Apache Kafka is the backbone of modern event-driven systems. It powers real-time use cases across industries. But deploying Kafka is not a one-size-fits-all decision. The right strategy depends on performance, compliance, and operational needs.
From self-managed clusters to fully managed services and Bring-Your-Own-Cloud (BYOC) models, each approach offers different levels of control, simplicity, and scalability. Selecting the right deployment model is a strategic decision that affects cost, agility, and risk.
This article outlines the most common Kafka cluster types and deployment strategies – including new innovations for synchronous multi-region replication with zero data loss (RPO=0). Understanding these options is critical to designing resilient, compliant, and future-ready data streaming platforms.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various data Kafka architectures and best practices.
Apache Kafka Cluster Type Deployment Strategies
Apache Kafka is the industry standard for real-time data streaming. It powers event-driven architectures across industries by enabling the processing of data as it happens. But Kafka is not a one-size-fits-all technology. The right deployment model depends on technical requirements, security policies, and business goals.

Kafka can be deployed in several ways:
- Self-Managed: Full control over infrastructure and configuration, but also full operational responsibility.
- Fully Managed / Serverless: Offered by vendors like Confluent Cloud. Ideal for speed, simplicity of operations, and elasticity.
- BYOC (Bring Your Own Cloud): Kafka runs in the customer’s own cloud VPC, giving more control over data locality, privacy, and compliance. Vendors like WarpStream have embraced this model with innovative, cloud-native architectures.
My article “Deployment Options for Apache Kafka: Self-Managed, Fully-Managed / Serverless and BYOC (Bring Your Own Cloud)” explores the details.
One Apache Kafka Cluster Type Does NOT Fit All Use Cases
Organizations rarely rely on just one Kafka cluster. Different applications have different performance, availability, compliance, and network requirements. That’s why enterprise architectures often consist of multiple Kafka clusters – each tailored to specific needs.
Here are some relevant Kafka cluster concepts:
- Single Region: Most common starting point. Simple to manage and monitor.
- Multi-Region: Supports disaster recovery or data locality requirements. Can use synchronous or asynchronous replication.
- Multi-Cloud: Useful for vendor neutrality, regional compliance, or availability across providers.
- Hybrid: Combines on-premise and cloud deployments. Common in migrations or where low-latency on-site processing is needed.
- Disaster Recovery (DR): Active-active or active-passive clusters to ensure business continuity. Typically uses asynchronous replication but can require RPO=0 setups.
- Aggregation: Regional clusters pre-process or filter events before forwarding data to a central analytics system.
- Migration: Used for IT modernization—shifting from legacy platforms or on-prem Kafka to cloud-native deployments.
- Edge: Kafka clusters running in disconnected or air-gapped environments (e.g., manufacturing, defense).
- Single Broker: For highly constrained environments like embedded systems or remote industrial PCs. Limited resilience, but useful in edge scenarios.
Each model brings its own trade-offs in latency, durability, cost, and complexity. Selecting the right architecture is critical to meeting SLAs and regulatory requirements.
Read more: Apache Kafka Cluster Type Deployment Strategies.
Apache Kafka vs. Kafka Protocol – Understanding the Difference
It’s important to distinguish between Apache Kafka, the open-source project, and the Kafka protocol, which defines the event-driven communication model used by Kafka clients and brokers.
More and more platforms implement the Kafka protocol without relying on Apache Kafka internally. This enables compatibility with the broader Kafka ecosystem—while rearchitecting the backend for different priorities like performance, resiliency, or operational simplicity.

Here are a few notable examples:
- WarpStream: Implements the Kafka protocol with a cloud-native architecture that uses object storage and distributed metadata services (like DynamoDB or Spanner). It’s designed for BYOC environments and optimized for durability, elasticity, and cost-efficiency.
- Azure Event Hubs: Offers Kafka-compatible APIs on top of a proprietary messaging backend. It enables easy integration with Kafka clients while providing Microsoft-native scalability and observability.
- Redpanda: A Kafka API-compatible platform written in C++ with no JVM dependencies. Redpanda focuses on low-latency, high-throughput workloads and markets itself as a drop-in Kafka replacement for performance-sensitive applications thought these assertions have been challenged.
