Real-time beats slow data in most use cases across industries. The rise of event-driven architectures and data in motion powered by Apache Kafka enables enterprises to build real-time infrastructure and applications. This blog post explores why the Kafka API became the de facto standard API for event streaming like Amazon S3 for object storage, and the tradeoffs of these standards and corresponding frameworks, products, and cloud services.

Event-Driven Architecture: This Time It’s Not A Fad
The Forbes’ article “Event-Driven Architecture: This Time It’s Not A Fad” from April 2021 explained why enterprises are not just talking about event-driven real-time applications, but finally building them. Here are some arguments:
- REST limitations can limit your business strategy
- Data needs to be fluid and real-time
- Microservices and serverless need event-driven architectures
Real-time Data in Motion beats Slow Data
Use cases for event-driven architectures exist across industries. Some examples:
- Transportation: Real-time sensor diagnostics, driver-rider match, ETA updates
- Banking: Fraud detection, trading, risk systems, mobile applications/customer experience
- Retail: Real-time inventory, real-time POS reporting, personalization
- Entertainment: Real-time recommendations, a personalized news feed, in-app purchases
- The list goes on across verticals…
Real-time data in motion beats data at rest in databases or data lakes in most scenarios. There are a few exceptions that require batch processing:
- Reporting (traditional business intelligence)
- Batch analytics (processing high volumes of data in a bundle, for instance, Hadoop and Spark’s map-reduce, shuffling, and other data processing only make sense in batch mode)
- Model training as part of a machine learning infrastructure (while model scoring and monitoring often requires real-time predictions, the model training is batch in almost all currently available ML algorithms)
Beyond these exceptions, almost everything is better in real-time than batch.
Be aware that real-time data processing is more than just sending data from A to B in real-time (aka messaging or pub/sub). Real-time data processing requires integration and processing capabilities. If you send data into a database or data lake in real-time but have to wait until it is processed there in batch, it does not solve the problem.
With the ideas around real-time in mind, let’s explore what a de facto standard API is.
What is a (De Facto) Standard API?
The answer is longer than you might expect and needs to be separated into three sections:
- API
- Standard API
- De facto standard API
What is an API?
An application programming interface (API) is an interface that defines interactions between multiple software applications or mixed hardware-software intermediaries. It defines the kinds of calls or requests that can be made, how to make them, the data formats that should be used, the conventions to follow, etc. It can also provide extension mechanisms so that users can extend existing functionality in various ways and to varying degrees.
An API can be entirely custom, specific to a component, or designed based on an industry-standard to ensure interoperability. Through information hiding, APIs enable modular programming, allowing users to use the interface independently of the implementation.
What is a Standard API?
Industry consortiums or other industry-neutral (often global) groups or organizations specify standard APIs. A few characteristics show the trade-offs:
- Vendor-agnostic interfaces
- Slow evolution and long specification process
- Most vendors add proprietary features because a) too slow process of the standard specification or more often b) to differentiate their commercial offering
- Acceptance and success depend on the complexity and added value (this sounds obvious but is often the key blocker for success)
Examples for Standard APIs
Here are some examples of standard APIs. I also add my thoughts if I think they are successful or not (but I fully understand that there are good arguments against my opinion).
Generic Standards
- SQL: Domain-specific language used in programming and designed for managing data held in a relational database management system. Successful as almost every database somehow supports SQL or tries to build a similar syntax. A good example is ksqlDB, the Kafka-native streaming SQL engine. ksqlDB (like most other streaming SQL engines) is not ANSI SQL, but still understood easily by people that know SQL.
- J2EE / Java EE / Jakarta EE: Successful as most vendors adopted at least parts of it for Java frameworks. While early versions were very heavyweight and complex, the current APIs and implementations are much more lightweight and user-friendly. JMS is a great example where vendors added proprietary add-ons to add features and differentiate. No vendor-lockin is only true in theory!
- HTTP: Successful as application layer protocol for distributed, collaborative, hypermedia information systems. While not 100% correct, people typically interpret HTTP as REST Web Services. HTTP is often misused for things it is not built for.
- SOAP / WSDL: Partly successful in providing XML-based web service standard specifications. Some vendors built good tooling around it. However, this is typically only true for the basic standards such as SOAP and WSDL, not so much for all the other complex add-ons (often called WS-* hell).
