
In today’s data-driven world, understanding data at rest versus data in motion is crucial for businesses. Data streaming frameworks like Apache Kafka and Apache Flink enable real-time data processing, offering quick insights and seamless system integration. They are ideal for applications that require immediate responses and handle transactional workloads. Meanwhile, lakehouses like Snowflake, Databricks, and Microsoft Fabric excel in long-term data storage and detailed analysis, perfect for reports and AI training. By leveraging both data streaming and lakehouse systems, businesses can effectively meet both short-term and long-term data needs. This blog post explores how these technologies complement each other in enterprise architecture.

This is part two of a blog series about Microsoft Fabric and its relation to other data platforms on the Azure cloud:
- What is Microsoft Fabric for Azure Cloud (Beyond the Buzz) and how it Competes with Snowflake and Databricks
- How Microsoft Fabric Lakehouse Complements Data Streaming (Apache Kafka, Flink, et al.)
- When to Choose Apache Kafka vs. Azure Event Hubs vs. Confluent Cloud for a Microsoft Fabric Lakehouse
Subscribe to my newsletter to get an email about a new blog post every few weeks.
Data at Rest (Lakehouse) vs. Data in Motion (Data Streaming)
Data streaming technologies like Apache Kafka and Apache Flink enable continuous data processing while the data is in motion in an event-driven architecture. Data streaming enables immediate insights and seamless integration of data across systems. Kafka provides a robust real-time messaging and persistence platform, while Flink excels in low-latency stream processing, making them ideal for dynamic, stateful applications. A data streaming platform supports operational/transactional and analytical use cases.
Data lakes and data warehouses store data at rest before processing the data. The platforms are optimized for batch processing and long-term analytics, including AI/ML use cases such as model training. Some components provide near real-time capabilities, e.g. data ingestion or dashboards. Data lakes offer scalable, flexible storage for raw data, and data warehouses provide structured, high-performance environments for business intelligence and reporting, complementing the real-time capabilities of streaming technologies. Most leading data platforms provide a unified combination of data lake and data warehouse called lakehouse. Lakehouses are almost exclusively used for analytical workloads as they typically lack the SLAs and tight latency required for operational/transactional use cases.
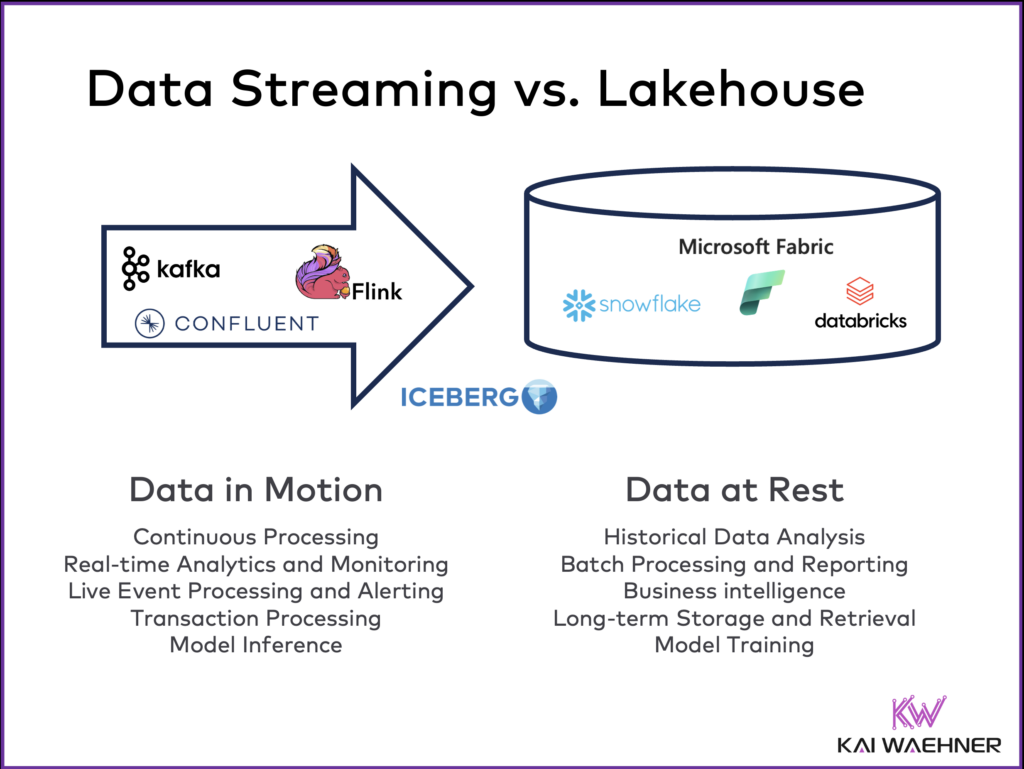
Data streaming and lakehouses are complementary, with some overlaps but different sweet spots. If you want to learn more, check out these articles:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Snowflake Data Integration Options for Apache Kafka (including Iceberg)
I also created a short ten minute video explaining the above concepts:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Let’s explore why data streaming and a lakehouse like Microsoft Fabric are complementary (with a few overlaps). I explained in the first blog of this series what Microsoft Fabric is. To understand the differences, it is important to understand what a data streaming platform really is.
