
‘Data Historian‘ is a well-known concept in Industrial IoT (IIoT). It helps to ensure and improve the Overall Equipment Effectiveness (OEE).
Data Historian has a lot in common with other industrial trends like digital twin or data lake: It is ambiguous; there is more than one definition. ‘Process Historian’ or ‘Operational Historian’ are synonyms. ‘Enterprise Historian’ is similar but more on enterprise level (plant or global infrastructure) while the ‘Operational Historian’ is closer to the edge. Historian software is often embedded or used in conjunction with standard DCS and PLC control systems.
The following is inspired by the articles ‘What is a Data Historian?’ from ‘Automated Results’ and ‘Operational Historian vs. Enterprise Historian: What’s the Difference?‘ from ‘Parasyn’ – two expert companies in the Industrial IoT space.
This blog post explores the relation between a data historian and event streaming, and why Apache Kafka might become a part of your ‘Data Historian 4.0’. This also requires the discussion if a ‘Data Historian 4.0’ is operational, enterprise level, or a mixture of both. As you can imagine, there is no single answer to this question…
Kafka as Data Historian != Replacement of other Data Storage, Databases or Data Lake
Just a short note before we get started:
The idea is NOT to use Kafka as single allrounder database and replace your favorite data storage! No worries 🙂 Check out the following blog post for more thoughts on this discussion:
Use Cases for a Data Historian in Industrial IoT (IIoT)
There are many uses for a Data Historian in different industries. The following is a shameless copy&paste from Automated Results’s article:
- Manufacturing site to record instrument readings
- Process (ex. flow rate, valve position, vessel level, temperature, pressure)
- Production Status (ex. machine up/down, downtime reason tracking)
- Performance Monitoring (ex. units/hour, machine utilization vs. machine capacity, scheduled vs. unscheduled outages)
- Product Genealogy (ex. start/end times, material consumption quantity, lot # tracking, product setpoints and actual values)
- Quality Control (ex. quality readings inline or offline in a lab for compliance to specifications)
- Manufacturing Costing (ex. machine and material costs assignable to a production)
- Utilities (ex. Coal, Hydro, Nucleur, and Wind power plants, transmission, and distribution)
- Data Center to record device performance about the server environment (ex. resource utilization, temperatures, fan speeds), the network infrastructure (ex. router throughput, port status, bandwidth accounting), and applications (ex. health, execution statistics, resource consumption).
- Heavy Equipment monitoring (ex. recording of run hours, instrument and equipment readings for predictive maintenance)
- Racing (ex. environmental and equipment readings for Sail boats, race cars)
- Environmental monitoring (ex. weather, sea level, atmospheric conditions, ground water contamination)
Before we talk about the capabilities of a data historian, let’s first think of why this concept exists…
Overall Equipment Effectiveness (OEE)
Overall Equipment Effectiveness (OEE) “is the gold standard for measuring manufacturing productivity. Simply put – it identifies the percentage of manufacturing time that is truly productive. An OEE score of 100% means you are manufacturing only Good Parts, as fast as possible, with no Stop Time. In the language of OEE that means 100% Quality (only Good Parts), 100% Performance (as fast as possible), and 100% Availability (no Stop Time).”
One of the major goals of OEE programs is to reduce and / or eliminate the most common causes of equipment-based productivity loss in manufacturing (called the ‘Six Big Losses‘):
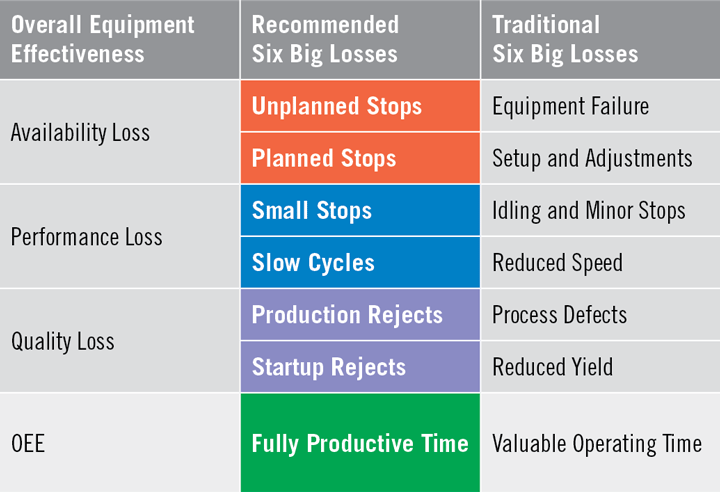
How does a Data Historian help reducing and / or eliminating the Six Big Losses?
