
Apache Kafka became the de facto standard for event streaming. The open-source community is huge. Various vendors added Kafka and related tooling to their offerings or provide a Kafka cloud service. This blog post uses the car analogy – from the motor engine to the self-driving car – to explore the different Kafka offerings available on the market. I also cover a few other vehicles, meaning (partly) Kafka-compatible technologies. The goal is not a feature-by-feature comparison (that would be outdated the day after the publication). Instead, the intention is to educate about the different deployment models, product strategies, and trade-offs from the available options.
Disclaimer: I work for Confluent. However, the post is not about comparing features but explaining the concepts behind the alternatives. I talk to enterprises across the globe every week. I can assure you that many people I talk to are not aware or mislead about what you read in the following sections. Hence, I hope that the following helps you to make the right decision. Either choose to run open-source Apache Kafka or one of the various commercial Kafka offerings, or even a combination of both.
UPDATE (August 2022): This blog post was written before Amazon MSK Serverless was released. The below is still accurate and worth a read for comparing Kafka products and cloud services. Additionally, please check out the article “When NOT to choose Amazon MSK Serverless for Apache Kafka?“
Apache Kafka Components and Use Cases
The goal is not to introduce Kafka here. The minimum you should know is that Kafka is NOT just a messaging layer for data ingestion into a data lake. This is just a fraction of today’s usages.
Kafka is an open-source framework under Apache 2.0 license. It provides a combination of messaging, storage, processing, and integration of high volumes of data at scale in real-time and fault-tolerant. That’s what makes Kafka unique compared to other MQ, ETL, ESB, and API platforms.
Kafka is deployed in production for various use cases across industries. This includes analytical and mission-critical workloads. Different deployments require different SLAs. You should always ask yourself what happens if the Kafka infrastructure is in trouble. What are your RTO (Recovery Time Objective) and RPO (Recovery Point Objective)? Or in other words: How much data is okay to lose? How much downtime is acceptable? Start your Kafka projects with these questions in mind when you start your comparison of the options!
Kafka is the De Facto Standard API for Event Streaming like S3 API for Object Storage
Apache Kafka is mainstream! The latest proof: Check out the new ThoughtWorks Technology Radar: “Kafka API without Kafka“:

Kafka became the de facto event streaming API. Similar to S3 API became the de facto standard for object storage. Actually, the situation is even better for the Kafka API as the S3 API is a proprietary protocol from AWS. In contrast, the Kafka API and protocol are open source under Apache 2.0 license.

Check out the blog “Kafka API is the De Facto Standard API for Event Streaming like Amazon S3 for Object Storage” for more details.
Let’s take a look at a few very different Kafka alternatives available today:
- Open-source Apache Kafka from the Apache website under Apache 2.0 license
- Self-managed vendor offerings from Confluent, Cloudera, Red Hat, Amazon MSK, and many more
- Fully-managed cloud offerings such as Confluent Cloud
- Partly protocol-compatible products such as RedPanda for embedded / WebAssembly (WASM) use cases
- Partly protocol-compatible SaaS offerings like Azure EventHubs
That’s a lot of options. So, how do you make a Kafka comparison to choose the right one? Before we go into more detail, let’s explore how complex Kafka actually is and when you do have to care about this at all.
Should you care how complex or heavyweight your event streaming technology is?
Complexity matters (only) if you need to operate the infrastructure by yourself. The beauty of SaaS is that you just consume the service and focus on your business problems. For instance, the AWS S3 object storage is a simple API with a fully managed service under the hood. You do not need to worry about operations or monitoring. You just use the cloud service.
