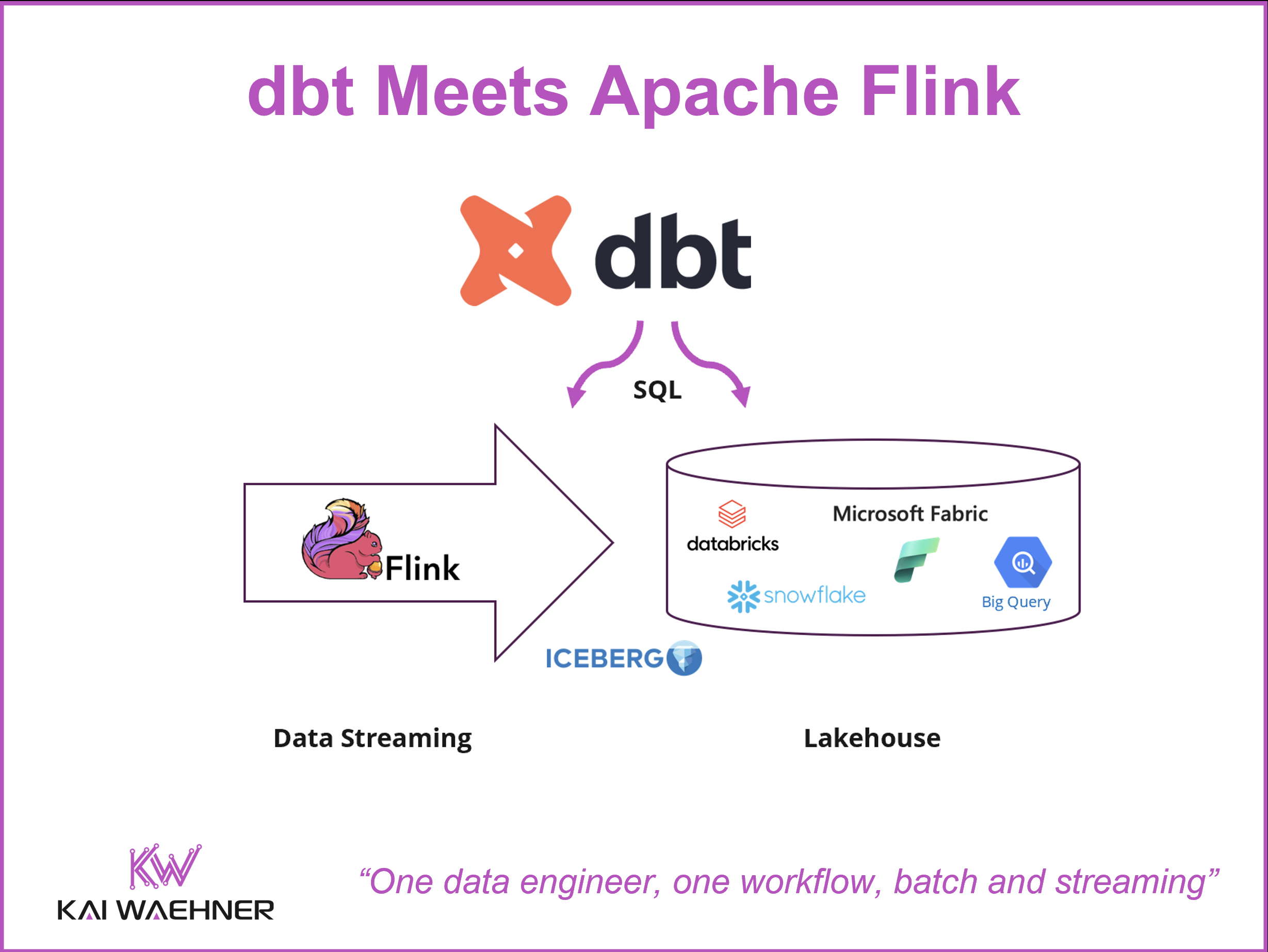
Adapter
Two toolchains, two skill sets, two CI/CD pipelines — that has been the reality for data engineers working across batch and streaming. dbt extending to

Two toolchains, two skill sets, two CI/CD pipelines — that has been the reality for data engineers working across batch and streaming. dbt extending to

Confluent, Databricks, and Snowflake are trusted by thousands of enterprises to power critical workloads—each with a distinct focus: real-time streaming, large-scale analytics, and governed data

