Time to get more innovative; even with the mainframe! This blog post covers the steps I have seen in projects where enterprises started offloading data from the mainframe to Apache Kafka with the final goal of replacing the old legacy systems.
“Mainframes are still hard at work, processing over 70 percent of the world’s most important computing transactions every day. Organizations like banks, credit card companies, medical facilities, stock brokerages, and others that can absolutely not afford downtime and errors depend on the mainframe to get the job done. Nearly three-quarters of all Fortune 500 companies still turn to the mainframe to get the critical processing work completed” (BMC).
Cost, monolithic architectures and missing experts are the key challenges for mainframe applications. Mainframes are used in several industries, but I want to start this post by thinking about the current situation at banks in Germany; to understand the motivation why so many enterprises ask for help with mainframe offloading and replacement…
Finance Industry in 2020 in Germany
Germany is where I live, so I get the most news from the local newspapers. But the situation is very similar in other countries across the world…
Here is the current situation in Germany.
Challenges for Traditional Banks
- Traditional banks are in trouble. More and more branches are getting closed every year.
- Financial numbers are pretty bad. Market capitalization went down significantly (before Corona!). Deutsche Bank and Commerzbank – former flagships of the German finance industry – are in the news every week. Usually for bad news.
- Commerzbank had to leave the DAX in 2019 (the blue chip stock market index consisting of the 30 major German companies trading on the Frankfurt Stock Exchange); replaced by Wirecard, a modern global internet technology and financial services provider offering its customers electronic payment transaction services and risk management. UPDATE Q3 2020: Wirecard is now insolvent due to the Wirecard scandal. A really horrible scandal for the German financial market and government.
- Traditional banks talk a lot about creating a “cutting edge” blockchain consortium and distributed ledger to improve their processes in the future and to be “innovative”. For example, some banks plan to improve the ‘Know Your Customer’ (KYC) process with a joint distributed ledger to reduce costs. Unfortunately, this is years away from being implemented; and not clear if it makes sense and adds real business value. Blockchain has still not proven its added value in most scenarios.
Neobanks and FinTechs Emerging
- Neobanks like Revolut or N26 provide an innovative mobile app and great customer experience, including a great KYC process and experience (without the need for a blockchain). In my personal International bank transactions typically take less than 24 hours. In contrary, the mobile app and website of my private German bank is a real pain in the ass. And it feels like getting worse instead of better. To be fair: Neobanks do not shine with customers service if there are problems (like fraud; they sometimes simply freeze your account and do not provide good support).
- International Fintechs are also arriving in Germany to change the game. Paypal is the normal everywhere, already. German initiatives for a “German Paypal alternative” failed. Local retail stores already accept Apple Pay (the local banks are “forced” to support it in the meantime). Even the Chinese service Alipay is supported by more and more shops.
Traditional banks should be concerned. The same is true for other industries, of course. However, as said above, many enterprises still rely heavily on the 50+ year old mainframe while competing with innovative competitors. It feels like these companies relying on mainframes have a harder job to change than let’s say airlines or the retail industry.
Digital Transformation with(out) the Mainframe
I had a meeting with an insurance company a few months ago. The team presented me an internal paper quoting their CEO: “This has to be the last 20M mainframe contract with IBM! In five years, I expect to not renew this.” That’s what I call ‘clear expectations and goals’ for the IT team… 🙂
Why does Everybody Want to Get Rid of the Mainframe?
Many large, established companies, especially those in the financial services and insurance space still rely on mainframes for their most critical applications and data. Along with reliability, mainframes come with high operational costs, since they are traditionally charged by MIPS (million instructions per second). Reducing MIPS results in lowering operational expense, sometimes dramatically.
Many of these same companies are currently undergoing architecture modernization including cloud migration, moving from monolithic applications to micro services and embracing open systems.
Modernization with the Mainframe and Modern Technologies
This modernization doesn’t easily embrace the mainframe, but would benefit from being able to access this data. Kafka can be used to keep a more modern data store in real-time sync with the mainframe, while at the same time persisting the event data on the bus to enable microservices, and deliver the data to other systems such as data warehouses and search indexes.
This not only will reduce operational expenses, but will provide a path for architecture modernization and agility that wasn’t available from the mainframe alone.
