Agentic AI
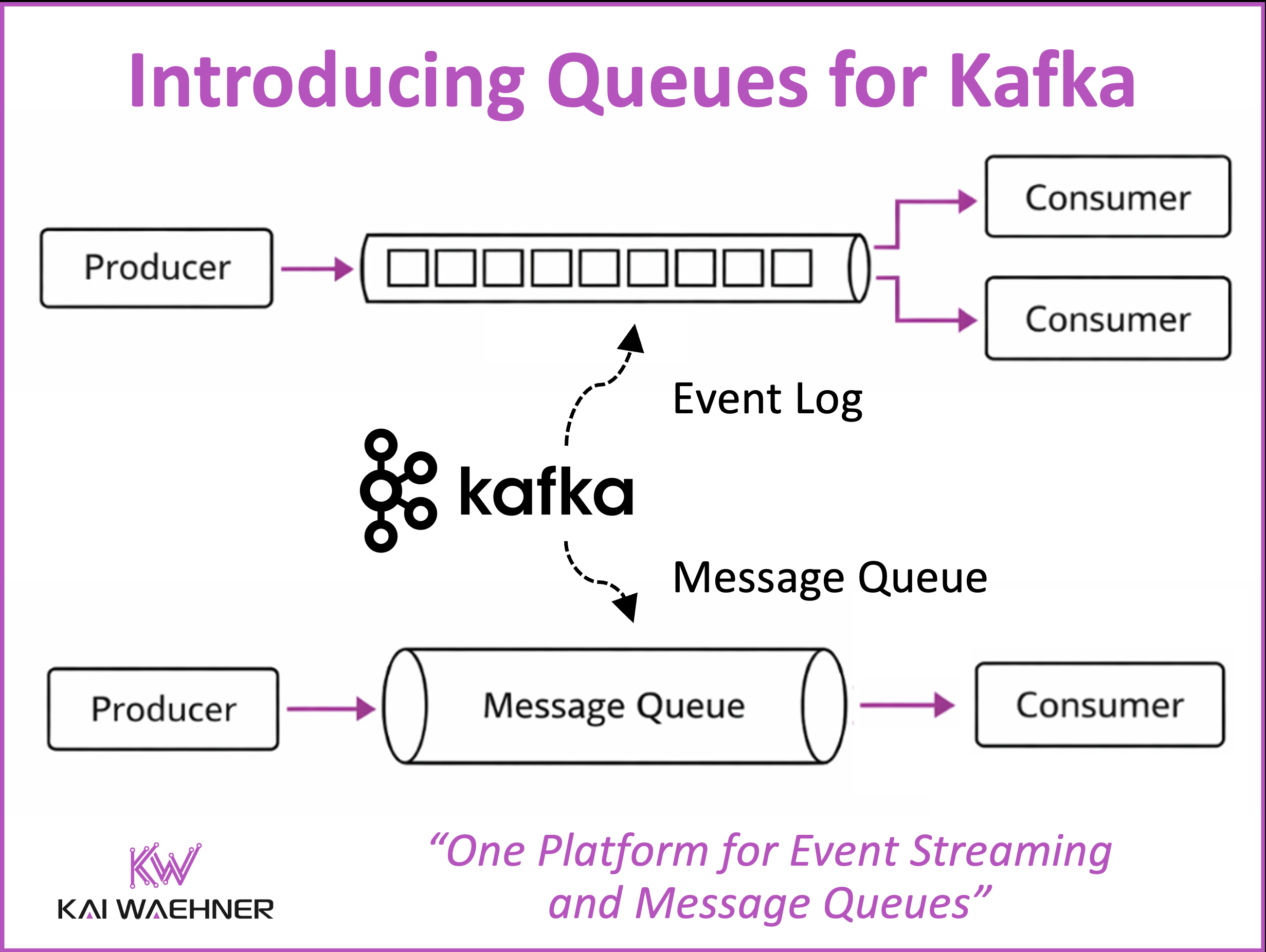
AMQP, JMS, Kafka, and MQTT get compared as rivals, but a message broker, a log, and a device protocol sit on different layers. A clear


Most vendors sell milliseconds, but most