Having said this, it is a little bit strange that ThoughtWorks mentions the barriers and complexity of Kafka but then refers to the Pulsar wrapper. That is an (immature) single class mapping implementation that only maps a small part of Kafka’s protocol (here is the producer wrapper as an example). Developers can use that wrapper to move data between Kafka clients and Pulsar brokers. However, Pulsar has a much more complex three-tier distributed architecture with ZooKeeper, BookKeeper, and Pulsar clusters. What is the benefit here? Is this really what you want to do in mission-critical workloads? Why? Please let me know if you seriously consider using such a wrapper architecture. Also, please read my post about the “Myths of Kafka vs. Pulsar“. A lot of arguments like the Kafka wrapper are simply just marketing and not usable for real-world projects!
Therefore, when I think about using the Kafka API without operating Kafka, then I have fully managed SaaS offerings such as Confluent Cloud or Azure Event Hubs in my mind.
Having said this, a fully managed cloud service is not always an option. For instance, Kafka at the edge is the new black. Plenty of use cases exist for a single broker or highly-available Kafka clusters at the edge.
But even if you want or need to operate Kafka by yourself: With KIP-500 and the removal of ZooKeeper, it gets easier and more lightweight than ever before. A lot of arguments do not exist anymore to move to a more “lightweight alternative”. There might be good reasons to choose something like RedPanda. But the main argument of having a more simple and lightweight deployment is not given anymore. Check out this video showing Kafka without ZooKeeper.
How to Choose the Right Kafka Distribution or Cloud Service?
So, how to make a comparison to find out which Kafka distribution or cloud service is the right one for your project?
The answer is simpler than you might think: The ultimate goal is to focus and solve your business problem.
How do you do that? By implementing business logic. Ideally, you don’t have to worry about infrastructure, operations, security, scalability, reliability, and non-business characteristics. Hence, SaaS with fully managed Kafka should be the first choice.
Unfortunately, SaaS is not always possible or the best option for many reasons:
- Missing features
- Technical limitations
- Cost
- Security requirements
- On-premise or edge use cases
Therefore, we need to go one step back and understand what options you have to deploy and operate Kafka. Understanding these concepts without all the marketing fluff from the vendors is crucial to make the right decision!
The Kafka Car: An Analogy for a Product Comparison
It is often easier to compare technology by using an analogy from real life. Something everybody understands. No matter what industry you are in. No matter how technical you are. First, I thought I use the analogy of pizza, including self-made pizza, pizza ingredients, restaurants, delivery services, and other related topics. But pizza is used so often in the IT world. This originated in the early days of Amazon. Jeff Bezos instituted a rule: Every internal team should be small enough to be fed with two pizzas.
Finally, I choose to use the analogy of a car because I think many of the arguments are less debatable this way. I guess we could never agree on what would be the best pizza option for most people… 🙂
Hence, let’s talk about car engines, car brands, self-driving, connected fleets, and vintage vehicles in the following sections.

Give me a self-driving car, please!
Obviously, most people would prefer a self-driving car (if the price is right). It is safe, cost-efficient, and comfortable.
In the Kafka context, this means that the Kafka infrastructure would be
- cloud-native (= elastic, scalable and automated, ideally fully managed)
- complete (= entire set of security and operational features that enterprises require)
- everywhere (= available in multiple public clouds, private cloud, on-premise, edge outside the data center)
Unfortunately, not every Kafka setup can be self-driving. We need to disassemble a car into its parts to understand what’s going on under the hood. Then we can choose the right car for our business problem.
Car Brands: Comparison of Confluent, Cloudera, Red Hat, Amazon MSK
Competition creates innovation. Hence, it is great to see many car brands and car models on the streets. Similarly, many competing companies fight for market share around Kafka business. Let’s quickly think about the available car brands (= Kafka vendors) on the market.

I only focus on the most relevant ones that either care about the Kafka project and community, have a lot of market power, or ideally both.
The car brands are Confluent, Cloudera, Red Hat, and Amazon MSK. I have a section on other Kafka and non-Kafka streaming vendors at the end of the blog post to provide a more detailed comparison.