As final step and the ultimate vision of most enterprises, the mainframe might be replaced by new applications using modern technologies.
Kafka in Financial Services and Insurance Companies
I recently wrote about how payment applications can be improved leveraging Kafka and Machine Learning for real time scoring at scale. Here are a few concrete examples from banking and insurance companies leveraging Apache Kafka and its ecosystem for innovation, flexibility and reduced costs:
- Capital One: Becoming truly event driven – offering a service other parts of the bank can use.
- ING: Significantly improved customer experience – as a differentiator + Fraud detection and cost savings.
- Freeyou: Real time risk and claim management in their auto insurance applications.
- Generali: Connecting legacy databases and the modern world with a modern integration architecture based on event streaming.
- Nordea: Able to meet strict regulatory requirements around real-time reporting + cost savings.
- Paypal: Processing 400+ Billion events per day for user behavioral tracking, merchant monitoring, risk & compliance, fraud detection, and other use cases.
- Royal Bank of Canada (RBC): Mainframe off-load, better user experience and fraud detection – brought many parts of the bank together.
The last example brings me back to the topic of this blog post: Companies can save millions of dollars “just” by offloading data from their mainframes to Kafka for further consumption and processing. Mainframe replacement might be the long term goal; but just offloading data is a huge $$$ win.
Domain-Driven Design (DDD) for Your Integration Layer
So why use Kafka for mainframe offloading and replacement? There are hundreds of middleware tools available on the market for mainframe integration and migration.
Well, in addition to being open and scalable (I won’t cover all the characteristics of Kafka in this post), one key characteristic is that Kafka enables decoupling applications better than any other messaging or integration middleware.
Legacy Migration and Cloud Journey
Legacy migration is a journey. Mainframes cannot be replaced in a single project. A big bang will fail. This has to be planned long-term. The implementation happens step by step.
Almost every company on this planet has a cloud strategy in the meantime. The cloud has many benefits, like scalability, elasticity, innovation, and more. Of course, there are trade-offs: Cloud is not always cheaper. New concepts need to be learned. Security is very different (I am NOT saying worse or better, just different). And hybrid will be the normal for most enterprises. Only enterprises younger than 10 years are cloud-only.
Therefore, I use the term ‘cloud’ in the following. But the same phases would exist if you “just” want to move away from mainframes but stay in your own on premises data centers.
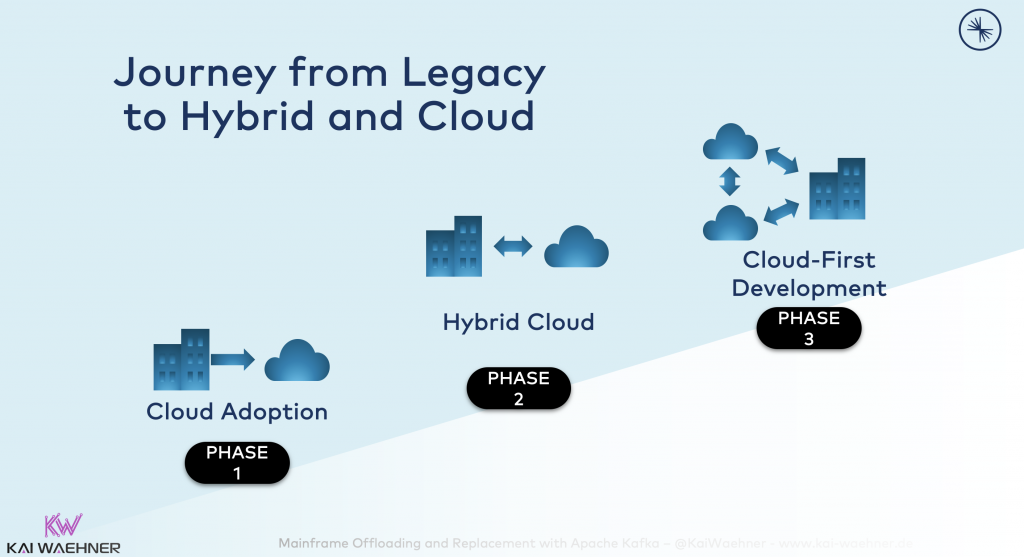
On a very high level, mainframe migration could contain three phases:
- Phase 1 – Cloud Adoption: Replicate data to the cloud for further analytics and processing. Mainframe offloading is part of this.