Standards for a Specific Problem or Industry
- OPC-UA for Industrial IoT (IIoT): Partly successful machine-to-machine communication protocol for industrial automation developed. Adopted by almost every vendor in the industrial space. The drawback (similarly to HTTP) is that it is often misused. For instance, MQTT is a much better and more lightweight choice in some scenarios. OPC-UA is a great example where the core is successful, but the industry-specific add-ons are not prevalent and not supported by tools. Also, OPC-UA is too heavyweight for many of the use cases it is used in.
- PMML for Machine Learning: Not successful as an XML-based predictive model interchange format. The idea is great: Train an analytic model once and then deploy it across platforms and programming languages. In practice, it did not work. Too many limitations and unnecessary complexity for a project. Most real-world machine learning deployments I have seen in the wild avoid it and deploy models to production with a standard wrapper. ONNX and other successors are not more prevalent yet either.
In summary, some standard APIs are successful and adopted well; many others are not. Contrary to these standards specified by consortiums, there is another category emerging: De Facto Standard APIs.
What is a De Facto Standard API?
De Facto standard APIs originate from an existing successful solution (that can be an open-source framework, a commercial product, or a cloud service). Two ways exist how these de facto standard APIs emerge:
- Driven by a single vendor (often proprietary), for example: Amazon S3 for object storage.
- Driven by a huge community around a successful open-source project, for example: Apache Kafka for event streaming.
No matter how a de facto standard API originated, they typically have a few characteristics in common:
- Creation of a new category of software, something that did not exist before
- Adoption by other frameworks, products, or cloud services as the API because became the de facto standard
- No complex, formal, long-running standard processes; hence innovation is possible in a relatively flexible and agile way
- Practical processes and rules are in place to ensure good quality and consensus (either controlled by the owner company for a proprietary standard API or across the open source community)
Let’s now explore two de facto standard APIs: Amazon S3 and Apache Kafka. Both are very successful but very different regarding being a standard. Hence, the trade-offs are very different.
Amazon S3: De Facto Standard API for Object Storage
Amazon S3 or Amazon Simple Storage Service is a service offered by Amazon Web Services (AWS) that provides object storage through a web service interface in the public AWS cloud. It uses the same scalable storage infrastructure that Amazon.com uses to run its global e-commerce network. Amazon S3 can be employed to store any type of object, which allows for uses like storage for internet applications, backup and recovery, disaster recovery, data archives, data lakes for analytics, and hybrid cloud storage. Additionally, S3 on Outposts provides on-premises object storage for on-premises applications that require high-throughput local processing.
“Amazon CTO on Past, Present, Future of S3” is a great read about the evolution of this fully-managed cloud service. While the public API was kept stable, the internal backend architecture under the hood changed several times significantly. Plus, new features were developed on top of the API, for instance, AWS Athena for analytics and interactive queries using standard SQL. I really like how Werner Vogels describes his understanding of a good cloud service:
Vogels doesn’t want S3 users to even think for a moment about spindles or magnetic hardware. He doesn’t want them to care about understanding what’s happening in those data centers at all. It’s all about the services, the interfaces, and the flexibility of access, preferably with the strongest consistency and lowest latency when it really matters.
So, we are talking about a very successful proprietary cloud service by AWS. Hence, what’s the point?
Most Object Storage Vendors Support the Amazon S3 API
Many enterprises use the Amazon S3 API. Hence, it became the de facto standard. If other storage vendors want to sell object storage, supporting the S3 interface is often crucial to get through the evaluations and RFPs. If you don’t support the S3 API, it is much harder for companies to adopt the storage and implement the integration (as most companies already use Amazon S3 and have built tools, scripts, testing around this API).
For this reason, many applications have been built to support the Amazon S3 API natively. This includes applications that write data to Amazon S3 and Amazon S3-compatible object stores.
S3 compatible solutions include client backup, file browser, server backup, cloud storage, cloud storage gateway, sync&share, hybrid storage, on-premises storage, and more.
Many vendors sell S3-compatible products: Oracle, EMC, Microsoft, NetApp, Western Digital, MinIO, Pure Storage, and many more. Check out the Amazon S3 site from Wikipedia for a more detailed and complete list.
So why has the S3 API become so ubiquitous?
The creation of a new software category is a dream for every vendor! Let’s understand how and why Amazon was successful in establishing S3 for object storage. The following is a quote from Chris Evan’s great article from 2016: “Has S3 become the de facto API standard?”
