
XML messages and XML Schema are not very common in the Apache Kafka and Event Streaming world! Why? Many people call XML legacy. It is complex, verbose, and often associated with the ugly WS-* Hell (SOAP, WSDL, etc). On the other side, every company older than five years uses XML. It is well understood, provides a good structure, and is human- and machine-readable.
This post does not want to start another flame war between XML and other technologies such as JSON (which also provides JSON Schema now), Avro, or Protobuf. Instead, I will walk you through the three main approaches to integrate between Kafka and XML messages as there is still a vast demand for implementing this integration today (often for integrating legacy applications and middleware).
XML and XML Schema
Extensible Markup Language (XML) is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium’s XML 1.0 Specification of 1998 and several other related specifications – all of them free open standards – define XML.
The design goals of XML emphasize simplicity, generality, and usability across the Internet. It is a textual data format with strong support via Unicode for different human languages. Although the design of XML focuses on documents, the language is widely used for the representation of arbitrary data structures such as those used in web services. Several schema systems exist to aid in defining XML-based languages, while programmers have developed many application programming interfaces (APIs) to assist the processing of XML data.
SOAP / WSDL Web Services – The WS-* Hell
Web Services use XML messages that follow the SOAP standard and have been popular with traditional enterprises for many years. In such systems, there is often a machine-readable description of the operations offered by the service written in the Web Services Description Language (WSDL). Web Services are one of the predominant use cases for XML integration. Some people call this the “WS-* Hell”:

Kafka for any Data Format (JSON, XML, Avro, Protobuf, …)
Kafka can store and process anything, including XML. The Kafka brokers are dumb. They don’t care about data formats. The implementation of Kafka under the hood stores and processes only byte arrays. This approach follows the design principle of dumb pipes and smart endpoints (coined by Martin Fowler for microservice architectures). Dumb brokers are one of the architectural reasons why Kafka scales and performs so well.
As Kafka supports any data format, XML is no problem at all. It accepts any serializable input format. XML is just text so that plain string serializers can be used. However, if you want additional validation before pushing messages into Kafka (like checking the content is actually XML or doing Schema Validation using XML Schema), then you need to write your own XML Serializer/Deserializer implementation.
XML mappings can be very complex, including referencing other documents and using plenty of ugly open standards. XML includes generic standards such as WS-Security or industry-specific standards such as XBRL for regulatory processing or HL7 for healthcare. It is a mess. Period. Even mature tools struggle as soon as any parts of such a standard are adjusted to their own needs (even though the standards support customization).
Kafka works with any programming language, and Confluent also provides a REST Proxy for HTTP(S) communication with Kafka. But these clients require the developer to implement all the complex XML mapping and processing. Hence, let’s now talk about the most common approaches to implement the integration between any XML-based application and Apache Kafka: 3rd party middleware (ETL / ESB tools) and Kafka-native Kafka Connect.
Kafka and XML via Middleware (ETL, ESB)
Apache Kafka and traditional middleware (ETL, ESB) are frenemies (friends and enemies). Check out this blog and video recording/slide deck for a more in-depth discussion and comparison. If these legacy integration tools such as TIBCO BusinessWorks or Software AG webMethods do one thing well, then it is graphical mappings of complex XML structures, including good and mature (but not 100%) support of the ugly WS-* web service standards.
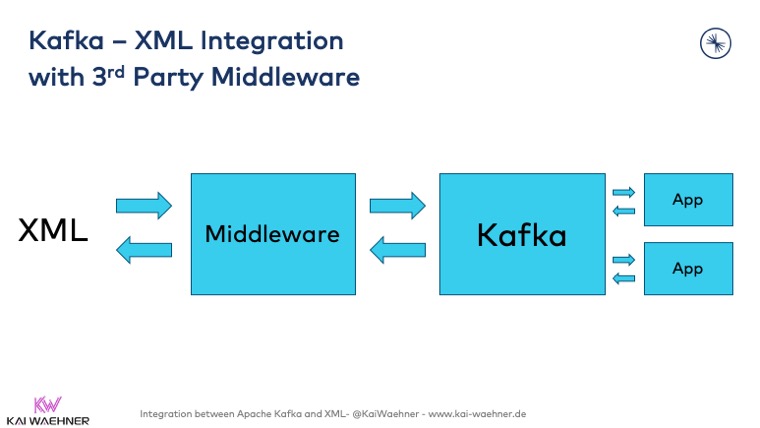
Pros of 3rd Party Middleware for XML-Kafka Integration
- Visual coding for a more straightforward mapping experience (especially crucial for very complex structures) – for all coders: Trust me, this is really easier and more time-efficient than writing, testing, and debugging source code!