- Phase 2 – Hybrid Cloud: Bidirectional replication of data in real time between the cloud and application in the data center, including mainframe applications.
- Phase 3 – Cloud-First Development: All new applications are build in the cloud. Even the core banking system (or at least parts of it) is running in the cloud (or in a modern infrastructure in the data center).
How do we get there? As I said, a big bang will fail. Let’s take a look at a very common approach I have seen at various customers…
Status Quo: Mainframe Limitations and $$$
The following is the status quo: Applications are consuming data from the mainframe; creating expensive MIPS:
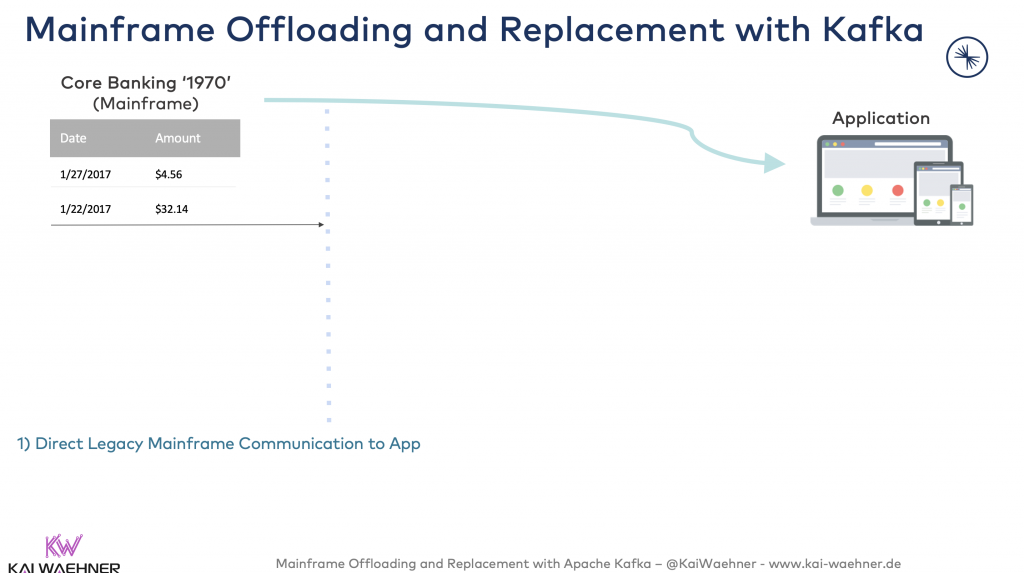
The mainframe is running and core business logic is deployed. It works well (24/7, mission-critical). But it is really tough or even impossible to make changes or add new features. Scalability is often becoming an issue, already. And well, let’s not talk about cost. Mainframes cost millions.
Mainframe Offloading
Mainframe offloading means data is replicated to Kafka for further analytics and processing by other applications. Data continues to be written to the mainframe via the existing legacy applications:
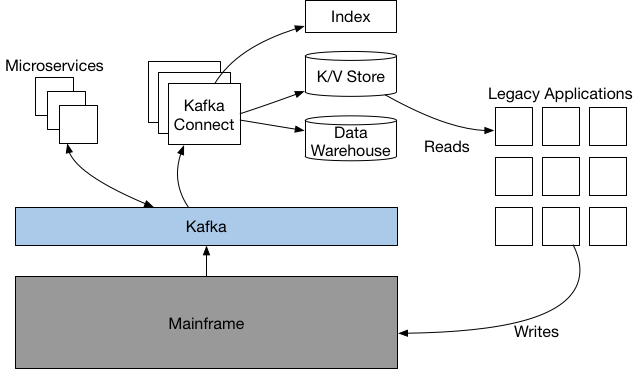
Offloading data is the easy part as you do not have to change the code on the mainframe. Therefore, the first project is often just about reading data.
Writing to the mainframe is much harder because the business logic on the mainframe must be understood to make changes. Therefore, many projects avoid this huge (and sometimes not solvable) challenge by keeping the writes as it is… This is not ideal, of course. You cannot add new features or changes to the existing application.
