
This blog explores the evolution of low-code/no-code tools, their challenges, when (not) to use visual coding, and how generative AI and data streaming with Apache Kafka and Flink are reshaping the software and data engineering landscape.
Low-code/no-code tools have been praised as transformative for software development and data engineering, providing visual interfaces that democratize technology access for non-technical users. However, the low-code / no-code space—saturated with hundreds of vendors and tools—faces challenges in scalability, consistency, and integration.
Generative AI is emerging as a powerful alternative, offering unprecedented flexibility and customization while addressing the limitations of traditional low-code/no-code solutions.
At the same time, the data ecosystem is undergoing a broader transformation, where tools like Apache Kafka and Flink are enabling real-time, consistent data streaming architectures that resolve long-standing inefficiencies inherent in batch-driven, tool-fragmented systems.

Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch.
What Are Low-Code/No-Code Tools?
Low-code and no-code platforms aim to simplify application development, data engineering, and system integration by offering graphical drag-and-drop visual coding interfaces. Instead of requiring coding expertise, users can configure workflows using pre-built components.
These tools are used for:
- Enterprise Application Integration (EAI): Connecting business systems like CRM, ERP, and databases.
- ETL Pipelines: Extracting, transforming, and loading data for analytics and reporting.
- AI/ML Workflows: Automating data preparation and machine learning pipelines.
- Process Automation: Streamlining repetitive tasks in business processes.
While the idea is to empower “citizen developers” or non-technical users, these tools often target a broad range of use cases and industries. The market is vast, encompassing self-managed tools for on-premises environments, Software-as-a-Service (SaaS) platforms, and cloud provider-specific solutions like AWS Step Functions or Google Cloud Dataflow.
The History of Visual Software Development and Data Engineering
The concept of visual development in software traces its roots back to the 1990s when tools like Informatica and TIBCO introduced graphical interfaces for enterprise integration. These platforms offered drag-and-drop components to simplify the creation of workflows for data movement, transformation, and application integration. Their ease of use attracted enterprises seeking to streamline operations without building large software engineering teams.
In the 2000s, visual coding evolved further with the rise of specialized tools tailored to emerging domains. Open-source platforms like Apache NiFi and Apache Airflow built on this concept, providing powerful visual interfaces for data flow automation, enabling organizations to design pipelines for extracting, transforming, and loading (ETL) data across distributed systems. Meanwhile, vendors like IBM Streams and Software AG Apama pioneered visual stream processing tools, addressing the need for real-time analytics in domains such as financial trading and telecommunications.
As Internet of Things (IoT) technologies gained traction, visual coding tools like Node-RED emerged, offering accessible interfaces for developers and engineers to create and orchestrate IoT workflows. By combining simplicity with modular design, Node-RED became a popular choice for IoT applications, allowing developers to integrate devices, sensors, and APIs without extensive coding knowledge.
The Role of Visual Coding in Data Science and Cloud Transformation
Visual development also made inroads into data science and data engineering, with frameworks offering simplified interfaces for complex tasks:
- Tools such as KNIME, RapidMiner, and Azure Machine Learning Studio introduced visual workflows for building, training, and deploying machine learning models.
- Cloud-based platforms like Google Cloud Dataflow, AWS Glue, and Databricks brought visual development partly to the cloud (less sophisticated than on-premise IDEs from Informatica et al), allowing users to harness scalable computing resources for data engineering tasks with minimal coding effort.
The cloud revolution fundamentally changed the landscape for visual coding by democratizing access to computational power and enabling real-time collaboration. Developers could now design, deploy, and monitor pipelines across globally distributed environments, leveraging pre-built templates and visual interfaces. This shift expanded the reach of visual coding, making it accessible to a broader range of users and enabling integration across hybrid and multi-cloud architectures.
Challenges of Low-Code/No-Code Tools
Despite their promise, low-code/no-code tools face significant challenges that limit their utility for modern, complex environments. Let’s look into these challenges:
1. Fragmentation and the Data Mess
The low-code/no-code market is overwhelmed with hundreds of vendors and tools, each targeting specific use cases. From SaaS platforms to on-premises solutions, different business units often adopt their own tools for similar tasks. This creates a fragmented ecosystem where:
- Data Silos Form: Different teams use different tools, resulting in disconnected data pipelines.