Capabilities of a Data Historian
A Data Historian supports ensuring and improving the OEE:
The data historian contains the following key components to help implementing factory automation and process automation:
- Integration: Collect data from PLCs (Programmable Logic Controllers), DCS (Distributed Control System), proprietary protocols, and other systems. Bidirectional communication to send control commands back to the actors of the machines.
- Storage: Store data for high availability, re-processing and analytics.
- Processing: Correlate data over time. Join information from different systems, sensors, applications and technologies. Some examples: One lot of raw material to another, one continuous production run vs. another, day shift vs. evening or night shift, one plant vs. another.
- Access: Monitor a sensor, machine, production line, factory or global infrastructure. Real time alerting, reporting, batch analytics and machine learning / deep learning.
- Cloud: Move data to the cloud for aggregation, analytics, backup. A combination of hybrid integration and edge computing is crucial in most use cases, though.
- Security: Add authentication, authorization, encryption. At least for external interfaces outside the factory.
These features are often very limited and proprietary in a traditional data historian. Therefore, Kafka might be a good option for parts of this; as we see later in this post.
Before I map these requirements to Kafka-based infrastructure, let’s think about the relation and difference between OT, IT, and Industry 4.0. We need to understand why there is so much demand to change from traditional Data Historians to modern, open, scalable IoT architectures…
The Evolution of IT-OT Convergence
For many decades, automation industry was used to proprietary technologies, monoliths, no or very limited network connectivity, and no or very limited security enforcement (meaning authentication, authorization and encryption, NOT meaning safety which actually is in place and crucial).
The evolution of convergence between IT (i.e. software and information technology) and OT (i.e. factories, machines and industrial automation) is changing this:
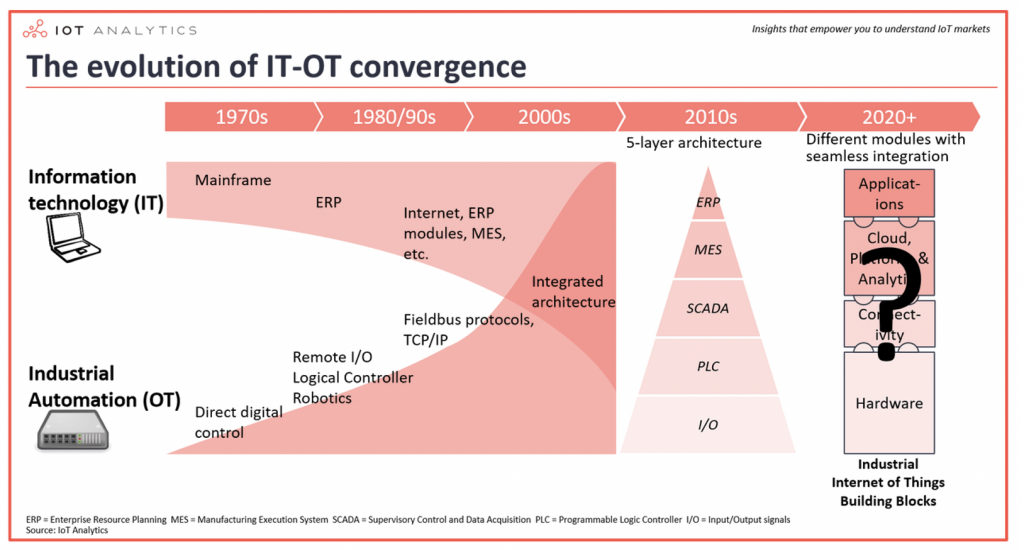
Let’s thinks about this convergence in more details from a simplified point of view:
OT => Uptime
OT’s main interest is uptime. Typically 99,999+%. Operations teams are not “that much” interested in fast turnaround times. Their incentive is to keep the production lines running for 10+ years without changes or downtime.