These implementations show how the Kafka protocol has become the de facto standard for event streaming, beyond the boundaries of the Apache Kafka project itself. This separation allows vendors to innovate with different performance models, storage backends, and deployment patterns—while maintaining compatibility with Kafka producers, consumers, and connectors.
This architectural flexibility creates new opportunities; especially for scenarios that require RPO=0 with zero data loss, ultra-low latency, or specialized deployments such as edge computing or BYOC in regulated industries.
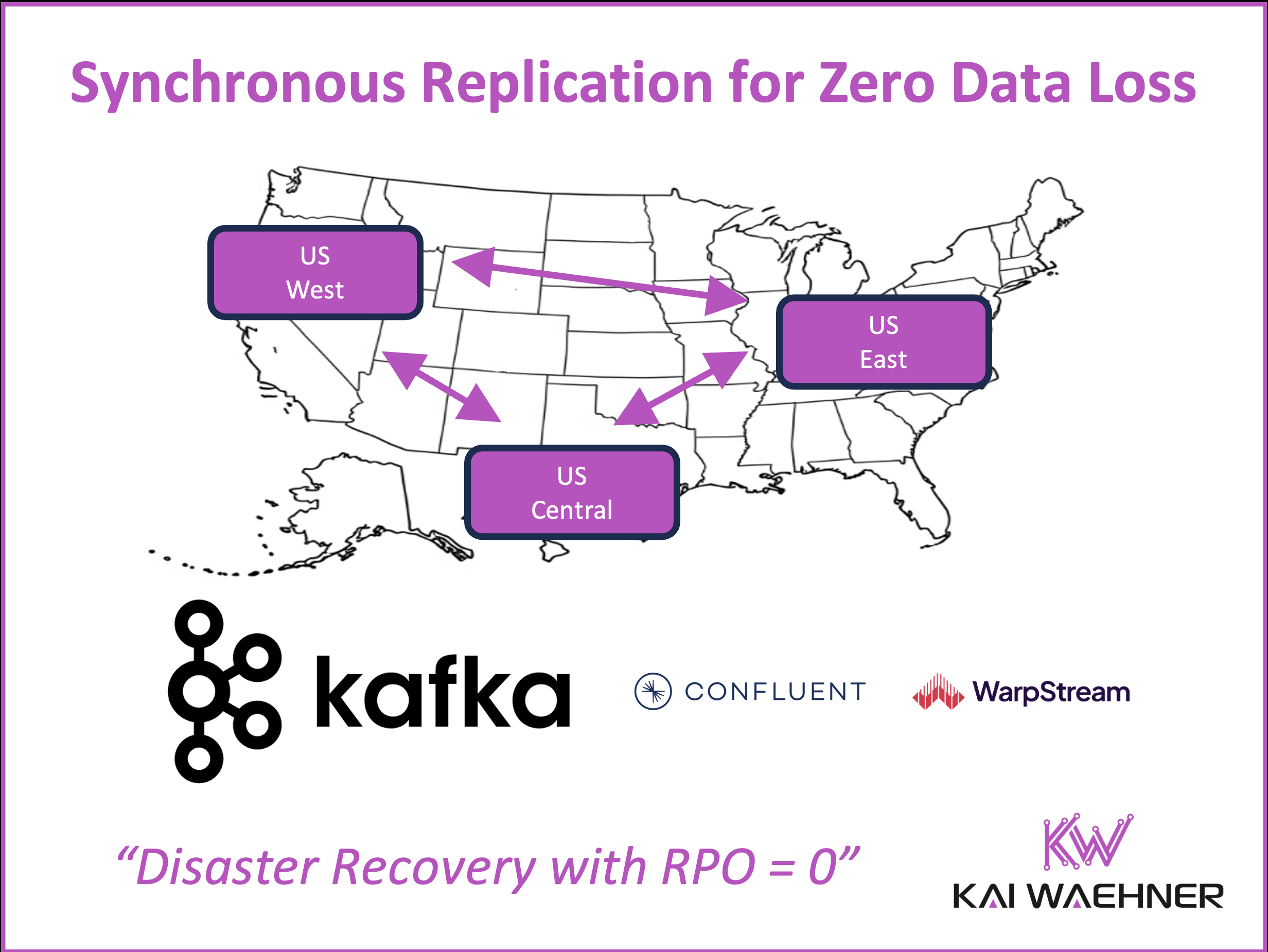
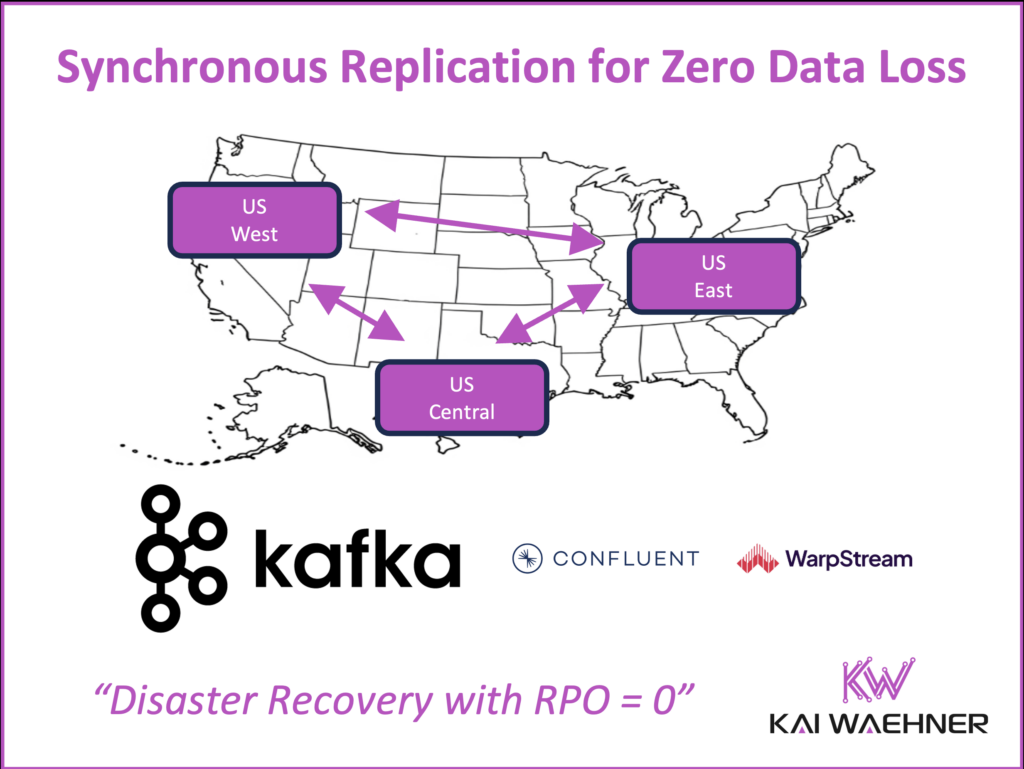
Synchronous Replication in a Kafka Cluster Across Regions for Zero Data Loss (RPO=0)
Achieving RPO=0 with zero data loss in a distributed system is a very difficult problem. Most Kafka deployments use asynchronous replication for disaster recovery. Tools like MirrorMaker, Confluent Replicator, and Cluster Linking work well for moving data between clusters or regions. But they can’t guarantee zero data loss. If disaster strikes during replication, data in transit can be lost.
Enter synchronous replication. This method acknowledges a write only after it’s confirmed in multiple locations. For Kafka, synchronous replication is possible through:
- Stretched Kafka Clusters: A single Kafka cluster stretched across multiple data centers or regions. It uses Kafka’s internal replication mechanism across brokers deployed in different locations. This approach is hard to operate because it requires tight network coordination across regions, leading to complex failure scenarios, high latency, and difficult recovery procedures.
- Confluent Multi-Region Clusters (MRC): A commercial solution that offers automated synchronous and asynchronous replication with built-in failover mechanisms. Observers are part of the asynchronous replication model, enabling remote regions to consume data locally without adding cross-region latency to producer write paths. MRC also adds additional capabilities that make operations simpler and more efficient, especially when compared to the complexity of managing stretched clusters.