Data Streaming in an Event-driven Architecture with Apache Kafka and Flink
There is a lot of confusion in the market. For instance, some folks still compare Apache Kafka to a message broker like RabbitMQ or IBM MQ. I mainly focus on Apache Kafka and Apache Flink as these are the de facto standards for data streaming across industries. Before talking about technologies and solutions, we need to start with the concept of an event-driven architecture as the foundation of data streaming.
Event-driven Architecture for Operational and Analytical Workloads
In today’s digital world, getting real-time data quickly is more important than ever. Traditional methods that process data in batches or via request-response APIs often cannot keep up when you need immediate insights.
Event-driven architecture offers a different approach by focusing on handling events – like transactions or user actions – as they happen. One of the key benefits of an event-driven architecture is its ability to decouple systems, meaning that different parts of a system can work independently. This makes it easier to scale and adapt to changes. An event-driven architecture excels in handling both operational and analytical workloads.
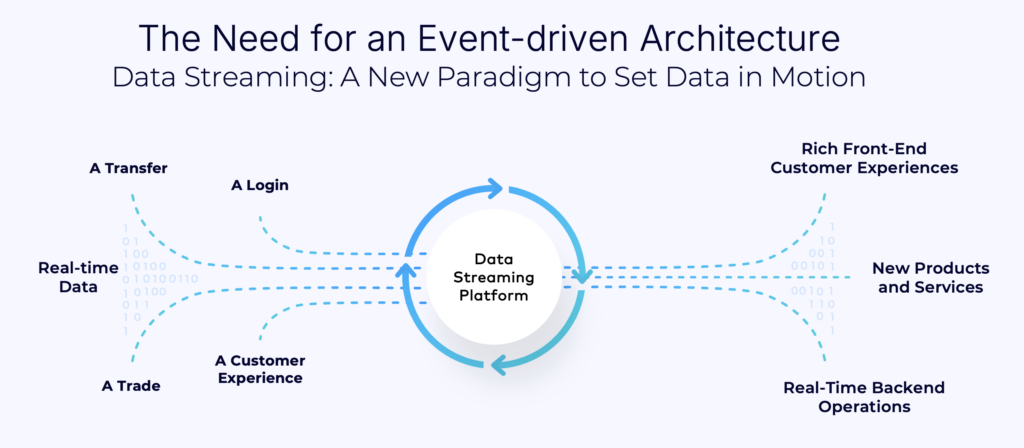
For operational tasks, the event-driven architecture enables real-time data processing, automating processes, enhancing customer experiences, and boosting efficiency. In e-commerce, for example, an event-driven system can instantly update inventory, trigger marketing campaigns, and detect fraud.
On the analytical side, the event-driven architecture allows organizations to derive insights from data as it flows, enabling real-time analytics and trend identification without the delays of batch processing. This is invaluable in sectors like finance and healthcare, where timely insights are crucial.