In today’s data-driven world, understanding data at rest versus data in motion is crucial for businesses. Data streaming frameworks like Apache Kafka and Apache Flink

If you ask your favorite large language model, Microsoft Fabric appears to be the ultimate solution for any data challenge you can imagine. That’s also
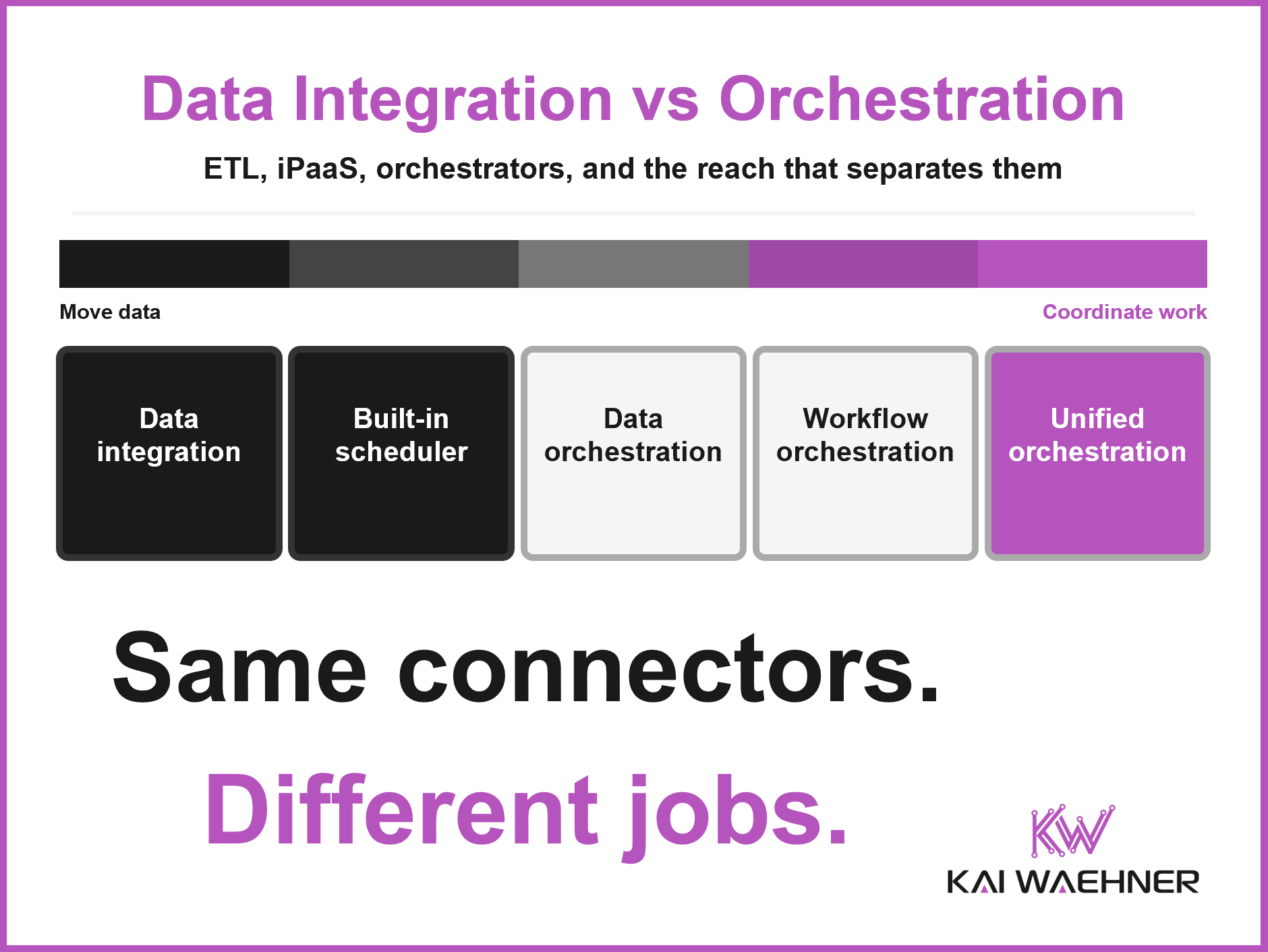
Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse.

