy plant capacity
- Staffed vs. lights-out third shift
- Linking vs. not linking prices for materials and finished goods
Kappa architecture for a real-time IoT data hub
Real-time production and process monitoring data are essential for success! This evolution is only possible with real-time Kappa architecture. Lambda architecture with batch workloads either completely fails or makes things much more complex and costs from an IT infrastructure and OEE perspective.
For clarification, when I speak about real-time, I talk about millisecond latency. This is not hard real-time and deterministic like in safety-critical and embedded environments. The post “Apache Kafka is NOT Hard Real-Time BUT Used Everywhere in Automotive and Industrial IoT” elaborates on this topic.
In IoT, the MQTT and OPC UA have established standards for data exchange as platform-independent open standards. See what this combination of IoT protocols and Kafka looks like in a smart factory.
When to use Kafka vs. MQTT and OPC UA?
Kafka is a fantastic data streaming platform for messaging, storage, data integration, and data processing in real-time at scale. However, it is not a silver bullet for every problem!
Kafka is NOT…
- A proxy for millions of clients (like mobile apps) – but Kafka-native proxies (like REST or MQTT) exist for some use cases.
- An API Management platform – but these tools are usually complementary and used for the creation, life cycle management, or the monetization of Kafka APIs.
- A database for complex queries and batch analytics workloads – but good enough for transactional queries and relatively simple aggregations (especially with ksqlDB).
- An IoT platform with features such as device management – but direct Kafka-native integration with (some) IoT protocols such as MQTT or OPC-UA is possible and the appropriate approach for (some) use cases.
- A technology for hard real-time applications such as safety-critical or deterministic systems – but that’s true for any other IT framework, too. Embedded systems are different software!
For these reasons, Kafka is complementary, not competitive, to MQTT and OPC UA. Choose the right tool for the job and combine them! I wrote a detailed blog post exploring when NOT to use Apache Kafka. The above was just the summary.
You should also think about this question from the other side to understand when a message broker is not the right choice. For instance, United Manufacturing Hub is an open-source manufacturing data infrastructure that recently migrated from MQTT as messaging infrastructure to Kafka as the central nervous system because of its storage capabilities, higher throughput, and guaranteed ordering. However, to be clear, this update is not replacing but complementing MQTT with Kafka.
Meeting the challenges of Industry 4.0 through data streaming and data mesh
Machine-to-machine communications and the (Industrial) Internet of Things enable automation, data-driven monitoring, and the use of intelligent machines that can, for example, identify defects and vulnerabilities on their own.
For all these scenarios, large volumes of data must be processed in near real-time and made available across plants, companies, and, under certain circumstances, worldwide via a stream data exchange:
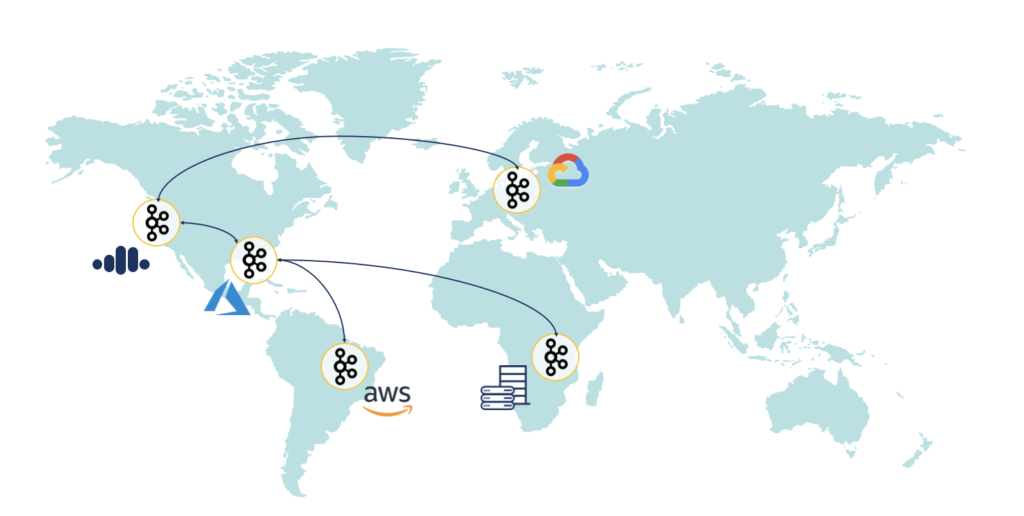
This novel design approach is often implemented with Apache Kafka as decentralized data streaming data mesh.