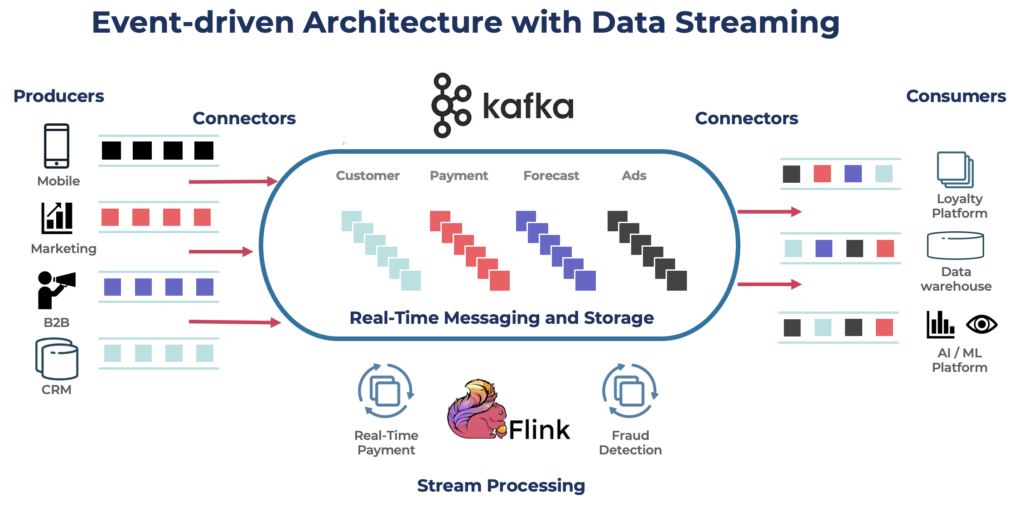
Building an event-driven architecture with data streaming technologies like Apache Kafka and Apache Flink enhances its potential. These platforms provide the infrastructure for high-throughput, low-latency data streams, enabling scalable and resilient event-driven systems.
Apache Kafka – The De Facto Standard for Event-driven Messaging and Integration
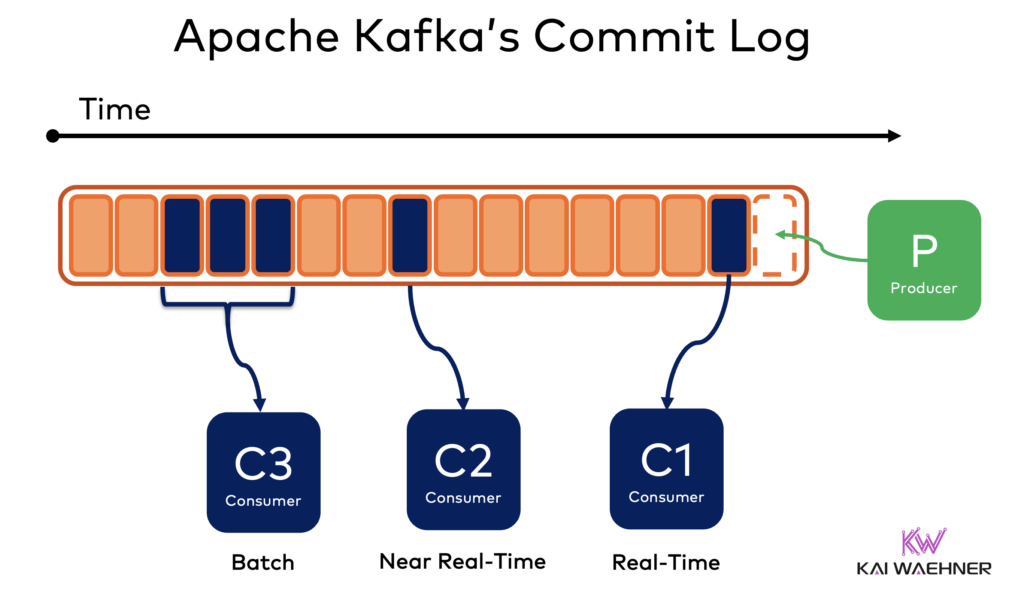
Apache Kafka has become the go-to platform for event-driven messaging and integration, transforming how organizations manage data in motion. Developed by LinkedIn and open-sourced, Kafka is a distributed streaming platform adept at handling real-time data feeds. Over 150,000 organizations use Kafka in the meantime.