IT => Business Value
IT’s main interest is business value. In the last decade, microservices, DevOps, CI/CD and other agile paradigms created a new way of thinking. Originated at the Silicon Valley tech giants with millions of users and petabytes of data, this is now the new normal in any industry. Yes, even in automation industry (even though you don’t want to update the software of a production line on a daily basis). This is where ‘Industry 4.0’ and similar terms come into play…
Industry 4.0 => OT + IT
Industry 4.0 is converging OT and IT. This digital transformation is asking for new characteristics of hardware and software:
- Real time
- Scalability
- High availability
- Decoupling
- Cost reduction
- Flexibility
- Standards-based
- Extensibility
- Security
- Infrastructure-independent
- Multi-region / global
In 2020, the above points are normal in IT in many projects. Cloud-native infrastructures, agile DevOps, and CI/CD are used more and more to be competitive and / or innovative.
Unfortunately, we are still in very early stages in OT. At least, we are getting some open standards like OPC-UA for vendor-neutral communication.
Shop Floor, Top Floor, Data Center, Cloud, Mobile, Partner…
The more data is integrated and correlated, the more business value can be achieved. Due to this, convergence of OT and IT goes far beyond shop floor and top floor. The rest of the enterprise IT architecture gets relevant, too. This can be software running in your data center or the public cloud.
Hybrid architectures become more and more common. Integration with 3rd party applications enables quick innovation and differentiation while building sophisticated partnerships with other vendors and service providers.
As you can see, achieving the industry revolution 4.0 requires some new capabilities. This is where Event Streaming and Apache Kafka come into play.
Apache Kafka and Event Streaming in Automation Industry / IIoT
Apache Kafka can help reducing and / or eliminating the Six Big Losses in manufacturing by providing data ingestion, processing, storage and analytics in real time at scale without downtime.
I won’t cover in detail what Apache Kafka is and why people use it a lot in automation industry and Industry 4.0 projects. I covered this in several posts, already:
- Apache Kafka is the New Black at the Edge in Industrial IoT, Logistics and Retailing
- IIoT Data Integration and Processing with Apache Kafka, KSQL and Apache PLC4X
- Apache Kafka as Digital Twin for Open, Scalable, Reliable Industrial IoT (IIoT)
- IoT Architectures for Digital Twin with Apache Kafka
- Apache Kafka and Machine Learning for Real Time Supply Chain Optimization in IIoT
Please note that Apache Kafka is not the allrounder for every problem. The above posts describe when, why and how to complement it with other IoT platforms and frameworks, and how to combine it with existing legacy data historians, proprietary protocols, DCS, SCADA, MES, ERP, and other industrial and non-industrial systems.
10 Reasons for Event Streaming with Apache Kafka in IIoT Initiatives
Why is Kafka a perfect fit for IIoT projects? Here you go with the top 10 arguments I heard from project teams in the automation industry:
- Real Time
- Scalable
- Cost Reduction
- 24/7 – Zero downtime, zero data loss
- Decoupling – Storage, Domain-driven Design
- Data (re-)processing and stateful client applications
- Integration – Connectivity to IoT, legacy, big data, everything
- Hybrid Architecture – On Premises, multi cloud, edge computing
- Fully managed cloud
- No vendor locking
Even several well-known vendors in this space use Kafka for their internal projects instead of internal IIoT products. Often, IIoT platforms have OEM’d several different legacy platforms for middleware, analytics and other components. This embedded zoo of technologies does not solve the requirements of IIoT projects in the year 2020.