Again, the idea is NOT to have a feature-by-feature comparison or flame war. The following are a few facts about each vendor. I only focus on Kafka-related points. Hence, it is no surprise that Confluent looks best in the following list as they only focus on event streaming. But obviously, each vendor has strengths and weaknesses. For instance, if you want to discuss the overall cloud infrastructure capabilities and strategy, well, then AWS would look much stronger than all the other Kafka vendors… 🙂
Confluent – The Leading Apache Kafka Vendor
A few facts about Confluent:
- Focus on event streaming
- Original creators of Kafka
- The main contributor to the Apache Kafka project with 80% of Kafka commits
- Always the latest Kafka version (without limitations) and full support
- Rich Kafka ecosystem (connectors, governance, security, etc.)
- Hybrid architectures (including the only true fully-managed and complete Kafka service)
- Partnership and 1st party integration into cloud providers (AWS, GCP, Azure) – e.g., you can use your cloud provider credits and account to consume Confluent Cloud
- Certified for self-managed operations on cloud providers’ edge offerings (e.g., AWS Outpost including Wavelength, Google’s Anthos)
Cloudera – Big Data Analytics Suite
A few facts about Cloudera:
- Focus on big data analytics
- Provides a platform around tens of different big data frameworks for storage, batch, and real-time analytics
- Kafka is part of the platform (Hadoop, Spark, Flume, Flink, many more) with tooling and support for the whole platform
- Hybrid architectures (but no fully-managed Kafka service)
- Partnership and 3rd party integration into cloud providers (AWS, GCP, Azure)
Red Hat (IBM) – Cloud-native PaaS Infrastructure
A few facts about Red Hat (IBM):
- Focus on infrastructure (mainly around Linux and Kubernetes)
- Kafka is available as part of the Red Hat AMQ product portfolio, combined with other open-source frameworks like ActiveMQ or Camel
- OpenShift Streams for Apache Kafka provides integration with Kubernetes
- Focus on open source frameworks; working actively with the community (for Kafka, Red Hat, e.g., contributes to Debezium for CDC and the Strimzi Kubernetes Operator)
- Hybrid Architectures (but no fully-managed Kafka service)
- Partnership and 3rd party integration into cloud providers (AWS, GCP, Azure)
Interesting side notes for the relationship between Confluent, Red Hat, and IBM:
- IBM acquired Red Hat in 2019.
- Confluent and IBM announced a strategic partnership in 2020
- IBM deprecated its own Kafka offering (IBM Streams) in March 2021.
- Confluent is the way to go with IBM as part of the IBM Cloud Pak for Integration. Even IBM’s salespeople sell Confluent.
Amazon Web Services (AWS) – The Leading Cloud Provider
- MSK misses several key Kafka features, including Kafka Connect or Kafka Streams
- Cloud-only (but only self-managed, not fully managed)
- MSK is not cloud-native (like S3 or Kinesis) but just provisioned infrastructure
- Obviously only available on AWS
- For on-premise deployments (like AWS Outpost or AWS Wavelength), the recommended Kafka product is the certified Confluent Platform
Interesting side note about the commercial support and SLAs of AWS’s Kafka offering: Kafka is excluded from MSK support! Quote from the MSK SLAs: “The Service Commitment DOES NOT APPLY to any unavailability, suspension, or termination… caused by the underlying Apache Kafka or Apache ZooKeeper engine software that leads to request failures…”
Event Streaming Technology and Cloud-native Infrastructure are Complementary!
The above showed a few facts for the main Kafka vendors: Confluent, Cloudera, Red Hat, AWS. However, it is worth explicitly pointing out that these vendors are often complementary. For instance, most Confluent Platform deployments I see on Kubernetes on-premise are actually on Red Hat OpenShift. And with AWS’s huge market share, most self-managed Confluent deployments in the cloud are on AWS.