Kafka’s architecture is based on a distributed commit log, ensuring data durability and consistency. It decouples data producers and consumers, allowing for flexible and scalable data architectures. Producers publish data to topics, and consumers subscribe independently, facilitating system evolution.
Beyond messaging, Kafka serves as a robust integration platform, connecting diverse systems and enabling seamless data flow. Its ecosystem of connectors allows integration with databases, cloud services, and legacy systems. This helps organizations in modernizing their data infrastructure step-by-step.
Kafka’s stream processing capabilities, through Kafka Streams and integration with Apache Flink, further enhance the value of the streaming data pipelines. Kafka Streams allows real-time data processing within Kafka to enable complex transformations and enrichments, driving data-driven innovation.
Apache Flink – The De Facto Standard for Stream Processing
Apache Flink stands out as the leading framework for stream processing. It offers a versatile platform for streaming ETL and stateful business applications. Flink processes data streams with low latency and high throughput, suitable for diverse use cases.
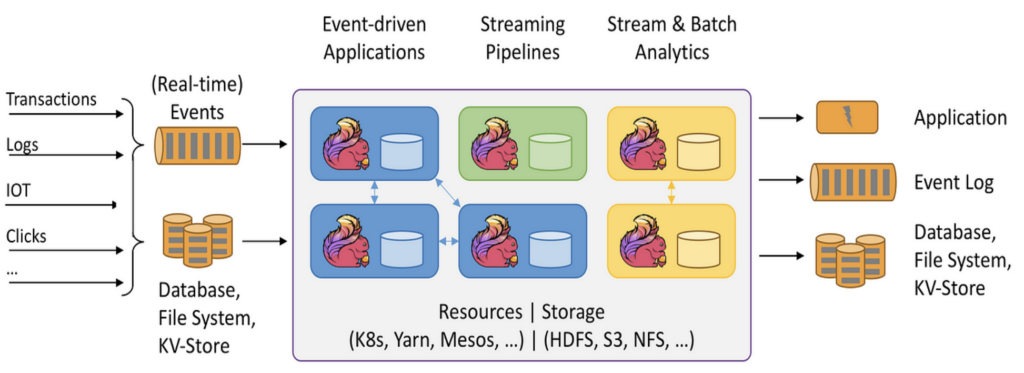
Flink provides a unified programming model for batch and stream processing that allows developers to use the same API for real-time transactional or analytical batch tasks. This flexibility is a significant advantage as it enables varied data processing without separate tools.
A key feature of Flink is its stateful stream processing. This is crucial for maintaining state across events in real-time applications. Flink’s state management ensures accurate processing in complex scenarios. In contrast to many other stream processing solutions, Flink can do stateful processing even at an extreme scale (i.e., with a throughput of gigabytes per second).
Flink’s event time processing capabilities handle out-of-order or delayed events and ensure consistent results. Developers can define windows and triggers based on event timestamps, accommodating late-arriving data.
Apache Flink supports multiple programming languages, including Java, Python, and SQL, offering developers the flexibility to use their preferred language for building stream processing applications. This is a key differentiator to other stream processing engines, such as Kafka Streams or KSQL.
Kafka and Flink are a “Match Made in Heaven” for Data Streaming
The integration of Flink with Apache Kafka enhances its capabilities. Kafka serves as a reliable data source for Flink to enable seamless real-time data ingestion and processing. With Kafka’s persistent commit log, you can travel back in time and replay historical data in guaranteed ordering for analytical use cases. This combination supports high-volume, low-latency data pipelines, unlocking transactional real-time scenarios and batch analytics.
In summary, Apache Flink’s robust stream processing, combined with Apache Kafka, offers a powerful solution for organizations seeking to leverage real-time data. Whether for operational tasks, real-time analytics, or complex event processing (CEP), Flink provides the necessary flexibility and performance for data-driven innovation.