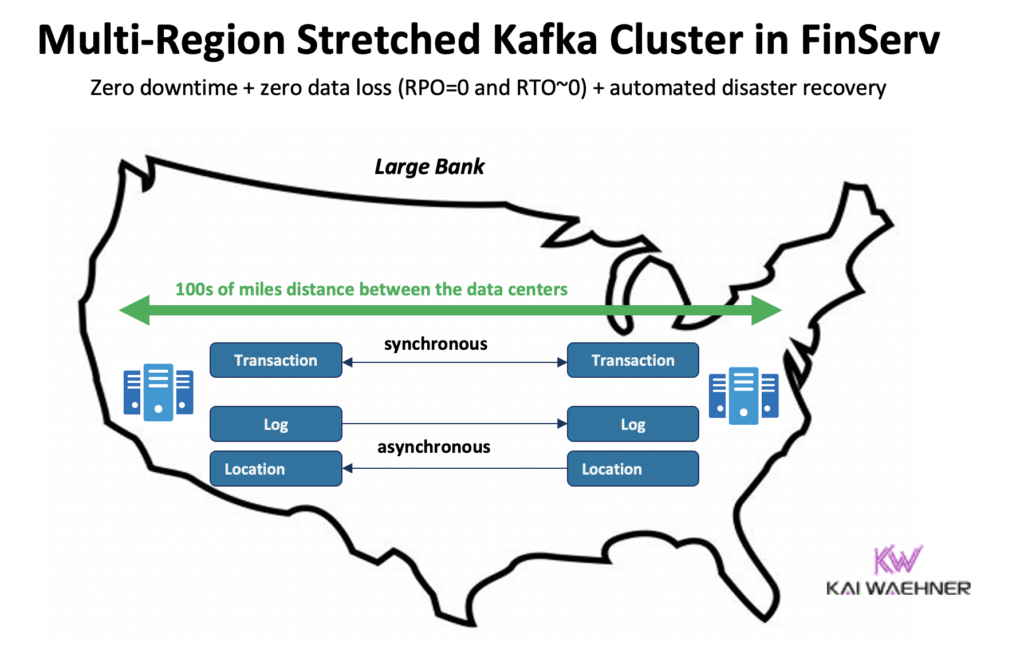
Synchronous replication guarantees that all committed data is durable across regions before acknowledging a write. But it comes with trade-offs:
- Higher latency (due to cross-region round-trips)
- Lower throughput
- Complex operations
- Higher cost (due to multi-region resources)
Despite these challenges, many mission-critical systems use synchronous replication. In regulated industries such as banking or healthcare, data loss is not acceptable – even during a regional failure.
WarpStream’s Innovation: Making Synchronous Replication Across Regions Simpler
WarpStream takes a new approach to Kafka. It implements the Kafka protocol – but not Apache Kafka. Under the hood, WarpStream leverages cloud-native services like Amazon S3 and DynamoDB or Google Spanner. This allows them to rethink Kafka replication and durability at a fundamental level.
The key innovation is zero trust BYOC (Bring Your Own Cloud). WarpStream runs its stateless data plane in the customer’s cloud VPC, but manages the control plane itself. This design allows for:
- No vendor access to customer infrastructure
- High durability by leveraging quorum writes to multiple object stores
- Seamless integration with multi-region cloud services
WarpStream Multi-Region Architecture for Zero Data Loss in Kafka Applications
WarpStream’s Multi-Region Clusters feature enables RPO=0 by:
- Writing data to a quorum of object storage buckets in multiple regions
- Storing metadata in multi-region control plane databases (DynamoDB Global Tables or Spanner)
- Only acknowledging writes after both data and metadata are safely replicated
- Automatically failing over to another region in case of outage
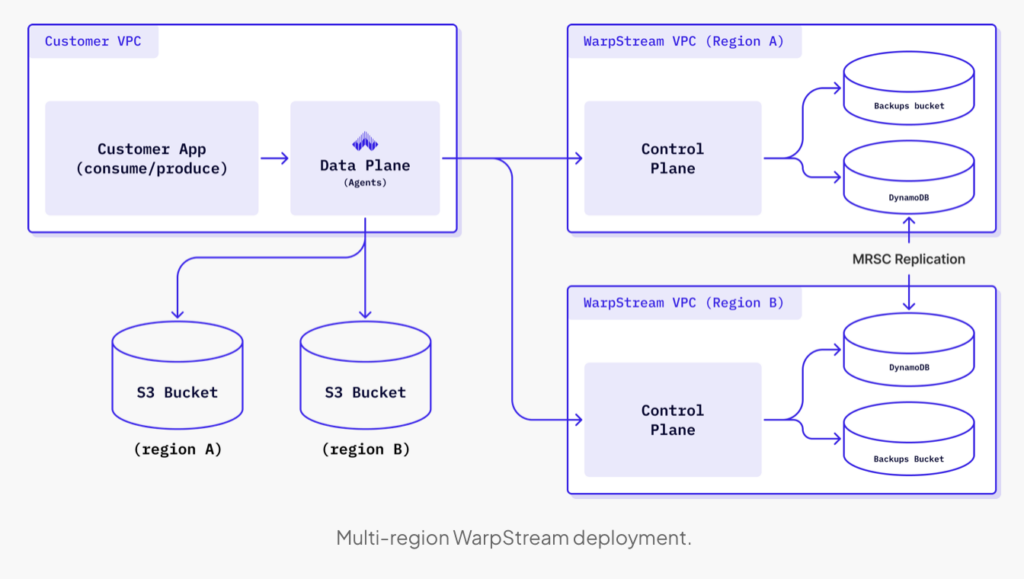
While this architecture delivers replication with strong durability guarantees and zero data loss, it is important to clarify that it differs from traditional Kafka synchronous replication models like stretched clusters. In those models, synchronous replication usually means keeping identical copies in lockstep across physical nodes or data centers.