People are not able or do not want to take the risk to change it. There is no DevOps or CI/CD pipelines and no A/B testing infrastructure behind your mainframe, dear university graduates! 🙂
Mainframe Replacement
Everybody wants to replace Mainframes due to its technical limitations and cost. But enterprises cannot simply shut down the mainframe because of all the mission-critical business applications.
Therefore, COBOL, the main programming language for the mainframe is still widely used in applications to do large-scale batch and transaction processing jobs. Read the blog post ‘Brush up your COBOL: Why is a 60 year old language suddenly in demand?‘ for a nice ‘year 2020 introduction to COBOL’.
Enterprises have the following options:
Option 1: Continue to develop actively on the mainframe
Train or hire more (expensive) Cobol developers to extend and maintain your legacy applications. Well, this is where you want to go away from. If you forgot why: Cost, cost, cost. And technical limitations. I find it amazing how mainframes even support “modern technologies” such as Web Services. Mainframes do not stand still. Having said this, even if you use more modern technologies and standards, you are still running on the mainframe with all its drawbacks.
Option 2: Replace the Cobol code with a modern application using a migration and code generation tool
Various vendors provide tools which take COBOL code and automatically migrate it to generated source code in a modern programming language (typically Java). The new source code can be refactored and changed (as Java uses static typing so that any errors can be shown in the IDE and changes can be apply to all related dependencies in the code structure). This is the theory. The more complex your COBOL code is, the harder it gets to migrate it and the more custom coding is required for the migration (which results in the same problem the COBOL developer had on the mainframe: If you don’t understand the code routines, you cannot change it without risking errors, data loss or downtime in the new version of the application).
Option 3: Develop a new future-ready application with modern technologies to provide an open, flexible and scalable architecture
This is the ideal approach. Keep the old legacy mainframe running as long as needed. A migration is not a big bang. Replace use cases and functionality step-by-step. The new applications will have very different feature requirements anyway. Therefore, take a look at the Fintech and Insurtech companies. Starting green field has many advantages. The big drawback is high development and migration costs.
In reality, a mix of these three options can also happen. No matter what works for you, let’s now think how Apache Kafka fits into this story.
Domain-Driven Design for your Integration Layer
Kafka is not just a messaging system. It is an event streaming platform that provides storage capabities. In contrary to MQ systems or Web Service / API based architectures, Kafka really decouples producers and consumers:
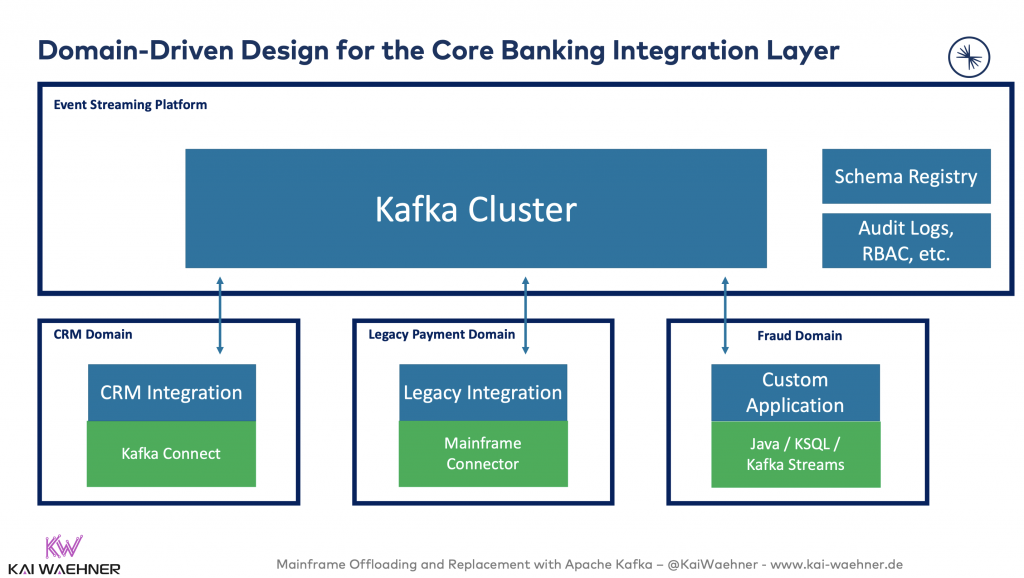
With Kafka and its Domain-driven Design, every application / service / microservice / database / “you-name-it” is completely independent and loosely coupled from each other. But scalable, highly available and reliable! The blog post “Apache Kafka, Microservices and Domain-Driven Design (DDD)” goes much deeper into this topic.