Microsoft Fabric and Data Streaming (Kafka, Flink): Complementary Forces, NOT Competitors
In the growing landscape of data management, it’s crucial to understand the complementary roles of Microsoft Fabric and data streaming technologies. While some may perceive these technologies as competitors, they actually serve distinct yet interconnected purposes that enhance an organization’s data strategy. And keep in mind that Microsoft Fabric is not just an offering for Azure cloud. Hybrid edge scenarios in the IoT space are perfect for Microsoft Fabric and data streaming together.
Microsoft Fabric’s Streaming Ingestion: A Common Feature Among Lakehouses
Microsoft Fabric, like other modern lakehouse platforms such as Snowflake and Databricks, offers streaming ingestion capabilities. This feature is essential for handling near real-time data flows. It allows organizations to capture and process data as it arrives in the lakehouse. However, it’s important to distinguish between operational and analytical workloads when considering the role of streaming ingestion.
Operational workloads benefit from the immediacy of streaming data, enabling real-time decision-making and process automation. In contrast, analytical workloads often require data to be stored at rest for in-depth analysis and reporting. Microsoft Fabric’s architecture focuses on streaming ingestion into robust storage solutions for analytical purposes.
The Fabric Real Time Intelligence Hub: Understanding Its Capabilities and Limitations
The integration of streaming ingestion into Microsoft Fabric is part of its Real Time Intelligence Hub, which aims to provide a comprehensive platform for managing real-time data. However, beyond the marketing and buzz around Fabric Real Time Intelligence Hub, it’s important to note that it doesn’t operate in true real-time.
Instead, Fabric’s “Real Time Intelligence Hub” uses Spark Streaming jobs to manipulate data, which can introduce some latency. And the infrastructure is not meant for critical SLAs that are required by operational / transactional systems. Additionally, the ingestion process is throttled when using Power BI and other batch analytics tools via an API gateway with a Kafka client.
Microsoft is strong in introducing new names for products or feature for Fabric that are actually just a new brand of existing services. If you find new terms such as “eventhouse” or “event streams feature in the Microsoft Fabric Real-Time Intelligence”, make sure to evaluate if this is really a new component or just some Fabric marketing.
Therefore, despite some overlapping with a data streaming platform, the collaboration between Microsoft Fabric and data streaming vendors like Confluent (Kafka, Flink) underscores the complementary nature of these platforms. By leveraging the strengths of both, organizations can build a robust data infrastructure that supports real-time operations and comprehensive analytics.
In conclusion, Microsoft Fabric and data streaming technologies such as Kafka and Flink are not competitors but complementary tools that, when used together, can significantly enhance an organization’s ability to manage and analyze data. By understanding the distinct roles each plays, businesses can create a more agile and responsive data strategy that meets both operational and analytical needs.
Enterprise Architecture with Data Streaming like Kafka / Flink and Lakehouse(s) like Microsoft Fabric
In the modern enterprise architecture landscape, data streaming and lakehouse platforms are pivotal in creating a robust and flexible data ecosystem. Data streaming technologies enable continuous data ingestion and processing for operational and analytical use cases.
Lakehouse platforms, like Microsoft Fabric, Snowflake and Databricks, provide a unified architecture that combines the best of data lakes and data warehouses, offering scalable storage and advanced analytics capabilities.
Together, these technologies empower businesses to handle both operational and analytical workloads efficiently, breaking down data silos and fostering a data-driven culture. By integrating data streaming with lakehouse architectures, enterprises can achieve seamless data flow and comprehensive insights across their operations.
Reverse ETL is an Anti-Pattern
Reverse ETL is the process of moving data from a data store at rest back into operational systems. It is often considered an anti-pattern in modern data architecture. This approach can lead to data inconsistencies, increased complexity, and higher maintenance costs, as it essentially reverses the natural flow of data in motion. Do NOT store data in MIcrosoft Fabric Lakehouse just to reverse it later into other operational systems!
