BYOC (Bring Your Own Cloud) is an emerging deployment model for organizations looking to maintain greater control over their cloud environments. Unlike traditional SaaS models, BYOC allows businesses to host applications within their own VPCs to provide enhanced data privacy, security, and compliance. This approach leverages existing cloud infrastructure. It offers more flexibility for custom configurations, particularly for companies with stringent security needs. In the data streaming sector around Apache Kafka, BYOC is changing how platforms are deployed. Organizations get more control and adaptability for various use cases. But it is clearly NOT the right choice for everyone!
BYOC (Bring Your Own Cloud) – A New Deployment Model for Cloud Infrastructure
BYOC (Bring Your Own Cloud) is a deployment model where organizations choose their preferred cloud infrastructure to host applications or services, rather than using a serverless / fully managed cloud solution selected by a software vendor; typically known as Software as a Service (SaaS). This model gives businesses flexibility to leverage their existing cloud services (like AWS, Google Cloud, Microsoft Azure, or Alibaba) while integrating third-party applications that are compatible with multiple cloud environments.
BYOC helps companies maintain control over their cloud infrastructure, optimize costs, ensure compliance with security standards. BYOC is typically implemented within an organization’s own cloud VPC. Unlike SaaS models, BYOC offers enhanced privacy and compliance by maintaining control over network architecture and data management.
However, BYOC also has some serious drawbacks! The main challenge is scaling a fleet of co-managed clusters running in customer environments with all the reliability expectations of a cloud service. Confluent has shied away from offering a BYOC deployment model for Apache Kafka based on Confluent Platform because doing BYOC at scale requires a different architecture. WarpStream has built this architecture, with a BYOC-native platform that was designed from the ground up to avoid the pitfalls of traditional BYOC.
The Data Streaming Landscape
Data Streaming is a separate software category of data platforms. Many software vendors built their entire businesses around this category. The data streaming landscape shows that most vendors use Kafka or implement its protocol because Apache Kafka has become the de facto standard for data streaming.
New software companies have emerged in this category in the last few years. And several mature players in the data market added support for data streaming in their platforms or cloud service ecosystem. Most software vendors use Kafka for their data streaming platforms. However, there is more than Kafka. Some vendors only use the Kafka protocol (Azure Event Hubs) or utterly different APIs (like Amazon Kinesis).
The following Data Streaming Landscape 2024 summarizes the current status of relevant products and cloud services.

The Data Streaming Landscape evolves. Last year, I added WarpStream as a new entrant into the market. WarpStream uses the Kafka protocol and provides a BYOC offering for Kafka in the cloud. In my next update of the data streaming landscape, I need to do yet another update: WarpStream is now part of Confluent. There are also many other new entrants. Stay tuned for a new “Data Streaming Landscape 2025” in a few weeks (subscribe to my newsletter to stay up-to-date with all the things data streaming).
Confluent Acquisition of WarpStream
Confluent had two product offerings:
- Confluent Platform: A self-managed data streaming platform powered by Kafka, Flink, and much more that you can deploy everywhere (on-premise data center, public cloud VPC, edge like factory or retail store, and even stretched across multiple regions or clouds).
- Confluent Cloud: A fully managed data streaming platform powered by Kafka, Flink, and much more that you can leverage as a serverless offering in all major public cloud providers (Amazon AWS, Microsoft Azure, Google Cloud Platform).
Why did Confluent acquire WarpStream? Because many customers requested a third deployment option: BYOC for Apache Kafka.
As Jay Kreps described in the acquisition announcement: “Why add another flavor of streaming? After all, we’ve long offered two major form factors–Confluent Cloud, a fully managed serverless offering, and Confluent Platform, a self-managed software offering–why complicate things? Well, our goal is to make data streaming the central nervous system of every company, and to do that we need to make it something that is a great fit for a vast array of use cases and companies.”
Read more details about the acquisition of WarpStream by Confluent in Jay’s blog post: Confluent + WarpStream = Large-Scale Streaming in your Cloud. In summary, WarpStream is not dead. The WarpStream team clarified the status quo and roadmap of this BYOC product for Kafka in its blog post: “WarpStream is Dead, Long Live WarpStream“.
Let’s dig deeper into the three deployment options and their trade-offs.
Deployment Options for Apache Kafka
Apache Kafka can be deployed in three primary ways: self-managed, fully managed/serverless, and BYOC (Bring Your Own Cloud).
- In self-managed deployments, organizations handle the entire infrastructure, including setup, maintenance, and scaling. This provides full control but requires significant operational effort.
- Fully managed or serverless Kafka is offered by providers like Confluent Cloud or Azure Event Hubs. The service is hosted and managed by a third-party, reducing operational overhead but with limited control over the underlying infrastructure.