The essential requirement here is integrating various systems, such as edge and IoT devices and business software, and execution independent of the underlying infrastructure (edge, on-premises as well as public, multi-, and hybrid cloud).
Therefore, an open, elastic, and flexible architecture is essential to integrate with the legacy environment while taking advantage of modern cloud-native applications.
Event-driven, open, and elastic data streaming platforms such as Apache Kafka serve precisely these requirements. They collect relevant sensor and telemetry data alongside data from information technology systems and process it while it is in motion. That concept is called “data in motion“. The new fundamental change differs significantly from processing “data at rest“, meaning you store events in a database and wait until someone else looks at them later. The latter is a “too late architecture” in many IoT use cases.
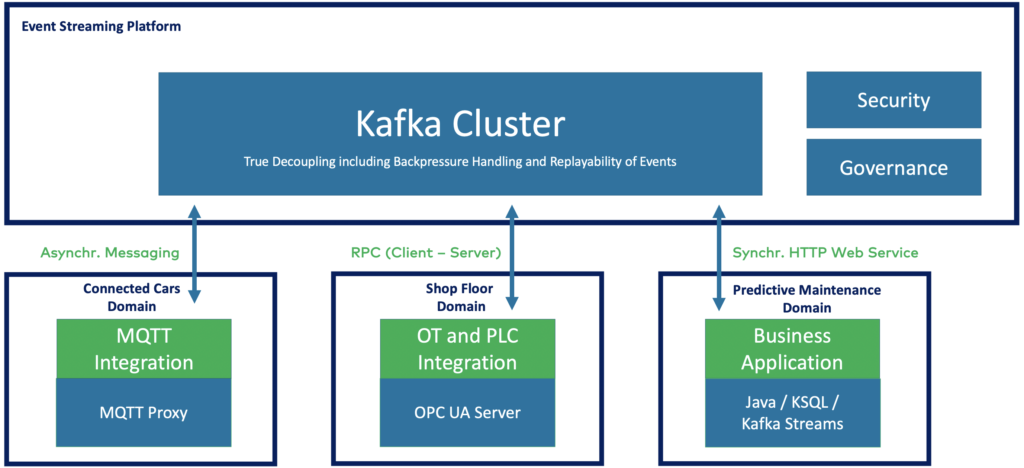
Separation of concerns in the OT/IT world with domain-driven design and true decoupling
Data integration with legacy and modern systems takes place in near real-time – target systems can use relevant data immediately. It doesn’t matter what infrastructure the plant’s IT landscape is built on. Besides the continuous flow of data, the decoupling of systems also allows messages to be stored until the target systems need them.
That feature of true decoupling with backpressure handling and replayability of data is a unique differentiator compared to other messaging systems like RabbitMQ in the IT space or MQTT in the IoT space. Kafka is also highly available and fail-safe, which is critical in the production environment. “Domain-driven design (DDD) with Apache Kafka” dives deeper into this benefit:
How to choose between OPC UA and MQTT with Kafka?
Three de facto standards for open and standardized IoT architectures. Two IoT-specific protocols and REST / HTTP as simple (and often good enough) options. Modern proprietary protocols compete in the space, too:
- OPC UA (Open Platform Communications Unified Architecture)
- MQTT (Message Queuing Telemetry Transport)
- REST / HTTP
- Proprietary protocols and IoT platforms
These alternatives are great vs. the legacy proprietary monolith world of the last decades in the OT/IT and IoT space.