Also, Confluent Platform is certified on AWS Outpost and Google Anthos. Hence, you can even combine cloud-native technologies at the edge. A great example is smart factory 5G use cases leveraging Confluent Platform on AWS Wavelength. Consequently, a Kafka comparison does typically not eliminate all the other Kafka vendors from the project.
The following architecture depicts the combination of Confluent Cloud in AWS plus Confluent Platform on AWS Wavelength leveraging 5G Carrier networks:
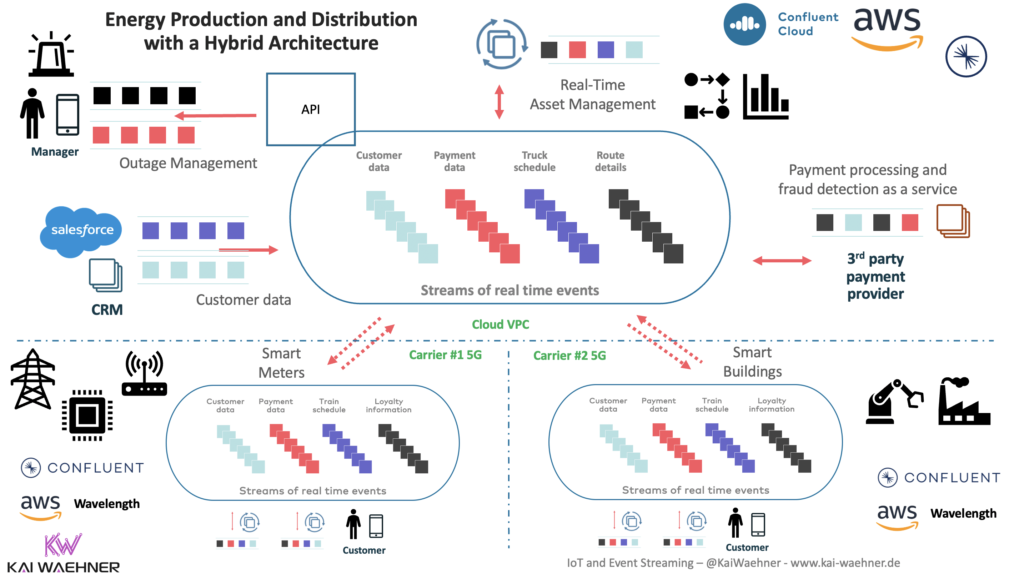
This is not just theory. The joint teams from AWS and Confluent are working on this example in the real world while I am writing this blog post.
Cloud-native? Complete? Everywhere? What Kafka should I buy?
After exploring different vendors, let’s now walk through the different deployment options and commercial offerings.
Again, I will not make a feature-by-feature comparison. Way more important is to understand the different concepts and architecture principles: First of all, you need to decide if a self-driving car (= fully managed Kafka) works for you. In that case, why bother at all about Kafka operations? Otherwise, project teams must evaluate partially managed (= complete car) or self-managed (car engine) Kafka offerings.
