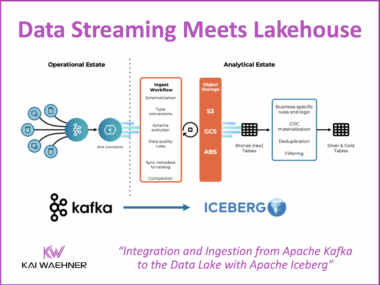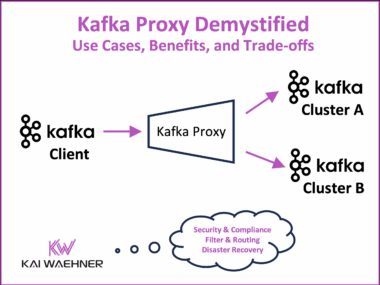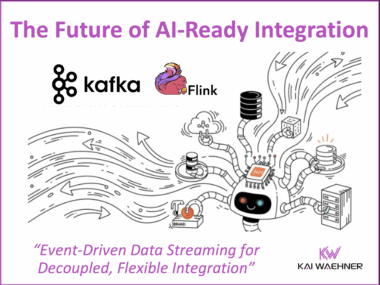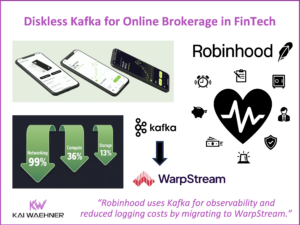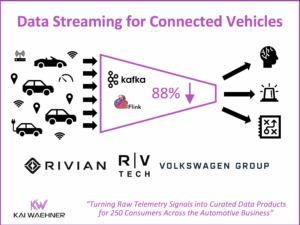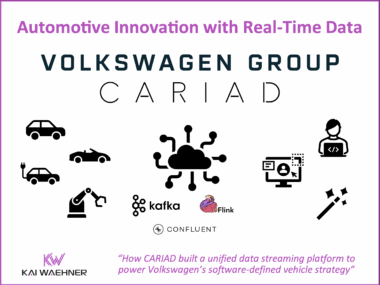
CARIAD’s Unified Data Platform: A Data Streaming Automotive Success Story Behind Volkswagen’s Software-Defined Vehicles
The automotive industry transforms rapidly. Cars are now software-defined vehicles (SDVs) that demand constant, real-time data flow. This post highlights the CARIAD success story inside the Volkswagen Group. CARIAD tackled data fragmentation. It built the Unified Data Ecosystem (UDE). Learn how Confluent’s data streaming platform, powered by Apache Kafka and Flink, serves as the central nervous system. This platform connects millions of vehicles and cloud services globally. The event-driven architecture helps CARIAD achieve faster development, meet compliance (like the EU Data Act), and reduce costs. The platform unlocks high-value use cases, such as predictive maintenance and AI-powered fleet management.