enterprise use cases do not need them. A critical look at Kafka, Flink, Spark, Pulsar, and Redpanda, and why

Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka
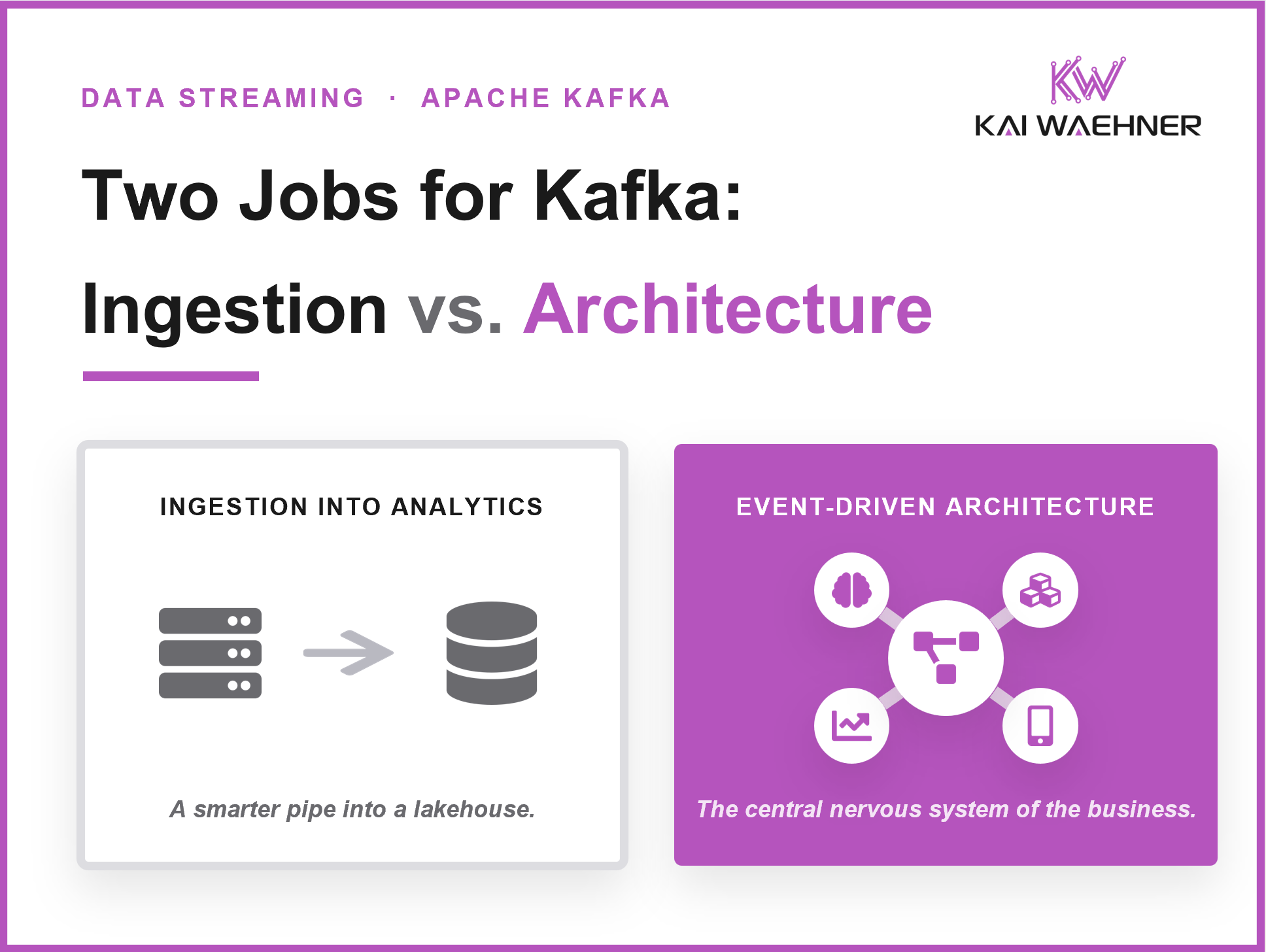