Here is an overview showing the event streaming landscape. It contains native Kafka offerings, (partly) Kafka-protocol compatible products, and a few relevant non-Kafka solutions:
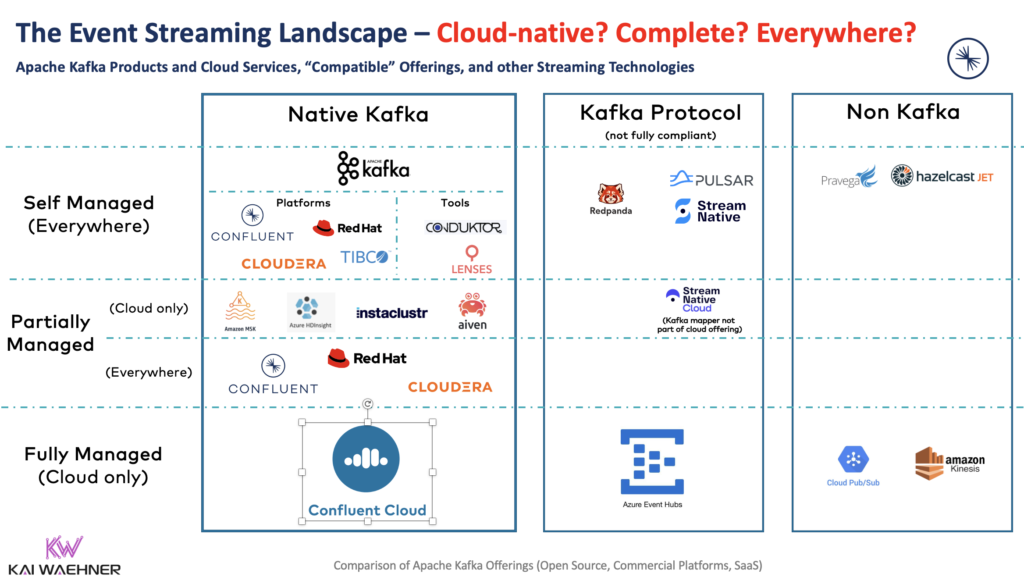
Let’s now take a deeper look into these alternatives to find out how to choose the right one for your next project.
Car Engine: Self-managed Open Source Apache Kafka
The car engine is the heart of the car. It provides the power. It brings you from your source to your destination. However, a lot of work is needed around the motor engine. Tires, steering wheel, breaks, and much more are required. Hence, this is a great solution for playing around, learning how a car works, or building a car by enthusiastic car fanatics.
If you download open-source Apache Kafka from the Apache website or related Docker images, then you can use it for free in all your projects. No limitations. You should be able to get it running quickly. However, be aware that similar to the motor engine of a car, there is much more to do: Operating and monitoring the ZooKeeper and Kafka Clusters, rebalancing partitions, scaling up and down, managing storage, securing and encryption the end-to-end communication between producer, Kafka cluster and consumers, and so much more.
If you can handle the operations burden and risk of downtime, open-source Apache Kafka might be a good option. Some tech giants from Silicon Valley do exactly this. They have hired masses of tech experts (or car fanatics to keep the analogy) to run huge Kafka clusters to process trillions of messages and gigabytes of data per second.
Free Kafka add-ons to build your car
Plenty of open-source Kafka add-ons originated through this. Just to name a few tools for very different purposes: kafkacat, Kafka Manager, Kafdrop, burrow, cruise control, and so many more. Some are maintained well, others not at all. Of course, you will never get guarantees to get a version upgrade or bug fix. Often built by a tech giant for their specific scenario. Not easily usable outside that organization and without a big community.
Alternatively, there are well-maintained community projects like Confluent’s Schema Registry, REST Proxy, and ksqlDB, all under Confluent Community License (CCL). This is not open source but free to use if you are not a cloud provider like AWS. Confluent also provides some components under Apache 2.0 license, such as the widely used non-Java Kafka clients based on librdkafka or the parallel-consumer to integrate with non-scalable interfaces like web services in a scalable and performant way.
Tuned Car Engine: Self-managed Kafka Product
If you want or need to self-manage your Kafka infrastructure, then you still have more options than just using open-source Apache Kafka and (well or not so well maintained) open-source add-ons:
- Open-source Apache Kafka with additional commercial tools for operations and monitoring. For instance, Lenses or Conduktor.
- Complete commercial platforms. For instance, Confluent Platform, Red Hat AMQ, Cloudera DataFlow.
These “tuned car engines” are based on top of Apache Kafka (or at least parts of it) and provide additional tooling for development, operations, monitoring, security, etc. Maturity of the tools, support SLAs, expertise, and consulting vary a lot between vendors. I recommend to talk to your potential vendors. Ask the right questions to understand if they really understand what they seem to sell and support.