MQTT vs. OPC UA (vs. HTTP vs. Proprietary)
First of all, this discussion is only relevant if you have the choice. If you buy and install a new machine or PLC on your shop floor and that one only offers a specific interface, then you have to use it. However, new software like IoT gateways provides different options to choose from.
How to compare these communication protocols?
Well, frankly, it is challenging as most literature is opinionated and often includes FUD about the “competing protocols”. Every alternative has its sweet spots. Hence, it is more of an apples and oranges comparison.
More or less randomly, I googled “OPC UA vs MQTT” and found the following interesting comparison from Skynet’s proprietary DataHub Transfer Protocol (DHTP). The vendor pitches its commercial product against the open standards (and added AMQP as an additional alternative):

Each comparison on the web differs. The above comparison is valid (and some people will disagree with some points). And sometimes, proprietary solutions provide the better choice from a TCO and ROI perspective, too.
Hint: Look at different comparisons. Understand if the publication is related to a specific vendor and standard. Evaluate several solutions and vendors to understand the differences and added value.
Decision tree for evaluating IoT protocols
My recommendation for comparing the different IoT protocols is to use open standards whenever possible. Choose the right tool for the job and combine them in a best-of-breed approach as needed.
Let’s take at a simple decision tree to decide between OCP UA, MQTT, HTTP, and other proprietary IIoT protocols (note: This is just a very simplified point of view, and you can build your opinion with different decisions, of course):
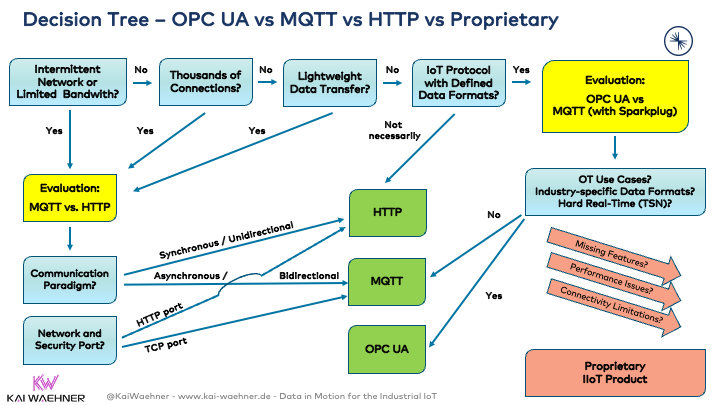
A few notes on the reasoning for how I built this decision tree:
- HTTP / REST is perfect for simple use cases (keep it as simple as possible). HTTP is supported almost everywhere, well understood, and simple to use. No additional tooling, APIs, or middleware is needed. Communication is synchronous request-response. Conversations with security teams are much easier if you just need to open port 80 or 443 for HTTP(S) instead of TCP ports, like most other protocols. HTTP is unidirectional communication (e.g., a connected car needs an HTTP server to get data pushed from the cloud – pub/sub is the right choice instead of HTTP here).
- MQTT is perfect for intermittent networks, respectively limited bandwidth and/or connecting tens or hundreds of thousands of devices (e.g., connected car infrastructure). Communication is asynchronous publish/subscribe using an MQTT broker as the middleman. MQTT uses no standard data format. But developers can use Sparkplug as an add-on built for this purpose. MQTT is incredibly lightweight. Features like Quality of Service (QoS), last will, and testament solve many requirements for IoT use cases out-of-the-box. MQTT is excellent for IT use cases and can easily be used for bidirectional communication (e.g., connected cars <–> cloud communication). LoRaWAN and other low-power wide-area networks are great for MQTT, too.
- OPC UA is perfect for industrial automation (e.g., machines at the production line). Communication is usually client/server today, but publish/subscribe is also supported. It uses standard data formats and provides a rich (= powerful but also complex) set of features, components, and industry-specific data formats. OPC UA is excellent for OT/IT integration scenarios. OPC UA TSN (time-sensitive networking), one optional component, is an Ethernet communication standard that provides open, deterministic, hard real-time communication.