Architecture: Kafka as Data Historian 4.0
The following architecture shows one possible option to build a data historian with Kafka:
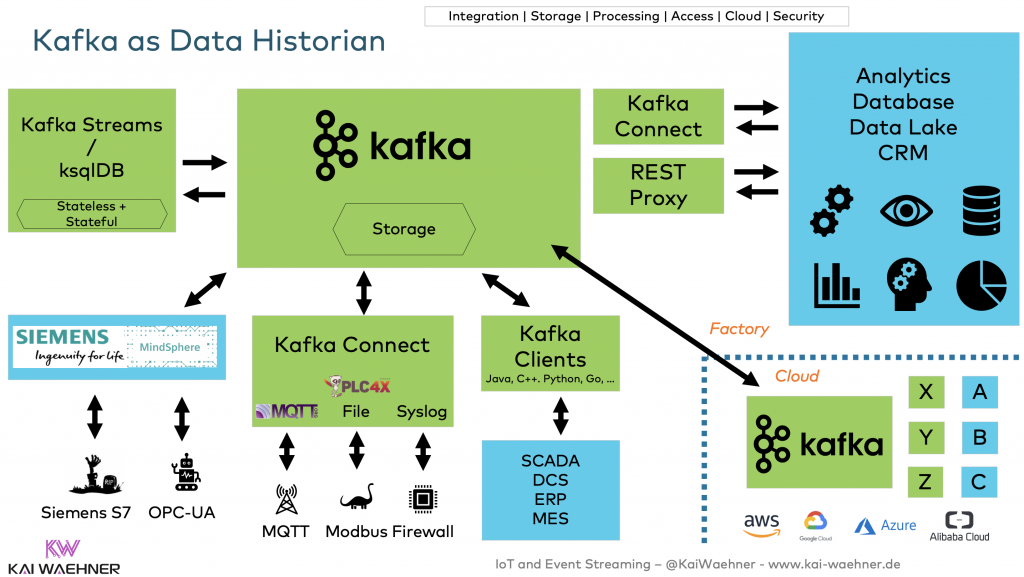
This is just one sample architecture. Obviously, individual components can be added or removed. For example, existing Data Historians, HMI (Human-Machine-Interface) or SCADA systems, or another IoT platform or stream processing engine can complement or replace existing components.
Remember: Extensibility and flexibility are two key pillars of a successful IIoT project. Unfortunately, many IoT platforms miss these characteristics, similar like they often don’t provide scalability, elasticity or high throughput.
I have also seen a few companies building an enterprise data historian using “traditional data lake software stack”: Kafka, Hadoop, Spark, NiFi, Hive and various other data lake technologies. Here, Kafka was just the ingestion layer into HDFS or S3. While it is still valid to build a data lake with this architecture and these technologies, the three main drawbacks are:
- The central data storage is data at rest instead real time
- A zoo of many complex technologies
- Not applicable for edge deployments due to its zoo of technologies and complex infrastructure and architecture
I won’t go into more detail here; there is always trade-offs for both approaches. The blog post ‘Streaming Machine Learning with Tiered Storage and Without a Data Lake‘ discusses the pros and cons of a simplified architectures without a data lake.
With this in mind, let’s now go back to the key pillars of a Data Historian in the Industrial IoT and see how these fit to the above architecture.
Data Integration / Data Ingestion
When talking about a data historian or other IoT architectures, some vendors and consultants call this component “data ingestion”. I think this is really unfortunate for three reasons:
- Data Ingestion often includes many more tasks than just sending data from the data source to the data sink. Think about filtering, enrichment-on-the-fly or type conversion. These things can happen in a separate process, but also as part of the “ingestion”.
- Data Ingestion means sending data from A to B. But the challenge is not just the data movement, but also the connectivity. Connectors provide the capability to integrate with a data source without complex coding; guaranteeing reliability, fail-over handling and correct event order.
- Data Ingestion means you send data from the data source to the data sink. However, in many cases the real value is created when your IoT infrastructure establishes bi-directional integration and communication; not just for analytics and monitoring, but commands command & control, too.
Data Sources
A data historian often has various industrial data sources, such as PLCs, DCS (Distributed Control System), SCADA, MES, ERP, and more. Apache PLC4X, MQTT, or dedicated IIoT Platforms can be used for data ingestion and integration.
Legacy vs. Standards for Industrial Integration
Legacy integration is still the main focus in 2020, unfortunately: Files, proprietary formats, old database technologies, etc.
OPC-UA is one option for standardized integration. This is only possible for modern or enhanced old production lines. Some machine support other interfaces like MQTT or REST Web Services.
No matter if you integrate via proprietary protocols or open standards: The integration typically happens on different levels. While OPC-UA, MQTT or REST interfaces provides critical information, some customers also want to directly integrate raw Syslog streams from machine sensors. This is much higher throughput (of less important data). Some customers also want to directly integrate with their SCADA monitoring systems.