Shiny user interfaces attract many people. Just be careful. The underlying technology needs to work reliably and scale for your needs. The UI is nice to have on top of the infrastructure. Nevertheless, a good UI can improve the developer experience, increase time to market, and bring other benefits.
Should I use a (Tuned) Car Engine and Build my own Car?
All the explored options above are still self-managed. If you consider building your own car with a car engine, always evaluate the cost-benefit equation.
Remember, at the beginning of this post, I talked about solving business problems. Hence, don’t forget to consider all the impacts on:
- Total Cost of Ownership (TCO)
- Risk (downtime, data loss, security, governance, etc.)
- Return on Investment (ROI)
- Time-to-market (Increased developer velocity and increased business agility)
At Confluent, we do TCO assessments with our prospects and customers so that they understand the complete costs and risks of a Kafka project. Such an assessment should be part of every Kafka comparison!
Hence, don’t forget to evaluate other alternatives to open-source Apache Kafka seriously. If self-managed Apache Kafka still works for you after the evaluation, then do it! But be aware that even the tech giants from Silicon Valley consider and buy other options today. Many had to build Kafka infrastructure because there was no other alternative when they built it years ago.
Does my favorite open-source vendor really provide open-source?
Also, be careful: Some open source solutions don’t provide an easy way to build the product. So, evaluate what exactly is available from a so-called “open source offering”: Only a binary download? Docker images? Or can you also build and deploy everything from scratch easily and documented (not just in theory !!!) using Maven, Gradle, Terraform, Ansible, or similar build and automation tools?
Before building your own car with an available car engine, why not buy a car? Let’s consider next if a complete car might make more sense for you.
Complete Car: Kafka Products and Kubernetes-based PaaS
I am not a car fanatic. I want to buy a complete car that I can drive everywhere. You should also at least consider this option!
In Kafka terms, this means you get help from the product for running the Kafka infrastructure. Buzzwords from vendors include terms like “platform as a service”, “private cloud”, “fully managed”, and “cloud-native”. In the end, the products help you with provisioning, operating, and monitoring everything.
The main benefit compared to the (tuned) car engines is that these products give you a more elastic, scalable, and automated infrastructure. Two options exist today:
- Kubernetes-based products that can run everywhere on-premise and across multiple cloud providers. Examples: Confluent Platform, Cloudera DataFlow (CDF), Red Hat AMQ respectively Red Hat OpenShift Streams for Apache Kafka.
- Proprietary cloud offerings that are typically tied to the related hyperscaler. Example: Amazon MSK.
This is similar to buying a car: It comes preassembled. Although, of course, you are still responsible for operating and maintaining it.
In Kafka terms, for many scenarios, these self-managed Kafka products (= car) are a better choice than the self-managed Kafka (= car engine) because they partially reduce the operations burden, risk, and (hopefully) TCO.
A complete car is still not self-driving!
However, as you know, today’s cars still need a lot of manual work: Driving, refueling, maintenance, and more. In Kafka terms: How much works do you still have to do by yourself? Do you have to handle rolling upgrades manually? Do you have to rebalance partitions on brokers? How do you scale up and down? Who fixes security issues and bugs? And so on.
Hence, it is really a pity that most vendors use incorrect marketing intentionally! No one of the above solutions are fully managed. All of them require work to do by you to operate the Kafka cluster. All of them! Confluent Platform. Cloudera DataFlow. Red Hat AMQ. Red Hat OpenShift Streams for Apache. Kafka Amazon MSK. None of these services is fully managed!
Each car brand and model is different. If you buy a Porsche, you probably have very different expectations than buying a small medium-priced car from another brand. The same is true for all the self-managed Kafka products on the market. Each product is very different: Confluent Platform. Cloudera DataFlow. Red Hat AMQ / OpenShift Streams for Apache Kafka. Amazon MSK. All of them have strengths and weaknesses. Make sure it fits your expectations so that you can solve your business problem within your required SLAs and budget.