Databricks and Snowflake now speak the Kafka protocol. But using the Kafka API to feed a lakehouse is very different from running Kafka as the
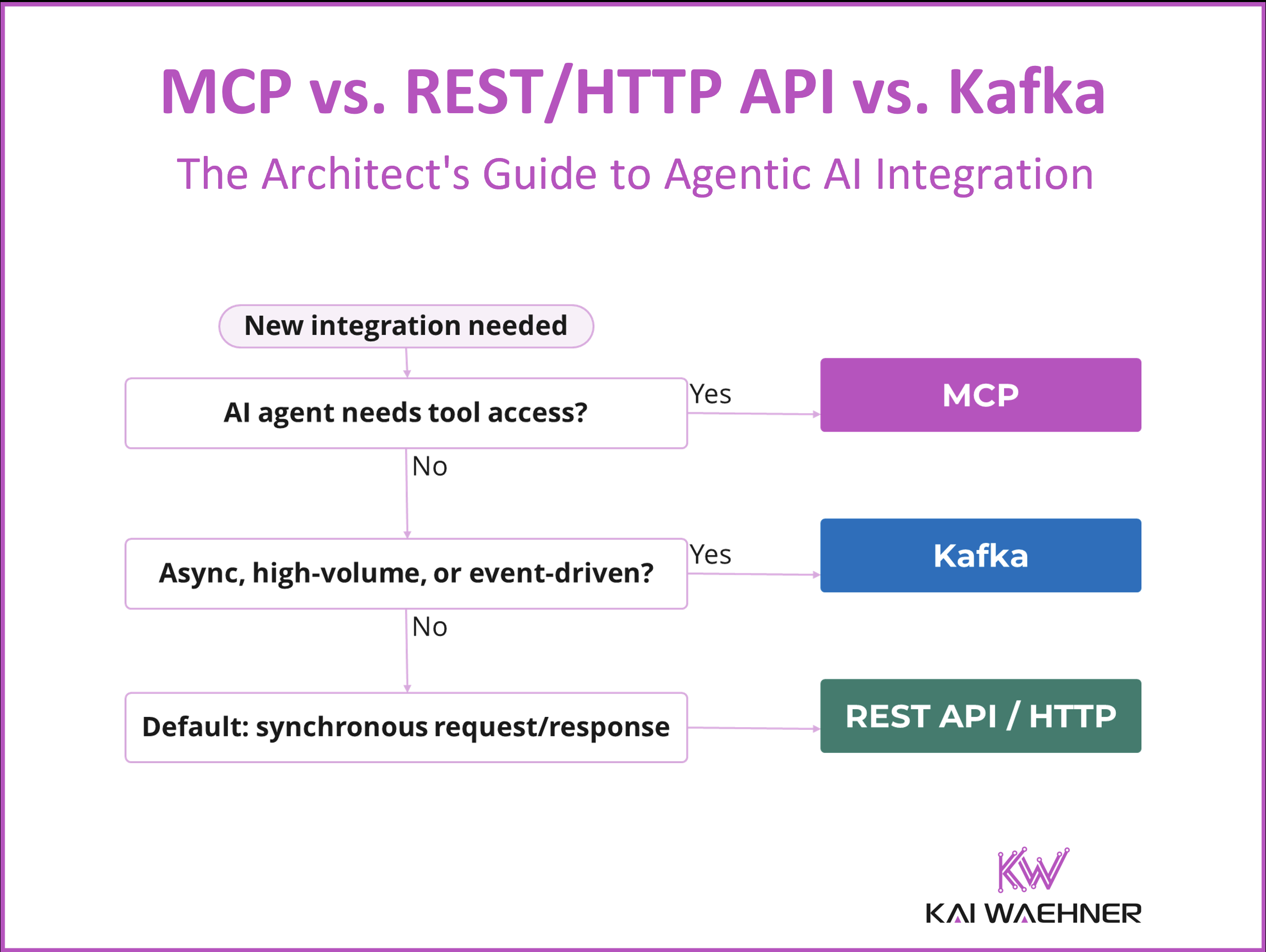
MCP, REST/HTTP APIs, and Apache Kafka are not alternatives. They solve different