- Proprietary protocols suit specific problems that standard-based implementations cannot solve similarly. These protocols have various trade-offs. Often powerful and performant, but also expensive and proprietary.
Choosing between OPC UA, MQTT, and other protocols isn’t an either/or decision. Each protocol plays its role and excels at certain use cases. An optimal modern industrial network uses OPC UA and MQTT for modern applications. Both together combine the strengths of each and mitigate their downsides. Legacy applications and proprietary SCADA systems or other data historians are usually integrated with other existing proprietary middleware.
Many IIoT platforms, such as Siemens, OSIsoft, or Inductive Automation, support various modern and legacy protocols. Some smaller vendors focus on a specific sweet spot, like HiveMQ for MQTT or OPC Router for OPA-UA.
Integration between MQTT / OPC UA and Kafka
A few integration options between equipment, machines, and devices that support MQTT or OPC UA and Kafka are:
- Kafka Connect connectors: Native Kafka integration on protocol level. Check Confluent Hub for a few alternatives. Some enterprises built their custom Kafka Connect connectors.
- Custom integration: Integration via a low level MQTT / OPC UA API (e.g. using Kafka’s HTTP / REST Proxy) or Kafka client (e.g. .NET / C++ for Windows environments).
- Modern and open 3rd party IoT middleware: Generic open source integration middleware (e.g., Apache Camel with its IoT connectors), IoT-specific frameworks (like Apache PLC4X or Eclipse Ditto), or proprietary 3rd party IoT middleware with open and standards-based APIs
- Commercial IoT platforms: Best fit for existing historical deployments and glue code with legacy protocols such as Modbus, Siemens S7, et al. Traditional data historians, proprietary protocols, monolith architectures, limited scalability, batch ETL platforms, work well for these workloads to connect the past with the future of the OT/IT world and to create a bridge between on-premise and cloud. Almost all IoT platforms added connectors for MQTT, OCP UA, and Kafka in the meantime.
OEE scenarios that benefit from data streaming
Data streaming platforms apply in various use cases to increase overall plant effectiveness as the central nervous system. These include connectivity via industry standards such as OPC UA or MQTT, visualization of multiple devices and assets in digital twins, and modern maintenance in the form of condition monitoring and predictive maintenance.
Connectivity to machines and equipment with OPC UA or MQTT
OPC UA and MQTT are not designed for data processing and integration. Instead, the strength is that bidirectional “last mile communication” to devices, machines, PLCs, IoT gateway, or vehicles is established in real-time.
As discussed above, both standards have different “sweet spots” and can also be combined: OPC UA is supported by almost all modern machines, PLCs, and IoT gateways for the smart factory. MQTT is used primarily in poor networks and/or also for thousands and hundreds of thousands of devices.
These data streams are then streamed into the data streaming platforms via connectors. The streaming platform can either be deployed in parallel with an IoT platform ‘at the edge’ or combined in hybrid or cloud scenarios.
The data streaming platform is a flexible data hub for data integration and processing between OT and IT applications. Besides OPC UA and MQTT on the OT side, various IT applications such as MES, ERP, CRM, data warehouse, or data lake are connected in real-time, regardless of whether they are operated ‘at the edge’, on-premise, or in the cloud.
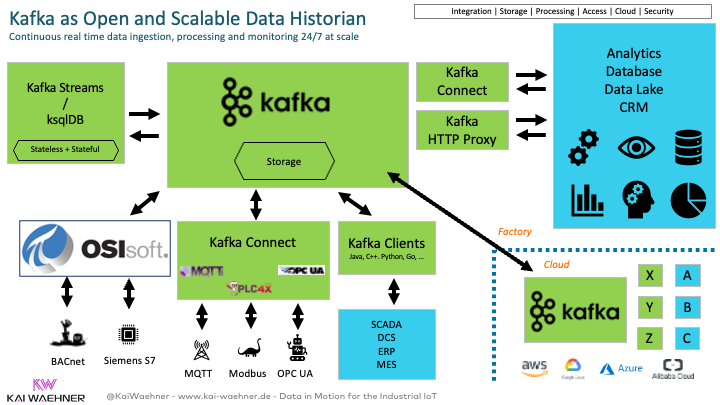
More details: Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real-Time Data Lake.