Having said this, wouldn’t it be nice if you don’t have to worry about all these things? Let’s explore the self-driving Kafka car next.
Self-driving Car: Fully-managed Cloud Kafka Service
A self-driving car provides a complete solution. You just tell it where you want to go. It drives you automatically. Chooses the best route. Allows relaxing, reading, playing games, or similar things. Of course, an autonomous car with level 5 automation is not mature yet (beyond some early stages, like Waymo operating in the desert in Phoenix where no rain and other weather or traffic issues occur).
In Kafka terms, the solution needs to be fully managed by the vendor.
Fully managed means serverless (i.e., you don’t have to care and even don’t get access to the Kafka Brokers at all). Mission-critical SLAs. Usage-based billing. And so on. Like you know it from other really fully managed cloud offerings such as AWS S3 or AWS Kinesis. These are fully managed. Amazon MSK is not!
Checklist to compare partially managed and fully-managed Kafka cloud services
Please compare different Kafka cloud offerings by yourself. Here are some bullet points to check:
Infrastructure management
- Upgrades (latest stable version of Kafka)
- Patching
- Maintenance
Kafka-specific management
- Sizing (retention, latency, throughput, storage, etc.)
- Data balancing for optimal performance
- Performance tuning for real-time and latency requirements
- Fixing Kafka bugs
- Uptime monitoring and proactive remediation of issues
- Recovery support from data corruption
Scaling
- Scaling the cluster as needed
- Data balancing the cluster as nodes are added
- Support for any Kafka issue with less than 60-minute response time
Most “Kafka as a service” offerings are only partially managed. That’s like a self-driving car which you actually have to control by yourself (more like level 3, not level 5 in autonomous driving terminology).
At this point, I have to do marketing for my employer. However, it is not an advertisement, but reality: Confluent Cloud is the only offering on the market that provides a complete, fully-managed Kafka SaaS offering. And it is available everywhere – on all major cloud provides (AWS, Azure, GCP). All the other Kafka offerings are NOT fully managed – even though most vendors claim it!
Other Vehicles on the Street: Comparison of Kafka-Compatible and Non-Kafka Offerings
On the street, we don’t see just one car brand or car model. Plenty of different ones exist. Nevertheless, they have to drive on the same streets. Competition creates innovation and tackles different markets and personal interests. That’s great. The same is true for Kafka!
I focused on the “mainstream Kafka vendors” in the above sections. Namely, Confluent, Cloudera, Red Hat, Amazon MSK. Obviously, more Kafka offerings exist on the market. Some are really good for some use cases. Others are more like an April Fools’ Joke, in my opinion. Let’s quickly walk through a few other offerings.
Kafka-related offerings
- A few more car brands: Azure HD Insight’s Kafka, Aiven, cloudkarafka, Instaclustr. These Kafka-native PaaS vendors provision Kafka clusters for you. Similarly to Amazon MSK. These offerings slightly differ from each other. In summary, they typically ask you to do storage management, scalability configuration, performance tuning, etc., by yourself. This is definitely not self-driving!
- A self-driving car: Azure Event Hubs is a SaaS offering from Microsoft supporting the Kafka protocol. It has several limitations regarding support of the Kafka API and infrastructure. A solid product. Contrary to Confluent Cloud, you don’t get additional capabilities such as fully-managed connectors, Schema Registry, RBAC, Audit Logs, and much more. And obviously, this product is only available on the Azure cloud.
- A vintage car: TIBCO focuses on their legacy messaging solutions like TIBCO EMS. They (try to) provide support for Kafka (and Pulsar) to sell their proprietary technologies. Zero expertise or interest in Kafka. They even provide Kafka as .exe Windows file even though this does not work well in reality. If you need to run Kafka brokers on Windows (e.g., for development), only use Kafka Docker containers and the Windows Subsystem for Linux 2 (WSL 2).