problems at different layers of the architecture. This article maps the decision: what
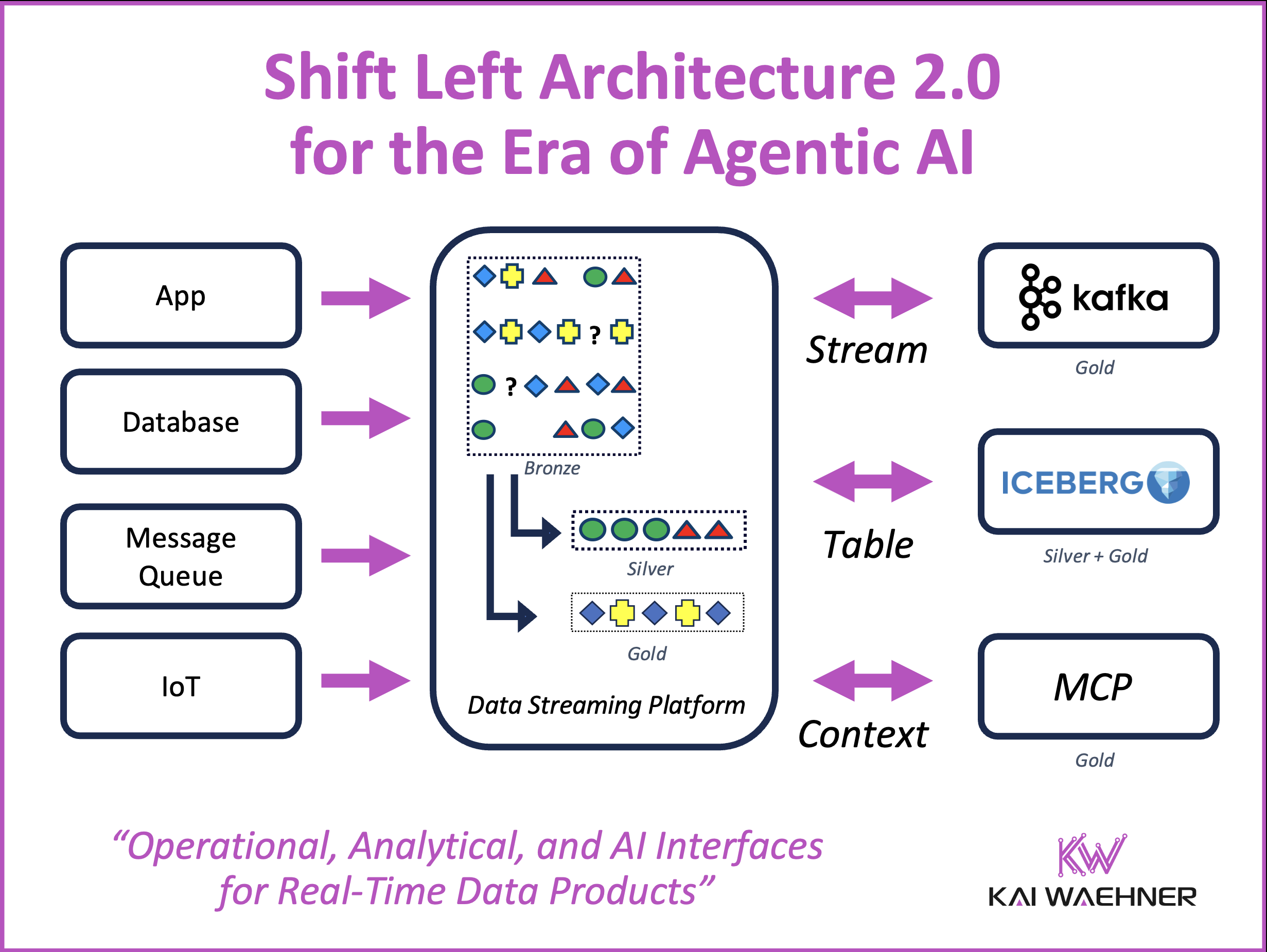
The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data products are built once and served to multiple consumers. The