Snowflake is a leading cloud data warehouse and transitions into a data cloud that enables various use cases. The major drawback of this evolution is
The integration between Apache Kafka and Snowflake is often cumbersome. Options include near real-time ingestion with a Kafka Connect connector, batch ingestion from large files,
Snowflake is a leading cloud-native data warehouse. Integration patterns include batch data integration, Zero ETL and near real-time data ingestion with Apache Kafka. This blog

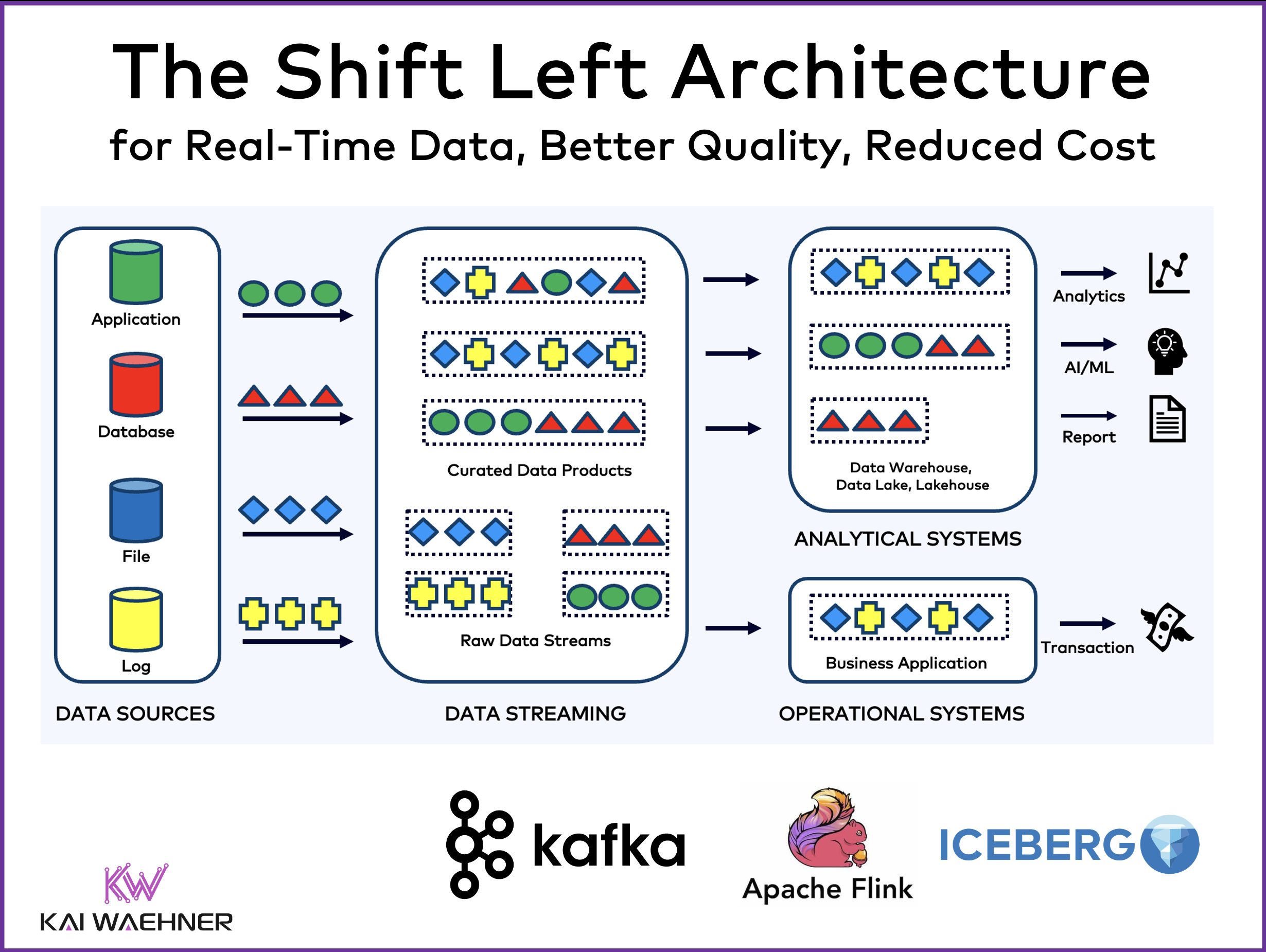
The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are

This blog post explores why software vendors (try to) introduce new solutions for Reverse ETL, when Reverse ETL is really needed, and how it fits




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information