Non-Kafka offerings
- Self-driving scooters: AWS Kinesis, GCP Pub/Sub, etc., are solid SaaS offerings that work well if you don’t need to be vendor-agnostic and if the feature set, scalability, and pricing work for you.
- A few bicycles, motorbikes, and cars: Non-Kafka solutions, including message queuing (IBM MQ, RabbitMQ, NATS), stream processing (Flink, Spark Streaming), event streaming (Pulsar, Pravega), integration middleware (many open-source/proprietary and self-managed/SaaS). These are solid frameworks and products that you can compare to Kafka. There is no silver bullet! Make sure to understand the differences between MQ/ETL/ESB and Kafka when you do your evaluation.
Connected Car Fleet: Multiple Kafka Clusters and Hybrid Integration
The digital transformation around connected vehicles is a real game-changer. Vehicles talk to each other (V2V), their infrastructure like traffic lights (V2I), and to many other backend systems (V2X).
As a side note: If you are interested in the relation of Kafka and connected vehicles/mobility services, I covered use cases for connected vehicles and V2X in my blog series about Kafka and MQTT in more detail.
Today, we usually have to drive by ourselves. This is expected to change in the next five to ten years. However, even if Waymo, Telsa, and the likes successfully deploy level 4 and level 5 cars to the street (including legal allowance), we will still only see a fraction of all cars driving themselves. It will be a connected fleet with regular cars and self-driving cars for at least a few decades. Not even sure if self-driving cars can ever go to India 🙂
The same is true for Kafka. Self-managed open-source Kafka is still mainstream today. Many enterprises move to Kubernetes and private or public cloud infrastructure, though. In parallel, most new Kafka clusters in the cloud are consumed from vendors that provide partially or fully managed services so that the enterprise can focus on their business problems.
Kafka is deployed across infrastructures. Often, new projects have a cloud-first strategy. But there are still a lot of data centers out there. Not just for legacy reasons. For instance, in Russia, there is no public cloud provider at all. Kafka has to be deployed on-premise. And there is the trend of deploying Kafka at the edge (i.e., outside a data center).
Architectures for Hybrid Kafka (SaaS + PaaS + Self-Managed)
Hence, a connected car fleet with various brands and operation types is required. Most enterprises use different vendors and cloud providers. Most enterprises have their own data centers and a multi-cloud strategy. Hybrid Kafka includes various architectures. This includes:
- Kafka in one or multiple clouds. There is no Azure or GCP in China, only Alibaba and Tencent Cloud. This is why Audi built their connected car infrastructure in the cloud, but with Kafka instead of proprietary cloud services. They need to deploy globally.
- Kafka at the edge outside the data center, e.g., in a smart factory, oil rigs, ships, retail stores, etc. Often deployed as a single broker on very lightweight hardware, without high availability.
- Kafka stretched across regions, i.e., one single cluster operating across the US west, east, central. Confluent’s Multi-Region Clusters (MRC) is mainly used for this architecture.
- Replication between different Kafka clusters. Use cases include aggregation, disaster recovery, global deployments, and more. Kafka-native technologies such as MirrorMaker 2, Confluent Replicator, or Confluent Cluster Linking enable these architectures.
“Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments” explores this topic in more detail.
Focus on the Business Problem when making your Kafka Comparison!
This blog post explored the different deployment options for Kafka. Several open-source and commercial options exist.
If you want to remember one thing from this post: A fully-managed Kafka service (= real SaaS) takes over all the operations complexity and risk for you, similarly like a self-driving car handles all the actions on the street. However, most services available today only provide self-managed Kafka clusters. Fully managed is often only a marketing term.
A hybrid architecture is the norm in most enterprises. A combination of fully-managed Kafka in the public cloud with self-managed Kafka on premise or at the edge works very well and is the way to go for most enterprises across industries.
What Kafka car do you drive today? What is your plan for the future? Maybe you are already planning to migrate to a self-driving car to focus on your business problems – and consequently reducing cost and risk this way, too? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