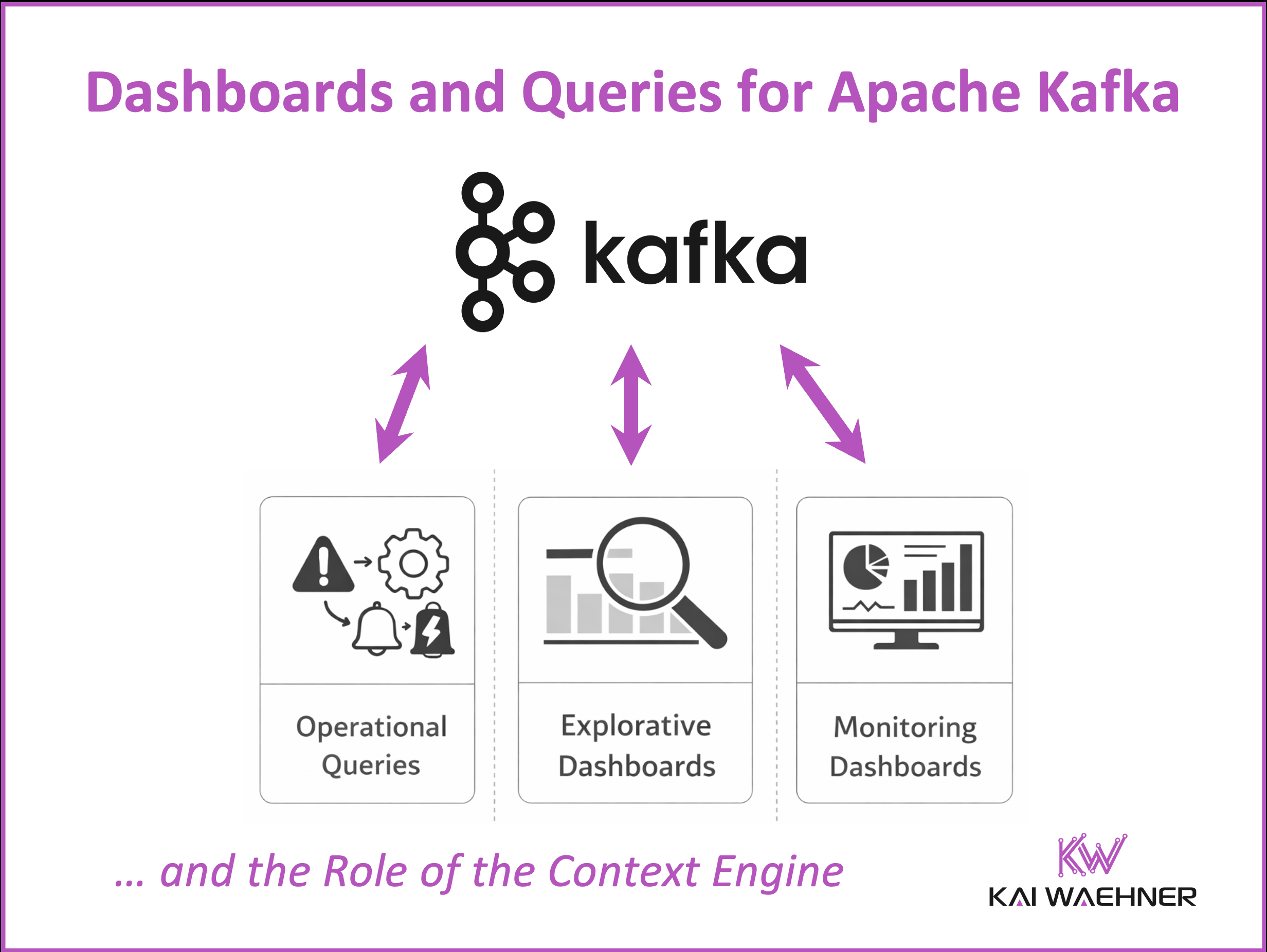
Dashboards are a popular way to make streaming data visible and useful, but they are not always the right solution. This blog post explains when
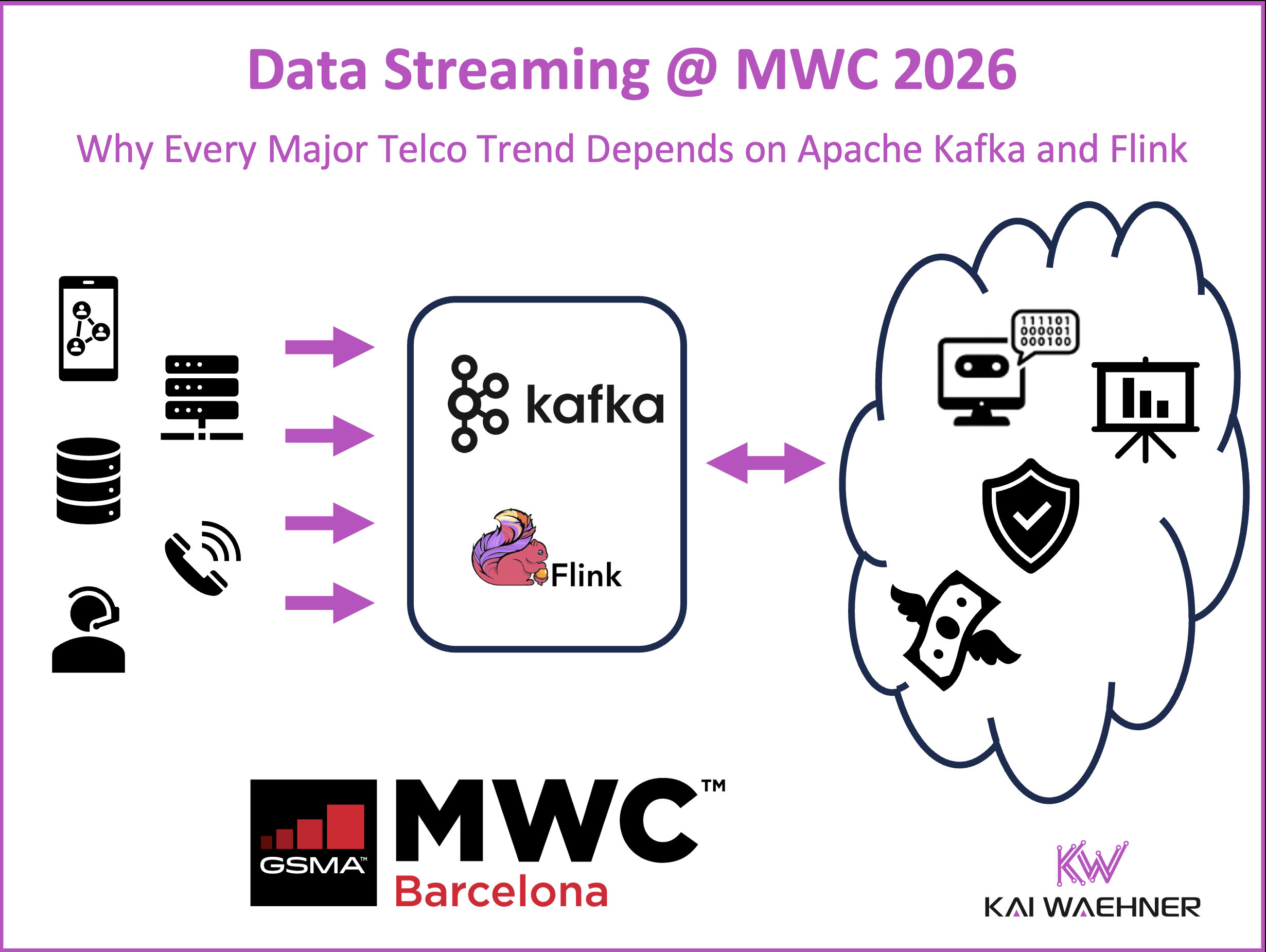