- Mature (10-20 years old technologies don’t have many bugs anymore – if they are still alive)
- Support of complex XML Schema structures (but yet often issues with import, UI, and export)
- (Often) already in place (implemented, tested, and deployed)
- Kafka integration exists for any middleware which is still alive (i.e., maintained and supported by the vendor)
Cons of 3rd Party Middleware for XML-Kafka Integration
- Products are legacy – as old as the source systems
- Monolithic, inflexible architecture
- Separate infrastructure to operate, test, maintain and pay
- End-to-end integration is more challenging (from a technical and support perspective) as two systems in the middle instead of just one
- Licensing
- Point-to-point and tight coupling, and not event-based streaming with real decoupling
- (Often) proprietary solution
Traditional middleware (such as TIBCO, IBM, Software AG, or Mulesoft) complements Kafka deployments. If you have the middleware already running and licensed (and do not plan to migrate away from it), then this is a viable approach to integrate between XML messages from legacy systems and Kafka.
Kafka and XML via Kafka Connect
The open Kafka ecosystem provides Kafka-native support for XML integration leveraging Kafka Connect. Kafka Connect is a Kafka-native tool for scalably and reliably streaming data integration between Apache Kafka and other data systems. It makes it simple to quickly define connectors that move large data sets into and out of Kafka. Think about it as ESB-on-Kafka.
Use cases include
- Messaging integration (MQ)
- Mainframe offloading
- File outputs from batch processes
- Web services (SOAP / WSDL / WS-*)
- Legacy applications
Pros
- Kafka-native (leveraging Kafka under the hood for scalability, throughput, high availability, exactly-once semantics, low latency, etc.)
- Decoupled design (Domain-driven Microservice approach instead of tight coupling)
- Open ecosystem and flexible integration with any data sources and sinks – check out Confluent Hub for hundreds of open source and commercial connectors
- Cloud-native to be deployed in any edge / on-premise or cloud infrastructure such as Kubernetes
Cons
- Limited support for complex XML Schemas and standards – not all ugly documents will work well
- No visual coding – unfortunately, no Kafka-native visual coding tools exist in 2020. Let’s go, Confluent! 🙂
Let’s take a look at two Kafka Connect approaches in more detail: A dedicated XML Connector and an SMT (Single Message Transformation) embedded into any Kafka Connect source or sink connector.
Kafka Connect Connector for XML Files
An XML connector directly accesses the XML file to parse and transform the content:
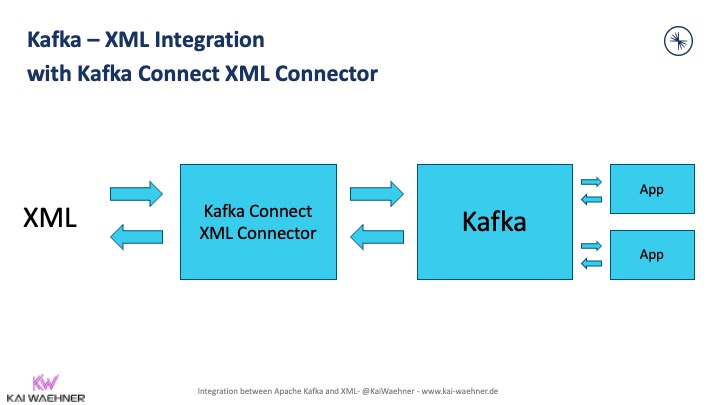
Connect FilePulse is an open-source Kafka Connect connector built by streamthoughts to parse, transform and stream any XML file. Other file formats are also supported. But as many other tools support the modern data formats such as JSON, CSV, Avro, or Protobuf, I really think the highlight of this connector is the XML support.
Features:
- Support for recursive scanning of local directories.
- Reading and writing files into Kafka line by line.
- Support multiple input file formats (e.g: CSV, JSON, AVRO, XML).
- Parsing and transforming data using built-in or custom processing filters
- Error handler definition
- Monitoring files while they are written into Kafka
- Support pluggable strategies to cleanup up completed files
Here is an excellent tutorial for using this XML connector for Kafka Connect: Streaming data into Kafka – Loading an XML file.