Digital twins for development and predictive simulation
By continuously streaming data and processing and integrating sensor data, data streaming platforms enable the creation of an open, scalable, and highly available infrastructure for the deployment of Digital Twins.
Digital Twins combine IoT, artificial intelligence, machine learning, and other technologies to create a virtual simulation of, for example, physical components, devices, and processes. They can also consider historical data and update themselves as soon as the data generated by the physical counterpart changes.
Kafka is the leading system in the following digital twin example:
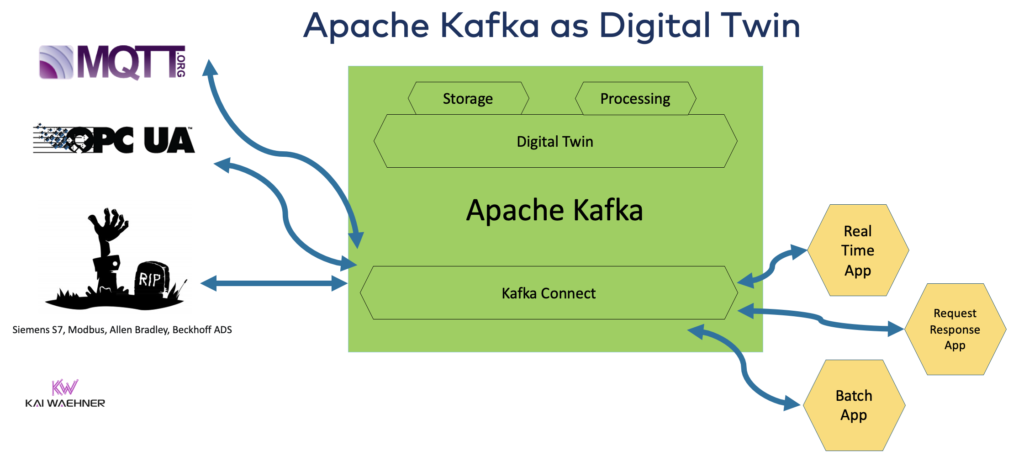
Kafka is combined with other technologies to build a digital twin most times. For instance, Eclipse Ditto is a project combining Kafka with IoT protocols. And some teams made a custom digital twin with Kafka and a database like MongoDB.
IoT Architectures for Digital Twin with Apache Kafka provide more details about different digital twin architectures.
Industry 4.0 benefits from digital twins, as they allow detailed insight into the lifecycle of the elements they simulate or monitor. For example, product and process optimization can be carried out, individual parts or entire systems can be tested for their functionality and performance, or forecasts can be made about energy consumption and wear and tear.
Condition monitoring and predictive maintenance
For modern maintenance, machine operators mainly ask themselves questions: Are all devices functioning as intended? How long will these devices usually function before maintenance work is necessary? What are the causes of anomalies and errors?
On the one hand, Digital Twins can also be used here for monitoring and diagnostics. They correlate current sensor data with historical data, which makes it possible to identify the causes of faults and expect maintenance measures.
On the other hand, production facilities can also benefit from data streaming in this area. A prerequisite for Modern Maintenance is a reliable and scalable infrastructure that enables the processing, analysis, and integration of data streams. This allows the detection of critical changes in plants, such as severe temperature fluctuations or vibrations, in near real-time, after which operators can initiate measures to maintain plant effectiveness.
Above all, more efficient predictive maintenance scheduling saves manufacturing companies valuable resources by ensuring equipment and facilities are serviced only when necessary. In addition, operators avoid costly downtime periods when machines are not productive for a while.