- BYOC deployments allow organizations to host Kafka within their own cloud VPC. BYOC combines some of the benefits of cloud flexibility with enhanced security and control, while it outsources most of Kafka’s management to specialized vendors.
Confluent’s Kafka Products: Self-Managed Platform vs. BYOC vs. Serverless Cloud
Using the example of Confluent’s product offerings, we can see why there are three product categories for data streaming around Apache Kafka.
There is no silver bullet. Each deployment option for Apache Kafka has its pros and cons. The key differences are related to the trade-offs between “ease of management” and “level of control”.
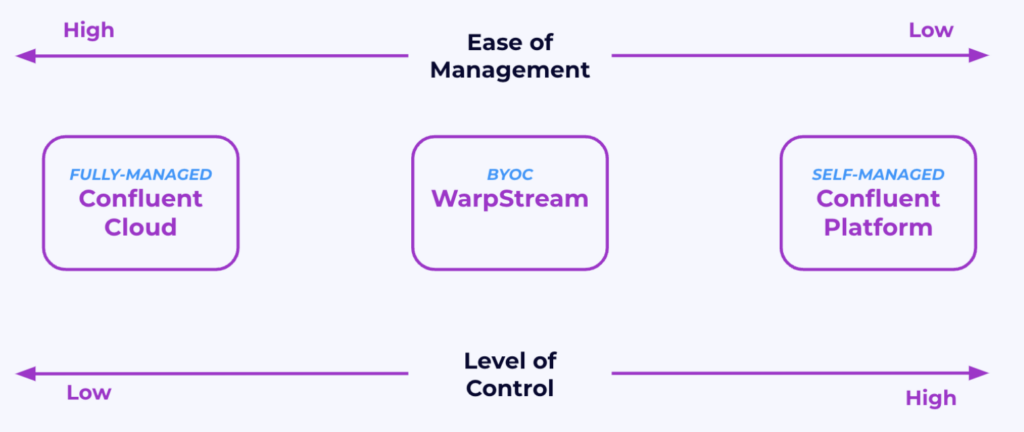
If we go into more detail, we see that different use cases require different configurations, security setups, and levels of control while also focusing on being cost effective and providing the right SLA and latency for each use case.
Trade-Offs of Confluent’s Deployment Options for Apache Kafka
On a high level, you need to figure out if you want or have to managed the data plane(s) and control plane of your data streaming infrastructure:
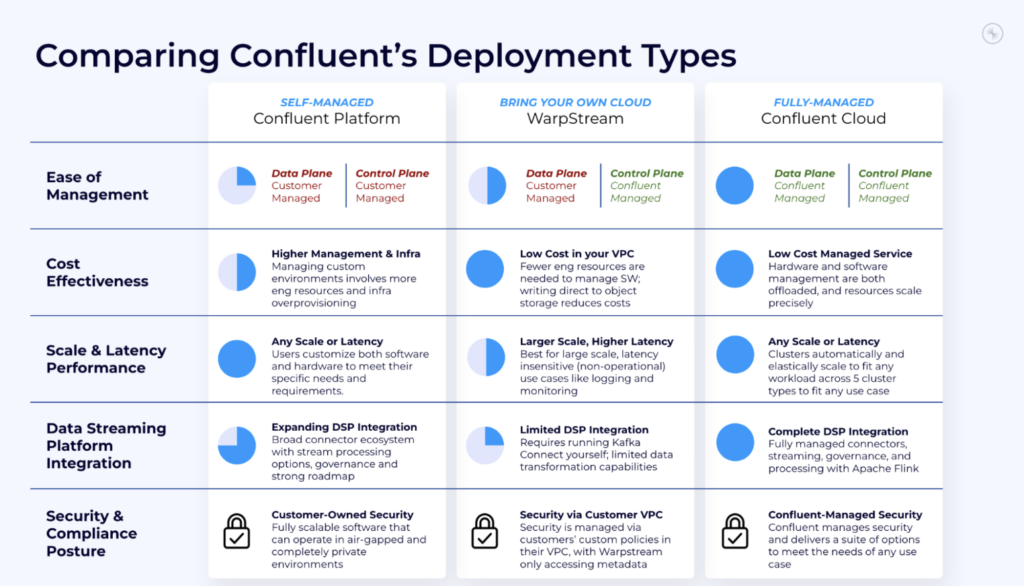
If you follow my blog, you know that a key focus is exploring various use cases, architectures and success stories across all industries. And use cases such as log aggregation or IoT sensor analytics required very different deployment characteristics than an instant payment platform or fraud detection and prevention.
Choose the right Kafka deployment model for your use case. Even within one organization, you will probably need different deployments because of security, data privacy and compliance requirements, but also staying cost efficient for high-volume workloads.
BYOC for Apache Kafka with WarpStream
Self-managed Kafka and fully managed Kafka are pretty well understood in the meantime. However, why is BYOC needed as a third option and how to do it right?