Sberbank, the biggest bank in Russia, is a great example for their domain-driven approach: Sberbank built their new core banking system on top of the Apache Kafka ecosystem. This infrastructure is open and scalable, but also ready for mission-critical payment use cases like instant-payment or fraud detection, but also for innovative applications like Chat Bots in customer service or Robo-advising for trading markets.
Why is this decoupling so important? Because the mainframe integration, migration and replacement is a (long!) journey…
Event Streaming Platform and Legacy Middleware
An Event Streaming Platform gives applications independence. No matter if an application uses a new modern technology or legacy, proprietary, monolithic components. Apache Kafka provides the freedom to tap into and manage shared data, no matter if the interface is real time messaging, a synchronous REST / SOAP web service, a file based system, a SQL or NoSQL database, a Data Warehouse, a data lake or anything else:
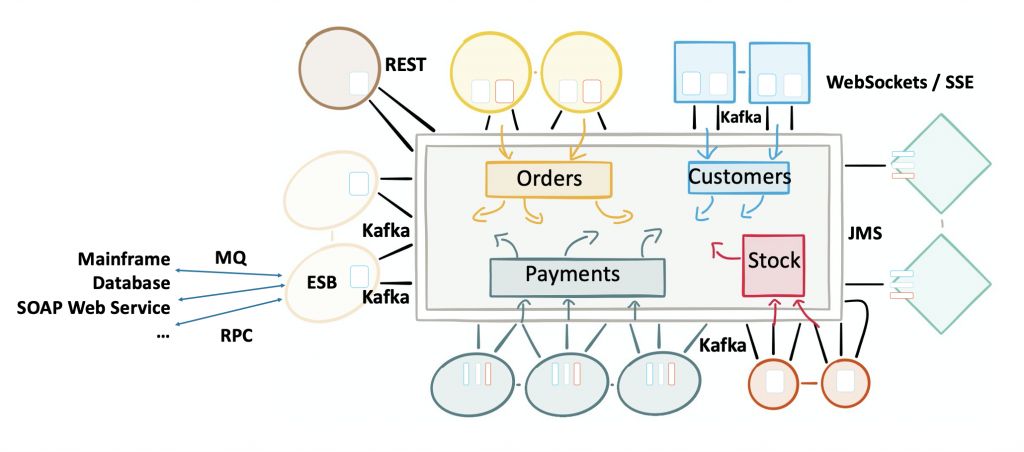
Apache Kafka as Integration Middleware
The Apache Kafka ecosystem is a highly scalable, reliable infrastructure and allows high throughput in real time. Kafka Connect provides integration with any modern or legacy system, be it Mainframe, IBM MQ, Oracle Database, CSV Files, Hadoop, Spark, Flink, TensorFlow, or anything else. More details here:
Kafka Ecosystem for Security and Data Governance
The Apache Kafka ecosystem provides additional capabilities. This is important as Kafka is not just used as messaging or ingestion layer, but a platform for your most mission-critical use cases. Remember the examples from banking and insurance industry I showed in the beginning of this blog post. These are just a few of many more mission-critical Kafka deployments across the world. Check past Kafka Summit video recordings and slides for many more mission-critical use cases and architectures.
I will not go into detail in this blog post, but the Apache Kafka ecosystem provides features for security and data governance like Schema Registry (+ Schema Evolution), Role Based Access Control (RBAC), Encryption (on message or field level), Audit Logs, Data Flow analytics tools, etc…
Mainframe Offloading and Replacement in the Next 5 Years
With all the theory in mind, let’s now take a look at a practical example. The following is a journey many enterprises walk through these days. Some enterprises are just in the beginning of this journey, while others already saved millions by offloading or even replacing the mainframe.
I will walk you through a realistic approach which takes ~5 years in this example (but this can easily take 10+ years depending on the complexity of your deployments and organization). The importance is quick wins and a successful step-by-step approach; no matter how long it takes.