Integration with the Rest of the Enterprise
While various industrial data sources need be integrated, this is still only half the story: The real added value is created when the data historian also integrates with the rest of the enterprise beyond IIoT machine and applications. For instance, CRM, Data Lake, Analytics tools, Machine Learning solutions, etc.
Plus hybrid integration and bi-directional communication between factories in different regions and a central cluster (edge <–> data center / cloud). Local edge processing in real time plus remote replication for aggregation / analytics is one of the most common hybrid scenarios.
Kafka Connect / Kafka Clients / REST Proxy for Data Integration
Kafka Connect is a Kafka-native integration solution providing connectors for data source and data sinks. This includes connectivity to legacy systems, industrial interfaces like MQTT and modern technologies like big data analytics or cloud services. Most IIoT platforms provide their own Kafka connectors, too.
If there is no connector available, you can easily connect directly via Kafka Client APIs in almost every programming language, including Java, Scala, C++, C, Go, Python, JavaScript, and more. Confluent REST Proxy is available for bidirectional HTTP(S) communication to produce and consume messages.
Data Storage
Kafka is not just a messaging system. The core of Kafka is a distributed commit log to storage events as long as you want or need to. The blog post “Is Kafka a Database?” covers all the details to understand when Kafka is the right storage option and when it is not.
Tiered Storage for Reduce Cost, Infinite Storage and Elastic Scalability
In summary, Kafka can store data forever. Tiered Storage enables separation of storage and processing by using a remote object store (like AWS S3) for infinite storage, low cost and elastic scalability / operations.
Stateful Kafka Client Applications
Kafka is not just the server side. A Kafka application is (or should be) a distributed application with two or more instances to provide high availability and elastic scalability.
Kafka applications can be stateless (e.g. for Streaming ETL) or stateful. The latter is used to build materialized views of data (e.g. aggregations) or business applications (e.g. a predictive maintenance real time app). These clients store data in the client (either in memory or on disk) for real time processing. Zero-data loss and guaranteed processing order are still ensured because Kafka applications leverage the Kafka log as “backup”.
Data Processing
Data Processing adds the real value to your data historian. Validation, enrichment, aggregation and correlation of different data streams from various data sources enable insightful monitoring, proactive alerting and predictive actions.
Real time Supply Chain Management
Supply Chain Management (SCM) with Just in Time (JIT) and Just in Sequence (JIS) inventory strategies is a great example: Correlate the data from the production line, MES, ERP and other backend systems like CRM. Apply the analytic model trained in the data lake for real time scoring to make the right prediction about ordering parts from a partner.
I did a webinar with Expero recently to discuss the benefits of “Apache Kafka and Machine Learning for Real Time Supply Chain Optimization in IIoT“.
Stream Processing with Kafka Streams / ksqlDB
Kafka Streams (Java, part of Apache Kafka) / ksqlDB (SQL, Confluent)) are two open source projects providing Kafka-native stream processing at scale in real time.
These frameworks can be used for “simple” Streaming ETL like filtering or enrichments. However, powerful aggregations of different streams can be joined to build stateful applications. You can also add custom business logic to implement your own business rules or apply an analytic model for real time scoring.
Check out these examples on Github to see how you can implement scalable Machine Learning applications for real time predictions at scale: Kafka Streams examples with TensorFlow and KSQL with H2O.ai.
Data Access
A modern data historian is more than HMI and SCADA. Industry 4.0 with more and more streaming data requires real time monitoring, alerting and analytics at scale with an open architecture and ecosystem.
Human-Machine Interface (HMI) and Supervisory Control and Data Acquisition (SCADA)
A Human-Machine Interface (HMI) is a user interface or dashboard that connects a person to a machine, system, or device in the context of an industrial process. A HMI allows to
- visually display data
- track production time, trends, and tags
- oversee key performance indicators (KPI)
- monitor machine inputs and outputs
- and more
Supervisory Control and Data Acquisition (SCADA) systems collect and record information or connect to databases to monitor and control system operation.
HMI and SCADA solutions are typically proprietary solutions; often with monolith, inflexible and non-scalable characteristics.
