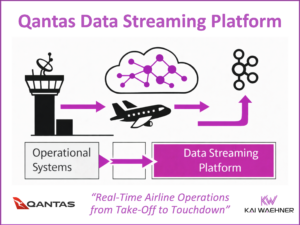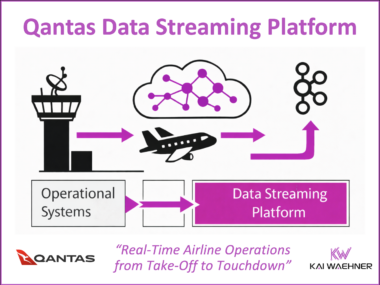
From Takeoff to Touchdown: Real-Time Aviation with Data Streaming at Qantas
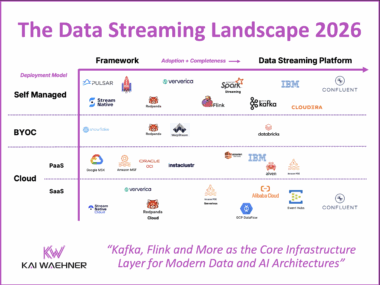
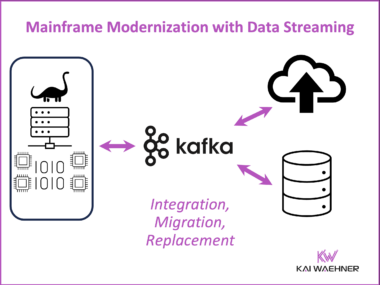
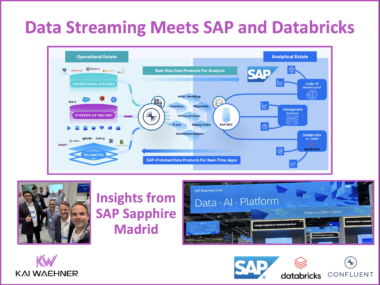
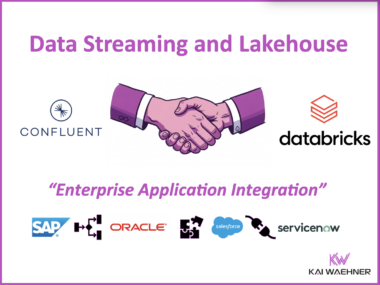
This blog post explores how data streaming transforms airline operations by enabling real-time visibility, faster decision-making, and improved customer experience. Using Qantas as a leading example, it highlights how a modern data streaming platform powered by Apache Kafka supports flight operations, crew coordination, baggage handling, and airport collaboration. It also explains technical integrations using Kafka Connect for AIDX message processing. The Qantas story illustrates how real-time data creates tangible business value across the aviation industry.