- Duplicated Processing: Each unit reprocesses the same data with different tools, increasing operational inefficiencies.
- Inconsistent Standards: Variations in tool capabilities and configurations lead to inconsistent data quality and formats.
2. The Technical Limitations of Visual Development
While drag-and-drop interfaces simplify basic workflows, they stumble with more complex requirements:
- Advanced data transformations often require writing custom User-Defined Functions (UDFs).
- External libraries and API integrations still demand traditional coding expertise.
- Debugging and troubleshooting visual workflows can be more cumbersome than inspecting raw code.
3. Software Engineering Overhead
Low-code/no-code solutions cannot eliminate the underlying complexities of software development. Teams still need to:
- Integrate workflows with version control systems like Git.
- Implement DevOps practices for CI/CD pipelines, deployment automation, and monitoring.
- Ensure scalability and fault tolerance, often necessitating custom workarounds beyond what the tools provide.
4. Batch and Bursty Data Processing
Many low-code/no-code tools focus on batch data processing, which introduces latency and fails to address real-time requirements. This is particularly problematic in environments with:
- Bursty Data Pipelines: Sudden spikes in data volume that overwhelm batch workflows.
- Data Consistency Needs: Delays in batch processing can lead to out-of-sync data across systems.
Tools like Apache Kafka excel here by decoupling systems with event-driven architectures that ensure consistent, accurate, and timely data delivery. Unlike batch systems, Kafka’s immutable logs and distributed processing model provide a unified approach to ingest, process, and stream data with consistency across pipelines.
How Generative AI Changes the Game for Visual Coding and Low-Code/No-Code Tools
Generative AI is emerging as a more effective alternative to low-code/no-code tools by enabling dynamic, scalable, and highly customizable workflows. English is the next generation programming language. Here’s how:
1. Customizable Code Generation
Generative AI can create tailored code for specific use cases based on natural language prompts, making it far more adaptable than pre-built drag-and-drop components. Examples include:
- Writing SQL queries, Python scripts, or API integrations.
- Automating infrastructure setup with Terraform or Kubernetes scripts.
2. Empowering All Users
Generative AI bridges the gap between non-technical users and software engineers:
- Business analysts can generate prototypes with natural language instructions.
- Data engineers can refine AI-generated scripts for performance and scalability.
3. Reducing Tool Fragmentation
Generative AI works across platforms, frameworks, and ecosystems, mitigating the vendor lock-in associated with low-code/no-code tools. It unifies workflows by generating code that can run in any environment, from on-premises systems to cloud-native architectures.
4. Accelerating Complex Tasks
Unlike low-code/no-code tools, generative AI excels in creating sophisticated logic, such as:
- Real-time data pipelines using Kafka and Flink.
- Event-driven architectures that handle high throughput and low latency.
When to Use Visual Coding?
Visual coding tools shine in specific scenarios, particularly when simplicity and clarity are key. While they may struggle with complex, production-grade systems, they offer undeniable value in the following areas:
- Demos and Stakeholder Engagement: Visual tools are perfect for demos, proof of concepts (POCs), and pre-sales discussions, allowing teams to quickly build prototypes and illustrate workflows. Their simplicity helps align stakeholders and communicate ideas effectively, making them invaluable during early project stages.
- Collaboration and Communication: Visual coding enables better collaboration between technical and non-technical teams by providing clear, graphical workflows. These tools facilitate discussions with business users and executives, making it easier to align on project goals and workflow designs without diving into technical details.
- Simple Tasks and Quick Wins: For straightforward workflows, such as basic data transformations or integrations, visual tools offer rapid results. They simplify tasks that don’t require heavy customization, making them ideal for quick automations or small-scale projects.
Despite their strengths, visual coding tools face challenges with complex logic, DevOps needs (e.g., versioning, automation), and scalability. They’re often best suited for prototyping, with the final workflows transitioning to robust, code-based solutions using tools like Apache Kafka and Flink.