WarpStream’s replication is synchronous in terms of consistency and acknowledgment logic: a write is only accepted once a quorum of object storage buckets confirms the data write, and a quorum of metadata replicas (e.g., across DynamoDB Global Tables) confirms the metadata update. This coordination is supported by DynamoDB’s Multi Region Strong Consistency (MRSC), which ensures transactional consistency across regions without needing to manually coordinate replication. The result is a cloud-native synchronous replication model—without the complexity of traditional stretched clusters.
Failover is completely automated and transparent. No manual intervention is needed. Even if a whole region disappears, data is not lost. This architecture allows WarpStream to offer a 99.999% uptime SLA, meaning no more than 26 seconds of downtime per month.
If you want to learn more technical details, read this excellent blog post from WarpStream’s Dani Torramilans: “No record left behind: How Warpstream can withstand cloud provider regional outages“.
The Trade-Offs: RPO=0 Comes with a Price
Synchronous replication provides strong data consistency but comes at a high cost: both in terms of infrastructure cost and performance overhead. Organizations must weigh the trade-offs:
- Latency: Multi-region writes require coordination across geographic distances. Expect an 80–100 ms increase in write latency compared to single-region deployments.
- Cost: Multi-region storage and control plane replication costs more. At launch, WarpStream’s multi-region clusters are gated to the Enterprise cluster tier, and storage and writes are (obviously) also priced higher than single-region clusters.
- Complexity: Although WarpStream automates failover, deploying and configuring multi-region clusters still requires planning and understanding of cloud regions, storage quorum, and network latency.
For these reasons, RPO=0 should only be applied to critical datasets. Most applications tolerate a few seconds – or even minutes – of potential data loss during a rare failure. For others, like financial transactions or regulated healthcare records, even a single lost message is unacceptable.
WarpStream’s innovation lies in making RPO=0 more accessible. Instead of managing complex stretched clusters, customers get a simplified architecture with the benefits of cloud-native services and automated failover. It’s a new path to high availability and durability; and built for Kafka use cases.
Strategic Considerations for Zero Data Loss in Data Streaming
As data streaming adoption grows, the focus shifts from system uptime to data integrity. For critical workloads, even the loss of a single event is unacceptable. This is where RPO=0 architectures with multi-region clusters and synchronous replication become essential.
Industry examples make this clear:
- Banking systems require zero data loss for transaction integrity and compliance.
- Telecom platforms rely on complete event capture for accurate billing and service continuity.
- Healthcare environments demand full data durability for patient safety and legal reasons.
- Cybersecurity solutions must retain every critical alert to ensure incident visibility and audit readiness.
Synchronous replication solutions, such as Confluent Multi-Region Clusters or WarpStream’s BYOC model, offer strong guarantees with reduced operational complexity. While these architectures come with trade-offs in cost and latency, they are justified for high-value or regulated data flows.
Zero data loss is no longer theoretical in the data streaming landscape. With the right tools and deployment strategy, it’s now a practical reality for mission-critical streaming use cases.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various data Kafka architectures and best practices.