Year 0: Direct Communication between App and Mainframe
Let’s get started. Here is again the current situation: Applications directly communicate with the mainframe.
Let’s reduce cost and dependencies between the mainframe and other applications.
Year 1: Kafka for Decoupling between Mainframe and App
Offloading data from the mainframe enables existing applications to consume the data from Kafka instead of creating high load and cost for direct mainframe access:
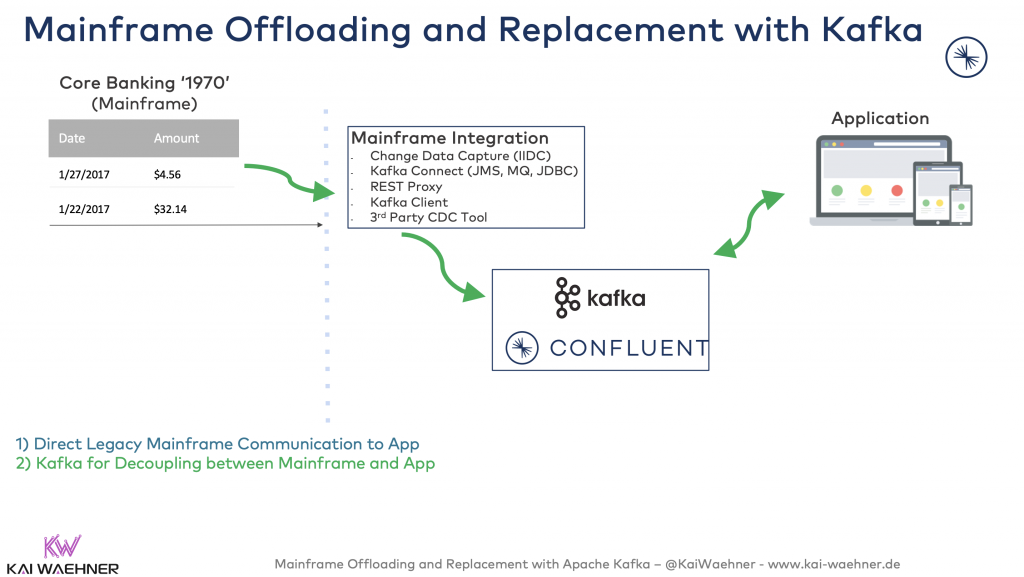
This saves a lot of MIPS (million instructions per second). MIPS is a way to measure the cost of computing on mainframes. Less MIPS, less cost.
After offloading the data from the mainframe, new applications can also consume the mainframe data from Kafka. No additional MIPS cost! This allows building new applications on the mainframe data. Gone is the time where developers cannot build new innovative applications because the MIPS cost was the main blocker to access the mainframe data.
Kafka can store the data as long as it needs to be stored. This might be just 60 minutes for one Kafka Topic for log analytics or 10 years for customer interactions for another Kafka Topic. With Tiered Storage for Kafka, you can even reduce costs and increase elasticity by separating processing from storage with a back-end storage like AWS S3. This discussion is out of scope of this article. Check out “Is Apache Kafka a Database?” for more details.
Change Data Capture (CDC) for Mainframe Offloading to Kafka
The most common option for mainframe offloading is Change Data Capture (CDC): Transaction log-based CDC pushes data changes (insert, update, delete) from the mainframe to Kafka. The advantages:
- Real time push updates to Kafka
- Eliminate disruptive full loads, i.e. minimize production impact
- Reduce MIPS consumption
- Integrate with any mainframe technology (DB2 Z/OS, VSAM, IMS/DB, CISC, etc.)
- Full support
On the first connection, the CDC tool reads a consistent snapshot of all of the tables that are whitelisted. When that snapshot is complete, the connector continuously streams the changes that were committed to the DB2 database for all whitelisted tables in capture mode. This generates corresponding insert, update and delete events. All of the events for each table are recorded in a separate Kafka topic, where they can be easily consumed by applications and services.