So why has the S3 API become so ubiquitous? I suspect there are a number of reasons. These include:
- First to market – When S3 was launched in 2006, most enterprises were familiar with object storage as “content addressable storage” through EMC’s Centera platform. Other than that, applications were niche and not widely adopted except for specific industries like High Performance Computing where those users were used to coding to and for the hardware. S3 quickly became a platform everyone could use with very little investment. That made it easy to consume and experiment with. By comparison, even today the leaders in object storage (as ranked by the major analysts) still don’t make it easy (or possible) to download and evaluate their products, even though most are software only implementations.
- Documentation – following on from the previous point, S3 has always been well documented, with examples on how to run API commands. There’s a document history listing changes over the past 6-7 years that shows exactly how the API has evolved.
- A Single Agenda – the S3 API was designed to fit a single agenda – that of storing and retrieving objects from S3. As such, Amazon didn’t have to design by committee and could implement the features they required and evolve from there. Contrast that with the CDMI (Cloud Data Management Interface) from SNIA. The SNIA website is difficult to navigate, the standard itself is only on the 4th published iteration in six years, while the documentation runs to 264 pages! (Note that the S3 API runs into more pages, but is infinitely more consumable, with simple examples from page 11 onwards).
Cons of a Proprietary De Facto Standard like Amazon S3
Many people might say: “Better a proprietary standard than no standard.” I partly agree with this. The possibility to learn one API and use it across multi-cloud and on-premise systems and vendors is great. However, Amazon S3 has several disadvantages as it is NOT an open standard:
- Other vendors (have to) build their implementation on a best guess about the behavior of the API. There is no official standard specification they can rely on.
- Customers cannot be sure what they buy. At least, they should not expect the same behavior of 3rd party S3 implementations that they get from their experiences using Amazon S3 on AWS.
- Amazon can change APIs and features as it likes. Other vendors need to “reverse engineer the API” and adjust their products.
- Amazon could sue competitors for using S3 API branding – even though this is not likely to happen as the benefits are probably bigger (I am not a lawyer; hence this statement might be wrong and is just my personal opinion)
Let’s now look at an open-source de facto standard: Kafka.
Kafka API: De Facto Standard API for Event Streaming
Apache Kafka is mainstream today! The Kafka API became the de facto standard for event-driven architectures and event streaming. Two proof points:
- Use cases across all industries and infrastructure. Including various kinds of transactional and analytics workloads. Edge, hybrid, multi-cloud. I collected a few examples across verticals that use Apache Kafka to show the prevalence across markets.
- Adoption by various open-source frameworks and many software/cloud vendors. Check out my blog post if you are interested in a comparison of Kafka vendors such as Confluent, Cloudera, Red Hat or Amazon MSK and related technologies like Azure Event Hubs, AWS Kinesis, RedPanda, or Apache Pulsar.
The Kafka API (aka Kafka Protocol)
Kafka became the de facto event streaming API. Similar like the S3 API became the de facto standard for object storage. Actually, the situation is even better for the Kafka API as the S3 API is a proprietary protocol from AWS. In contrast, the Kafka API and protocol are open source under Apache 2.0 license.
The Kafka protocol covers the wire protocol implemented in Kafka. It defines the available requests, their binary format, and the proper way to make use of them to implement a client.
One of my favorite characteristics of the Kafka protocol is backward compatibility. Kafka has a “bidirectional” client compatibility policy. In other words, new clients can talk to old servers, and old clients can talk to new servers. This allows users to upgrade either clients or servers without experiencing any downtime or data loss. This makes Kafka ideal for microservice architectures and domain-driven design (DDD). Kafka really decouples the applications from each other in contrary to web service/REST-based architectures).
Pros of an Open Source De Facto Standard like the Kafka API
The huge benefit of an open-source de facto standard API is that it is open and usually follows a collaborative standardized process to make changes to the API. This brings various benefits to the community and software vendors.
The following facts about the Kafka API make many developers and enterprises happy:
- Changes occur in a visible process enforced by a committee. For Apache Kafka, the Apache Software Foundation (ASF) is the relevant organization. Apache projects are managed using a collaborative, consensus-based process with members from various countries and enterprises. Check out how it works if you don’t know it yet.
- Frameworks and vendors can implement against the open protocol and validate the implementation. That is significantly different from proprietary de facto standards like Amazon S3. Having said this, not every product that says it uses the Kafka API is 100% compatible and consequently is limited in the feature set and provides different behavior.
- Developers can test the underlying behavior against the same API. Hence, unit and performance tests for different implementations can use the same code.