The Connect FilePulse Kafka Connector is the right choice for direct integration between XML files and Kafka.
SMT for Embedding XML Transformations into ANY Kafka Connect Connector
An SMT (Single Message Transformation) is part of the Kafka Connect framework. SMTs are applied to messages as they flow through Kafka Connect. They transform inbound messages after a source connector has produced them, but before they are written to Kafka. SMTs transform outbound messages before they are sent to a sink connector.
An SMT can be embedded into any Kafka Connect source or sink connector. Hence, the XML SMT for Kafka Connect allows direct integration with any interface and mapping XML messages without the need for storing the file or using a specific XML connector.
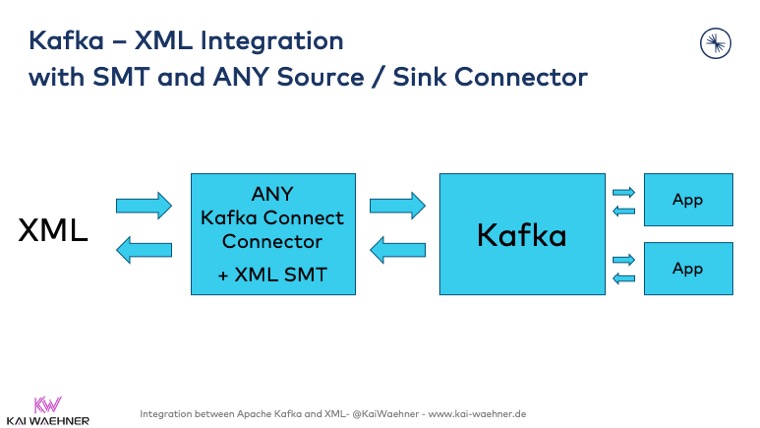
SMTs even allow to add or change metadata, e.g., by adding a new header in addition to the key and value of the message.
Here is an example: Receive XML messages from JMS-based messaging platforms and convert the XML payload to JSON, AVRO, or Protobuf for further processing and integration into the rest of the (modern) enterprise architecture. For instance, Confluent provides a generic JMS connector but also dedicated connectors for various legacy MQ products such as IBM MQ (often running on the mainframe), TIBCO EMS, and ActiveMQ. The XML SMT allows on-the-fly transformation of the incoming XML messages. I have seen integration and later replacement of these MQ tools across the globe in any kind of industry.
Dead Letter Queue (DLQ) for Handling Bad XML Messages
Just transforming messages is often not sufficient. A Dead Letter Queue (DLQ), aka Dead Letter Channel, is an Enterprise Integration Pattern (EIP) to handle bad messages. This design pattern is complementary for XML integration. For instance, a DLQ can store badly processed XML that didn’t fit the XSD in the transform. Here is an example of how to implement the rerouting to a DLQ using the above SMT.
Confluent Schema Registry for Data Governance
The Confluent Schema Registry is a complimentary (optional) tool. It provides a smart implementation of data format and content validation (including enforcement, versioning, and other features). I see it used in ~70% of Kafka projects across the globe. As soon as you do more than just data ingestion into a data lake like HDFS or S3, the added value is enormous. Today, Confluent Schema Registry supports JSON Schema, Avro, and Protobuf.
The Schema Registry provides an open interface and is pluggable. For example, some users have asked for Schema Registry to support XML. Now, you can add XML support to Schema Registry directly, and use the Schema Registry to store both XML and Avro at the same time. For more on how to add your schema formats, please refer to the documentation. The workaround is to do the discussed XML-to-another-format transformation first and start your event streaming data governance from that point.
Summary
XML is predominant in most enterprises and mostly used for legacy applications, batch processing, and SOAP / WSDL web services. A digital transformation can only be successful if the old world is connected well to the new world (as you might have learned in my example about how to integrate between Kafka and Mainframes).
This post explored the three most common options for integration between Kafka and XML:
- XML integration with a 3rd party middleware
- Kafka Connect connector for integration with XML files
- Kafka Connect SMT to embed the transformation into ANY other Kafka Connect source or sink connector to transform XML messages on the flight
What are your experiences with XML integration for Kafka? Which implementation did you choose? What challenges did you face, and how did you or do you plan to solve this? What is your strategy? Let’s connect on LinkedIn and discuss it!