Mobile World Congress (MWC) 2026 highlights the shift from batch systems to real time data streaming in telecom. AI and agentic automation, network APIs, sovereign
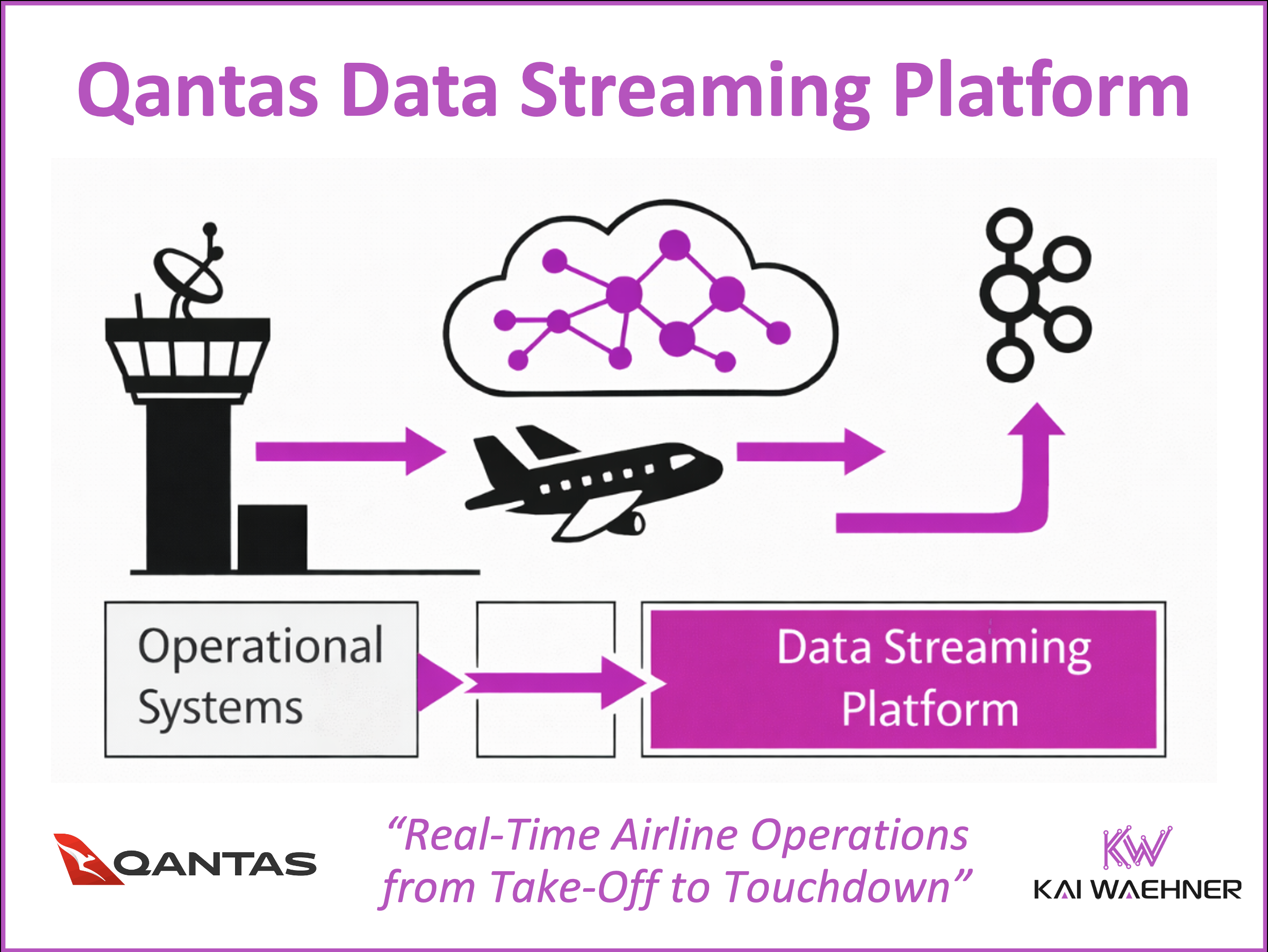
This blog post explores how data streaming transforms airline operations by enabling real-time visibility, faster decision-making, and improved customer experience. Using Qantas as a leading



You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information