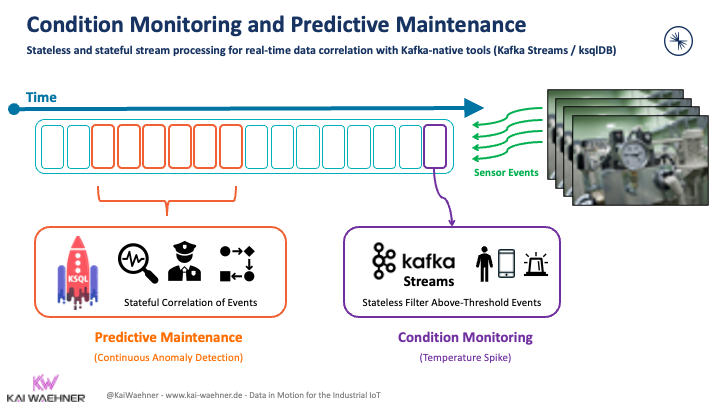
More details: Condition Monitoring and Predictive Maintenance with Apache Kafka.
Connected cars and streaming machine learning
A connected car is a car that can communicate bidirectionally with other systems outside of the vehicle. This allows the car to share internet access and data with other devices and applications inside and outside the car. The possibilities are endless! MQTT in conjunction with Kafka is more or less a de facto standard architecture for connected car use cases and infrastructures.
The following shows how to integrate with tens or hundreds of thousands of IoT devices and process the data in real-time. The demo use case is predictive maintenance (i.e., anomaly detection) in a connected car infrastructure to predict motor engine failures:
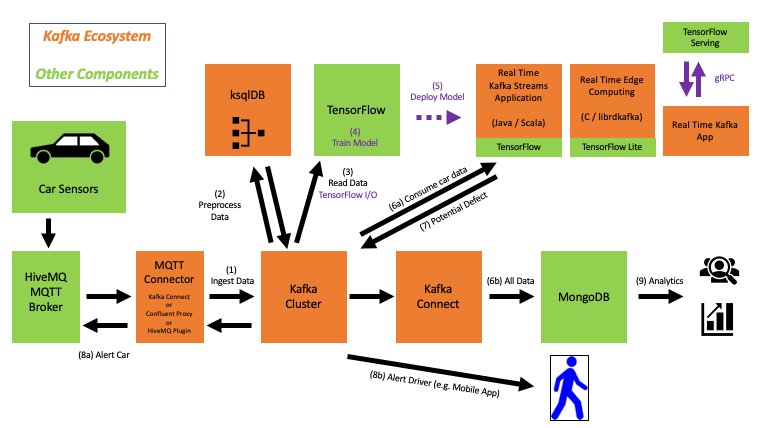
The blog post “IoT Live Demo – 100.000 Connected Cars with Kubernetes, Kafka, MQTT, TensorFlow” explores the architecture and implementation in more detail. The source code is available on Github.
BMW case study: Manufacturing 4.0 with smart factory and cloud
I spoke with Felix Böhm, responsible for BMW Plant Digitalization and Cloud Transformation, at our Data in Motion tour in Germany in 2021. We talked about their journey towards data in motion in manufacturing and the use cases and architectures. He also talked to Confluent CEO Jay Kreps at the Kafka Summit EU 2021.
Kafka and OPC UA as real-time data hub between equipment at the edge and applications in the cloud
Let’s explore this BMW success story from a technical perspective.
Decoupled IoT Data and Manufacturing
BMW connects workloads from their global smart factories and replicates them in real-time in the public cloud. The team uses an OPC UA connector to directly communicate with Confluent Cloud in Azure.
Kafka provides decoupling, transparency, and innovation. Confluent adds stability via products and expertise. The latter is critical for success in manufacturing. Each minute of downtime costs a fortune. Read my related article “Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real-Time Data Lake” to understand how Kafka improves the Overall Equipment Effectiveness (OEE) in manufacturing.
Logistics and supply chain in global plants
The discussed use case covered optimized supply chain management in real-time.