The big disadvantage of CDC is high licensing costs. Therefore, other integration options exist…
Integration Options for Kafka and Mainframe
While CDC is typically the preferred choice, there are more alternatives. Here are the integration options I have seen being discussed in the field for mainframe offloading:
- IBM InfoSphere Data Replication (IIDR) CDC solution for Mainframe
- 3rd Party commercial CDC solution (e.g. Attunity or HLR)
- Open-source CDC solution (e.g Debezium – but you still need an IIDC license, this is the same challenge as with Oracle and GoldenGate CDC)
- Create interface tables + Kafka Connect + JDBC connector
- IBM MQ interface + Kafka Connect’s IBM MQ connector
- Confluent REST Proxy and HTTP(S) calls from the mainframe
- Kafka Clients on the mainframe
Evaluate the trade-offs and make your decision. Requiring a fully supported solution often eliminates several options quickly 🙂 In my experience, most people use CDC with IIDR or a 3rd party tool, followed by IBM MQ. Other options are more theoretical in most cases.
Year 2 to 4: New Projects and Applications
Now it is time to build new applications:
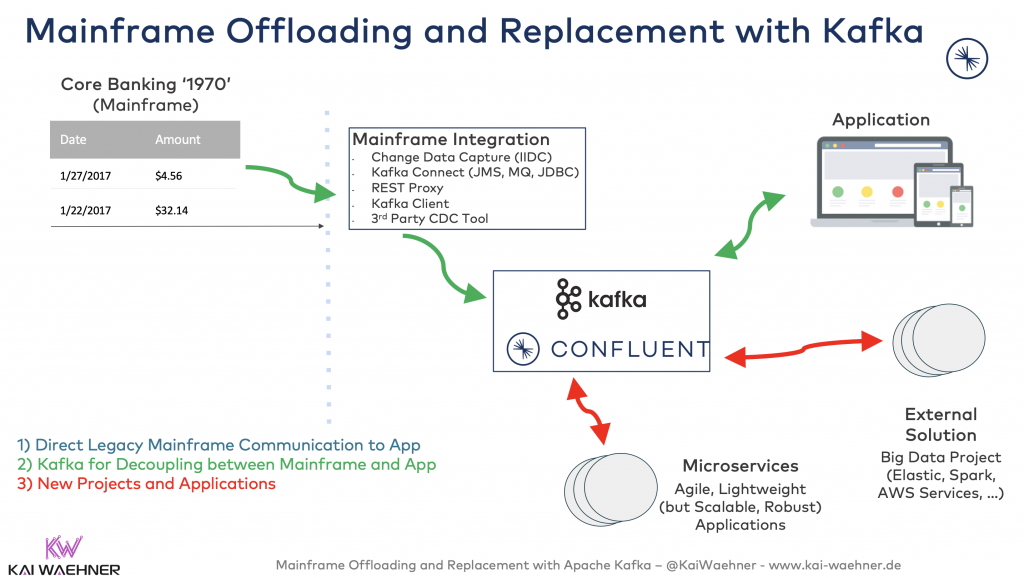
This can be agile, lightweight Microservices using any technology. Or this can be external solutions like a data lake or cloud service. Pick what you need. Your are flexible. The heart of your infrastructure allows this. It is open, flexible and scalable. Welcome to a new modern IT world! 🙂
Year 5: Mainframe Replacement
At some point, you might wonder: What about the old mainframe applications? Can we finally replace them (or at least some of them)? When the new application based on a modern technology is ready, switch over:
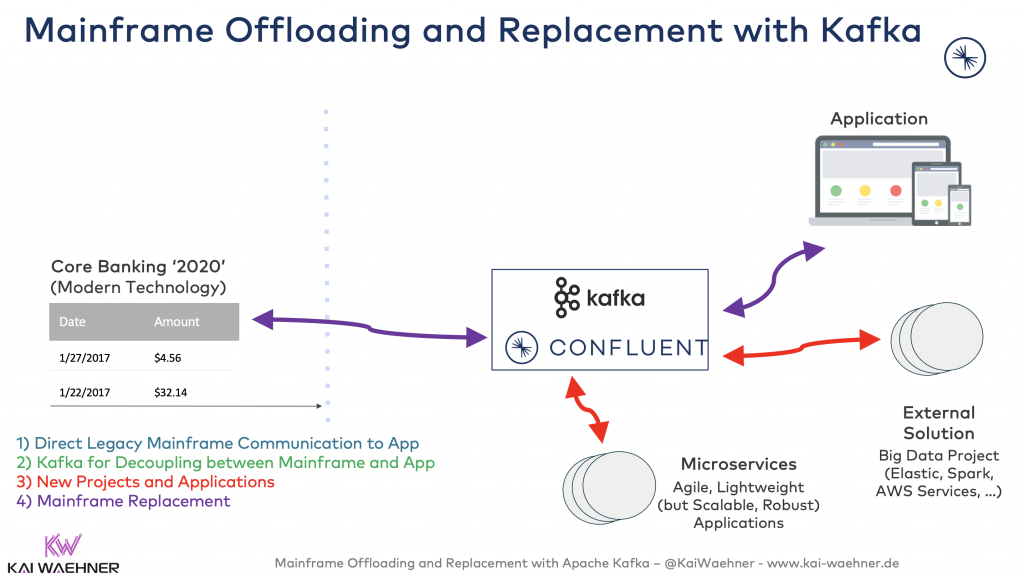
As this is a step-by-step approach, the risk is limited. First of all, the mainframe can keep running. If the new application does not work, switch back to the mainframe (which is still up-to-date as you did not stop inserting the updates into its database in parallel to the new application).