By leveraging visual coding where it excels—early discussions, stakeholder alignment, and simple workflows—teams can accelerate initial development while relying on scalable, code-based systems for production.
The Shift Left Architecture To Solve the Inefficiencies of Tool Fragmentation
Modern organizations are moving toward an event-driven architecture leveraging the Shift Left Architecture to address the inefficiencies of batch-driven systems and tool fragmentation.
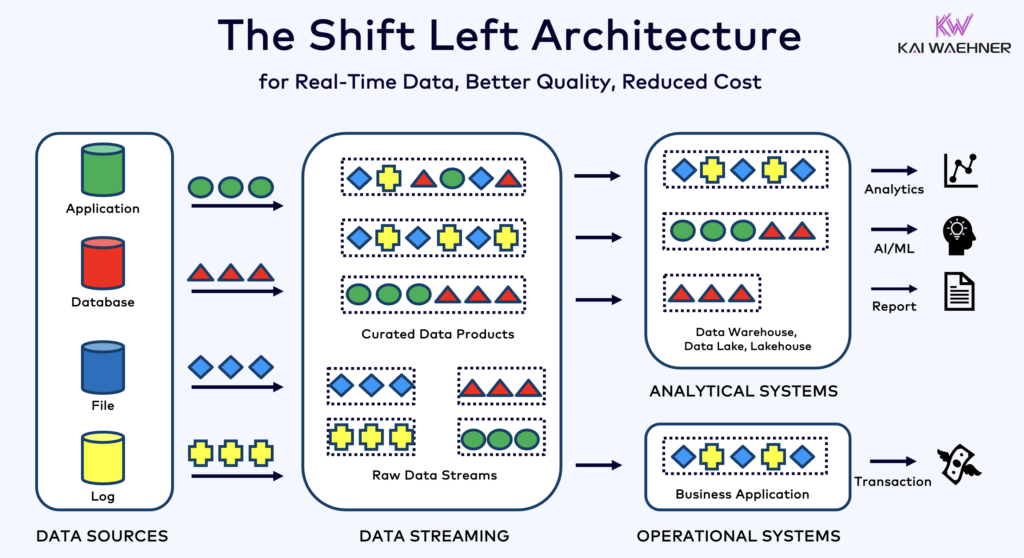
This approach emphasizes:
- Real-Time Data Products: Using Kafka and Flink to build pipelines that process and deliver insights continuously.
- Unified Processing: Consolidating tools into a cohesive, event-driven framework that eliminates data silos and duplicate processing.
- Decentralized Ownership: Empowering teams to build pipelines with reusable components that align with organizational standards.
- Freedom to Choose Tools: Allowing teams to select their preferred tools, whether low-code, no-code, or custom-coded solutions, while ensuring seamless integration through a unified, event-driven architecture.
By shifting left, businesses can achieve faster insights, better data quality, and reduced operational overhead, but still choose the favorite low-code/no-code tool or programming language.
Bridging the Gap with No-Code and Low-Code in Data Streaming
In modern organizations, each business unit operates with unique tools and expertise. Some teams write custom code, others leverage generative AI for tailored solutions, and many prefer the simplicity of no-code or low-code tools. Data streaming, powered by event-driven architectures like Apache Kafka and Flink, serves as the critical backbone to unify these approaches, enabling seamless integration and real-time data sharing across the enterprise.