Kafka as Next Generation HMI, Monitoring and Analytics
Kafka can be used to build new “HMIs” to do real time monitoring, alerting and analytics. This is not a replacement of existing technologies and use cases. HMI and SCADA worked well in the last decades for what they were built. Kafka should complement existing HMI and SCADA solutions to process big data sets and implement innovative new use cases!
Analytics, Business Intelligence and Machine Learning in Real Time at Scale
HMI and SCADA systems are limited, proprietary monoliths. Kafka enables the combination of your industrial infrastructure with modern technologies for powerful streaming analytics (Streaming Push vs. Pull Queries), traditional SQL-native Business Intelligence (with Tableau, Qlik, Power BI or similar tools), and analytics (with tools like TensorFlow or Cloud ML Services).
Kafka Connect is used to integrate with your favorite database or analytics tool. For some use cases, you can simplify the architecture and “just” use Kafka-native technologies like ksqlDB with its Pull Queries.
Data Historian in the Cloud
The cloud is here to stay. It has huge advantages for some scenarios. However, most companies are very cautious linking internal processes and IT systems to the cloud. Often, it is even hard to just get access to a computer at the shop floor or top floor via TeamViewer to adjust problems.
The rule of thumb in Automation Industry: No external access to internal processes! Companies ask themselves: Do I want to use a commercial 3rd party cloud to store and process data our proprietary and valuable data? Do we want to trust our IP to other people in cloud on the other side of the world?
Edge and Hybrid IoT Architectures
There is a lot of trade-offs and cloud has many benefits, too. In reality, edge and hybrid architectures are the new black in the very conservative Industrial IoT market. This totally makes sense as factories and production lines will stay on premise anyway. It does not make sense to send all the big data sets to the cloud. This has huge implications on cost, latency and security.
Architecture Patterns for Distributed, Hybrid, Edge and Global Apache Kafka Deployments
Kafka is deployed in various architectures depending on the scenario and use case. Edge deployments are as common as cloud infrastructures and hybrid bidirectional replication scenarios. Check out this blog post for more details; covering several IoT architectures:
Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments
Security
No matter if you decide to move data to the cloud or not: Security is super important for Industry 4.0 initiatives.
While the use cases for a data historian are great, security is key for success! Authentication, Authorization, encryption, RBAC (Role Based Access Control), Audit logs, Governance (Schema Enforcement, Data Catalog, Tagging, Data Lineage, …) etc. are required.
Many shop floors don’t have any security at all (and therefore no internet / remote connection). As machines are built to stay for 20, 30 or 40 years, it is not easy to adjust existing ones. In reality, the next years will bring factories a mix of old proprietary non-connected legacy machines and modern internet-capable new machines.
From the outside (i.e. a monitoring application or even another data center), you will probably never get access to the insecure legacy machine. The Data Historian deployed in the factory can be used as termination point for these legacy machines. Similar to SSL Termination in an internet proxy. Isolating insecure legacy machines from the rest with Kafka is a common pattern I see more and more.
Kafka behaves as gateway from a cybersecurity stand point between IT and OT systems yet providing essential information to any users who may contribute to operating, designing or managing the business more effectively. Of course, security products like a security gateway complements the data streaming of Kafka.
Secure End-to-End Communication with Kafka
Kafka supports open standards such as SSL, SASL, Kerberos, OAuth and so on. Authentication, Authorization, Encryption, RBAC, Audit logs and Governance can to be configured / implemented.
This is normality in most other industries today. In the automation industry, Kafka and its ecosystem can provide a secure environment for communication between different systems and for data processing. This includes edge computing, but also the remote communication when replacing data between the edge and another data center or cloud.
Kafka as Data Historian to Improve OEE and Reduce / Eliminate the Sig Big Losses
Continuous real time data ingestion, processing and monitoring 24/7 at scale is a key requirement for successful Industry 4.0 initiatives. Event Streaming with Apache Kafka and its ecosystem brings huge value to implement these modern IoT architectures.
This blog post explored how Kafka can be used as a component of a Data Historian to improve the OEE and reduce / eliminate the most common causes of equipment-based productivity loss in manufacturing (aka Six Big Losses).
Kafka is not an allrounder. Understand it’s added value and differentiators in IoT projects compared to other technologies; and combine it the right way with your existing and new Industrial IoT infrastructure.