- The Apache 2.0 license makes sure that the user does not have to worry about infringing any patents by using the software.
Frameworks, Products, and Cloud Services using the Kafka API
Many frameworks and vendors adopted the Kafka API. Let’s take a look at a few very different alternatives available today that use the Kafka API:
- Open-source Apache Kafka from the Apache website
- Self-managed Kafka-based vendor solutions for on-premises or cloud deployments from Confluent, Cloudera, Red Hat
- Partially managed Kafka-based cloud offerings from Amazon MSK, Red Hat, Azure HD Insight’s Kafka, Aiven, cloudkarafka, Instaclustr.
- Fully managed Kafka cloud offerings such as Confluent Cloud – actually, there is no other serverless, fully compatible Kafka SaaS offering on the market today (even though many marketing departments try to sell it like this)
- Partly protocol-compatible, self-managed solutions such Apache Pulsar (with a simple, very limited Kafka wrapper class) or RedPanda for embedded / WebAssembly (WASM) use cases
- Partly protocol-compatible, fully managed offerings like Azure EventHubs
Just be aware that the devil is in the details. Many offerings only implement a fraction of the Kafka API. Additionally, many offerings only support the core messaging concept, but exclude key features such as Kafka Connect for data integration, Kafka Streams for stream processing, or exactly-once semantics (EOS) for building transactional systems.
The Kafka API Dominates the Event Streaming Landscape
If you look at the current event streaming landscape, you see that more and more frameworks and products adopt the Kafka API. Even though the following is not a complete list (and other non-Kafka offerings exist), it is imposing:
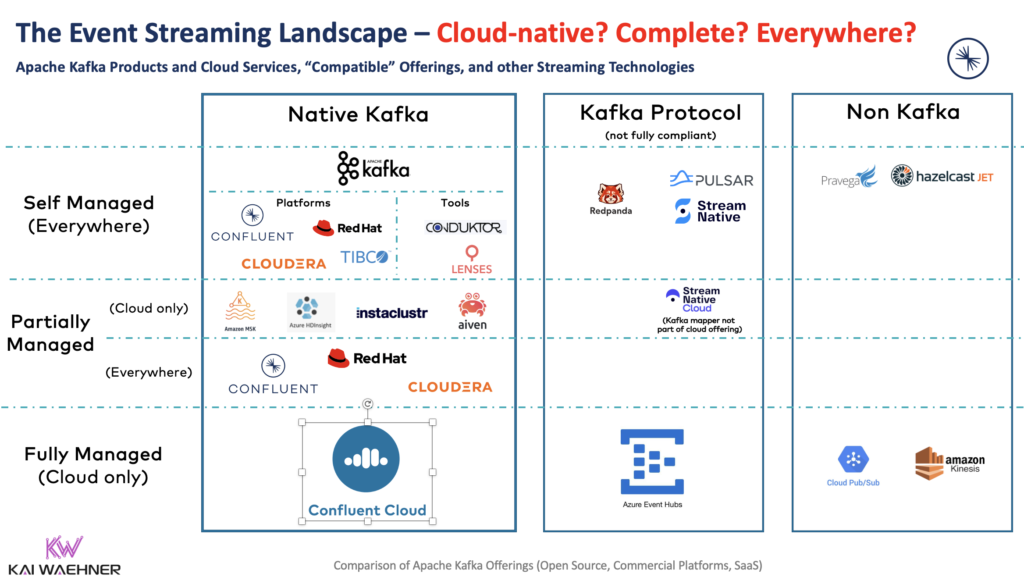
If you want to learn more about the different Kafka offerings on the market, check out my Kafka vendor comparison. It is crucial to understand what Kafka offering is right for you. Do you want to focus on business logic and consume the Kafka infrastructure as a service? Or do you want to implement security, integration, monitoring, etc., by yourself?
The Kafka API is here to stay…
The Kafka API became the de facto standard API for event streaming. The usage of an open protocol creates huge benefits for corresponding frameworks, products, and cloud services leveraging the Kafka API.
Vendors can implement against the open standard and validate their implementation. End users can choose the best solution for their business problem. Migration between different Kafka services is also possible relatively easily – as long as each vendor is compliant with the Kafka protocol and implements it completely and correctly.
Are you using the Kafka API today? Open source Kafka (“car engine”), a commercial self-managed offering (“complete car”), or the serverless Confluent Cloud (“self-driving car) to focus on business problems? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.