I had plenty of customer conversations across industries. Common feedback is that most organizations have a cloud-first strategy, but many also (have to) stay hybrid for security, latency or cost reasons.
And let’s be clear: If a data streaming project goes to the cloud, fully managed Kafka (and Flink) should always be the first option as it is much easier to manage and operate to focus on fast time to market and business innovation. Having said that, sometimes, security, cost or other reasons require BYOC.
How Is BYOC Implemented in WarpStream?
Let’s explore why WarpStream is an excellent option for Kafka as BYOC deployment and when to use it instead of serverless Kafka in the cloud:
- WarpStream provides BYOC, meaning single-tenant service so that a customer has its own “instance” of Kafka (to use the protocol, it is not Apache Kafka under the hood).
- However, under the hood, the system still uses cloud-native serverless systems like Amazon S3 for scalability, cost-efficiency and high availability (but the customer does not see this complexity and does not have to care about it).
- As a result, the data plane is still customer managed (that’s what they need for security or other reasons), but in contrary to self-managed Kafka, the customer does not need to worry about the complexity under the hood (like rebalancing, rolling upgrades, backups) – that is what S3 and other magic code of the WarpStream service takes over.
- The magic is the stateless agents in the customer VPC. It makes this solution scalable and still easy to operate (compared to the self-managed deployment option) while the customer has its own instance.
- Many use cases are around lift and shift of existing Kafka deployments (like self-managed Apache Kafka or another vendor like Kafka as part of Cloudera or Red Hat). Some companies want to “lift and shift” and keep the feeling of control they are used to, while still offloading most of the management to the vendor.
I wrote this summary after reading the excellent article of my colleague Jack Vanlightly: BYOC, Not “The Future Of Cloud Services” But A Pillar Of An Everywhere Platform. This article goes into much more technical detail and is a highly recommended read for any architect and developer.
Benefits of WarpStream’s BYOC Implementation for Kafka
Most vendors have dubios BYOC implementations.
For instance, if the vendor needs to access the VPC of the customercheaper than AK self managed because cloud native (zero disks, zero interzone networking fees) and headaches for responsibilities in the case of failures.
WarpStream’s BYOC-native implementation differs from other vendors and provides various benefits because of its novel architecture:
- WarpStream does not need access to the customer VPC. The data plane (i.e., the brokers in the customer VPC) are stateless. The metadata/consensus is in the control plane (i.e., the cloud service in the WarpStream VPC).
- The architecture solves sovereignty challenges and is a great fit for security and compliance requirements.
- The cost of WarpStream’s BYOC offering is cheaper than self-managed Apache Kafka because it is built with cloud-native concepts and technologies in mind (e.g., zero disks and zero interzone networking fees, leveraging cloud object storage such as Amazon S3).
- The stateless architecture in the customer VPC makes autoscaling and elasticity very easy to implement/configure.
The Main Drawbacks of BYOC for Apache Kafka
BYOC is an excellent choice if you have specific security, compliance or cost requirements that need this deployment option. However, there are some drawbacks:
- The latency is worse than self-managed Kafka or serverless Kafka as WarpStream directly touches the Amazon S3 object storage (in contrast to “normal Kafka”).
- Kafka using BYOC is NOT fully managed, like e.g. Confluent Cloud, so you have more efforts to operate it. Also, keep in mind that most Kafka cloud services are NOT serverless but just provision Kafka for you and you still need to operate it.
- Additional components of the data streaming platform (such as Kafka Connect connectors and stream processors such as Kafka Streams or Apache Flink) are not part of the BYOC offering (yet). This adds some complexity to operations and development.
Therefore, once again, I recommend to only look at BYOC options for Apache Kafka in the public cloud if a fully managed and serverless data streaming platform does NOT work for you because of cost, security or compliance reasons!
BYOC Complements Self-Managed and Serverless Apache Kafka – But BYOC Should NOT be the First Choice!
BYOC (Bring Your Own Cloud) offers a flexible and powerful deployment model, particularly beneficial for businesses with specific security or compliance needs. By allowing organizations to manage applications within their own cloud VPCs, BYOC combines the advantages of cloud infrastructure control with the flexibility of third-party service integration.
But once again: If a data streaming project goes to the cloud, fully managed Kafka (and Flink) should always be the first option as it is much easier to manage and operate to focus on fast time to market and business innovation. Choose BYOC only if fully managed does not work for you, e.g. because of security requirements.
In the data streaming domain around Apache Kafka, the BYOC model complements existing self-managed and fully managed options. It offers a middle ground that balances ease of operation with enhanced privacy and security. Ultimately, BYOC helps companies tailor their cloud environments to meet diverse and developing business requirements.
What is your deployment option for Apache Kafka? A self-managed deployment in the data center or at the edge? Serverless Cloud with a service such as Confluent Cloud? Or did you (have to) choose BYOC? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