The solution provides information about the right stock in place, both physically and in ERP systems like SAP. “Just in time, just in sequence” is crucial for many critical applications.
Things BMW couldn’t do before
- Get IoT data without interfering with others, and get it to the right place
- Collect once, process, and consume several times (by different consumers at different times with varying paradigms of communication like real-time, batch, request-response)
- Enable scalable real-time processing and improve time-to-market with new applications
The true decoupling between different interfaces is a unique advantage of Kafka vs. other messaging platforms such as IBM MQ, Rabbit MQ, or MQTT brokers. I also explored this in my article about Domain-driven Design (DDD) with Kafka.
Check out “Apache Kafka Landscape for Automotive and Manufacturing” for more Kafka architectures and use cases in this industry.
Audi case study – Connected cars for swarm intelligence
Audi has built a connected car infrastructure with Apache Kafka. Their Kafka Summit keynote explored the use cases and architecture:
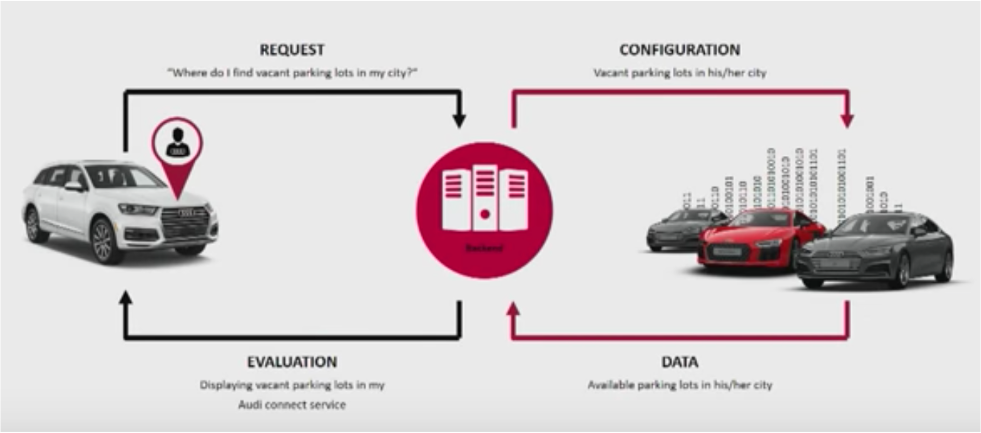
Use cases include real-time data analysis, swarm intelligence, collaboration with partners, and predictive AI.
Depending on how you define the term and buzzword “Digital Twin“, this is a perfect example: All sensor data from the connected cars are processed in real-time and stored for historical analysis and reporting. Read more about “Kafka for Digital Twin Architectures” here.
I wrote a whole blog series with many more practical use cases and architecture for Apache Kafka and MQTT to learn more.
Serverless data streaming enables focusing on IoT business applications and improving OEE
An event-driven data streaming platform is elastic and highly available. It represents an opportunity to increase production facilities’ overall asset effectiveness significantly.
With the help of their data processing and integration capabilities, data streaming complements machine connectivity via MQTT, OPC UA, HTTP, among others. This allows streams of sensor data to be transported throughout the plant and to the cloud in near real-time. This is the basis for the use of Digital Twins as well as Modern Maintenance such as Condition Monitoring and Predictive Maintenance. The increased overall plant effectiveness not only enables manufacturing companies to work more productively and avoid potential disruptions, but also to save time and costs.
I did not talk about operating the infrastructure for data streaming and IoT. TL;DR: Go serverless if you can. That enables you to focus on solving business problems. The above example of BMW had exactly this motivation and leverages Confluent Cloud for this reason to roll out their smart factory use cases across the globe. “Serverless Kafka” is your best choice for data streaming if connectivity and the network infrastructure allow it in your IoT projects.
Do you use MQTT or OPC UA with Apache Kafka today? What use cases? Or do you rely on the HTTP protocol because it is good enough and simpler to integrate? How do you decide which protocol to choose? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