As soon as the new application is battle-tested and proven, the mainframe application can be shut down. The $$$ budgeted for the next mainframe renewal can be used for other innovative projects. Congratulations!
Mainframe Offloading and Replacement is a Journey… Kafka can Help!
Here is the big picture of our mainframe offloading and replacement story:
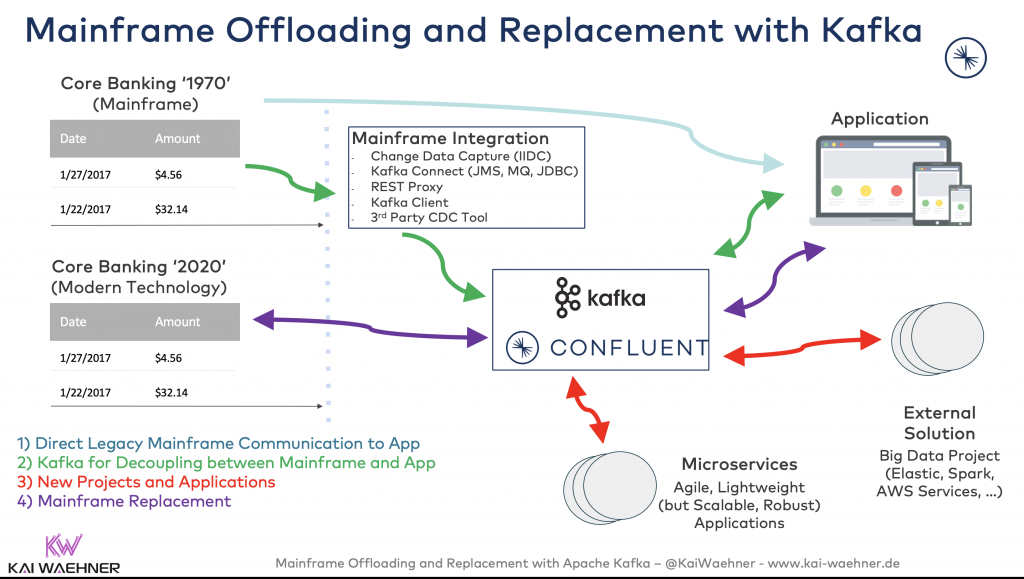
Hybrid Cloud Infrastructure with Apache Kafka and Mainframe
Remember the three phases I discussed earlier: Phase 1 – Cloud Adoption, Phase 2 – Hybrid Cloud, Phase 3 – Cloud-First Development. I did not tackle this in detail in this blog post. Having said this, Kafka is an ideal candidate for this journey. Therefore, this is a perfect combination for offloading and replacing mainframes in a hybrid and multi-cloud strategy. More details here:
Slides and Video Recording for Kafka and Mainframe Integration
Here are the slides:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
And the video walking you through the slides:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
What are your experiences with mainframe offloading and replacement? Did you or do you plan to use Apache Kafka and its ecosystem? What is your strategy? Let’s connect on LinkedIn and discuss! Stay informed about new blog posts by subscribing to my newsletter.