A prime example is Confluent Cloud’s Flink Actions, which simplifies stream processing for non-technical users while also providing value to experienced engineers. Similar to term completion, auto-imports, and automation features in IDEs, Flink Actions eliminates unnecessary effort—allowing engineers to bypass repetitive coding tasks with just a few clicks and focus on higher-value problem-solving instead
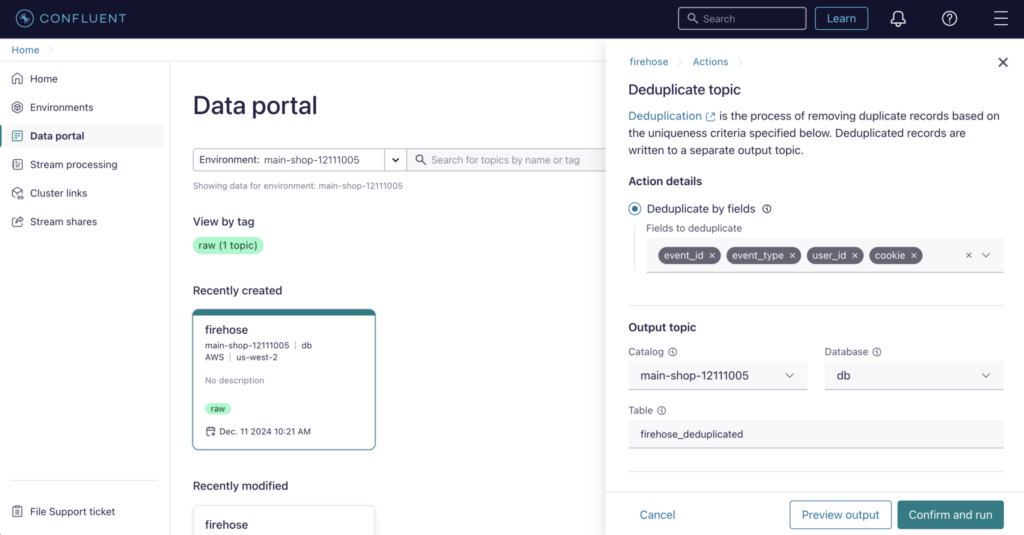
With an intuitive interface, business analysts and operational teams can design and deploy data streaming workflows—such as ETL transformations, deduplication, or data masking—without writing a single line of code leveraging the low-code / no-code web UI. These tools empower citizen integrators to contribute directly to real-time data initiatives, reducing time-to-value while maintaining the scalability and performance of Apache Kafka and Flink.
By decoupling workflows through Kafka and democratizing access with low-code/no-code solutions like Flink Actions, organizations bridge the gap between technical and non-technical teams. This inclusive approach fosters collaboration, ensures data consistency, and accelerates innovation in real-time data processing.
The Evolution of Software Development and Data Engineering: Generative AI and Apache Kafka Redefine Low-Code/No-Code
Low-code/no-code tools have democratized certain aspects of software development but struggle to scale and integrate into modern, real-time architectures. Generative AI, by contrast, empowers both citizen developers and seasoned engineers to create robust, flexible workflows with unprecedented ease.
Data streaming with Apache Kafka and Flink addresses key inefficiencies and fragmentation caused by low-code/no-code tools, ensuring better integration, consistency, and performance:
- Data Consistency Across Pipelines: Kafka’s immutable logs ensure data remains accurate and reliable, even during high-volume or bursty events. It seamlessly handles a mix of real-time streams, batch processes, and request-response APIs, making it ideal for diverse data sources and sinks.
- Data Quality Across Systems: Kafka acts as a unified backbone for data movement, eliminating the silos created by fragmented ecosystems of low-code/no-code tools. Its scalable, event-driven architecture ensures that all data platforms, regardless of independence, are aligned and reliable.
- Improved Performance: Kafka’s event-driven design, paired with Flink’s processing capabilities, delivers low-latency, real-time insights. For modern use cases and projects, real-time data streaming outperforms traditional, slower batch methods, offering a competitive edge in today’s quickly changing environments.
- Cost Efficiency at Scale: By consolidating workflows into a single, scalable data streaming platform, Kafka reduces the need for multiple, often redundant low-code/no-code tools. This streamlined approach minimizes maintenance, licensing, and infrastructure costs, providing a more efficient path to long-term ROI.
Generative AI and data streaming are complementary forces that enable organizations to simplify development while ensuring real-time, consistent, and scalable data architectures. Together, they mark the next evolution in how businesses approach technology: moving beyond visual coding to truly intelligent, integrated systems.
How do you use visual coding with low-code/no-code tools? Or do you prefer writing source code in your favorite programming language? How do GenAI and data streaming change your perspective? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