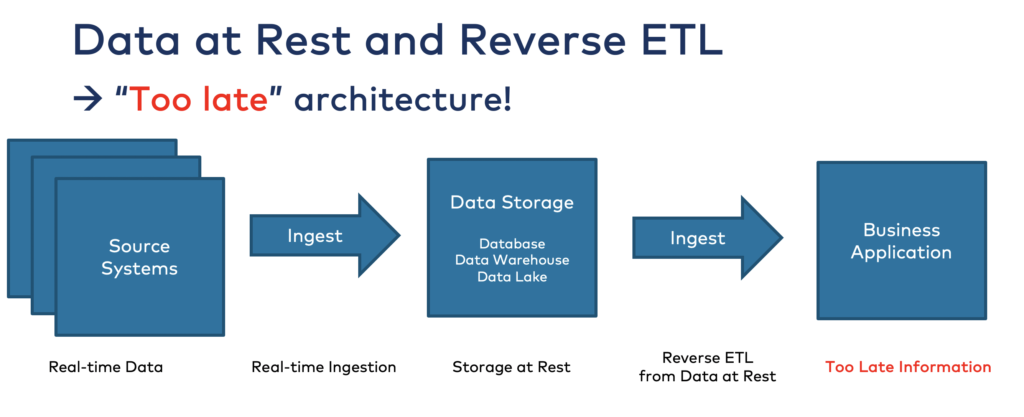
Instead of relying on reverse ETL, organizations should focus on building real-time data pipelines that enable direct integration between data sources and operational systems. By leveraging an event-driven architecture and data streaming technologies, businesses can ensure that data is consistently updated and available where it’s needed most. This approach not only simplifies data management, but also enhances the accuracy and timeliness of insights.
Apache Iceberg as the De Facto Standard for an Open Table Format – Store Once, Analyze with any Tool
Apache Iceberg has emerged as the de facto standard for an open table format. It offers a opportunity for storing data once in an object store like Amazon S3 and analyzing data across various tools. With its ability to handle large-scale datasets and support ACID transactions, Iceberg provides a reliable and efficient way to manage data in a lakehouse environment.
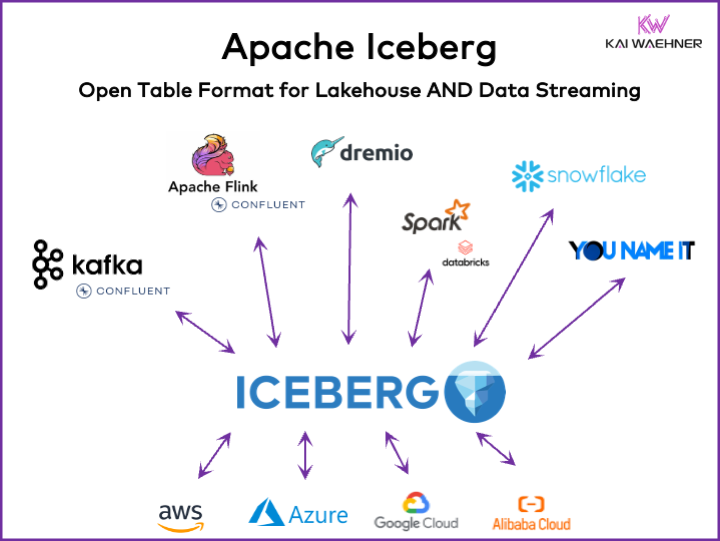
Organizations can use their preferred analytics and processing tools without being locked into a specific vendor. This flexibility is crucial for businesses looking to maximize their data investments and adapt to changing technological landscapes. By adopting Apache Iceberg together with data streaming, enterprises can ensure data consistency and accessibility across all business units to drive better data-quality, insights and decision-making.
Shift Left Architecture to Support Operational and Analytical Workloads with an Event-driven Architecture
Traditionally, many organizations use data streaming with Kafka as a dumb pipeline to ingest all raw data into a data lake. The consequences are high compute cost for multiple (re-)processing of the raw data, inconsistencies across business units, and slow time to market for new applications.
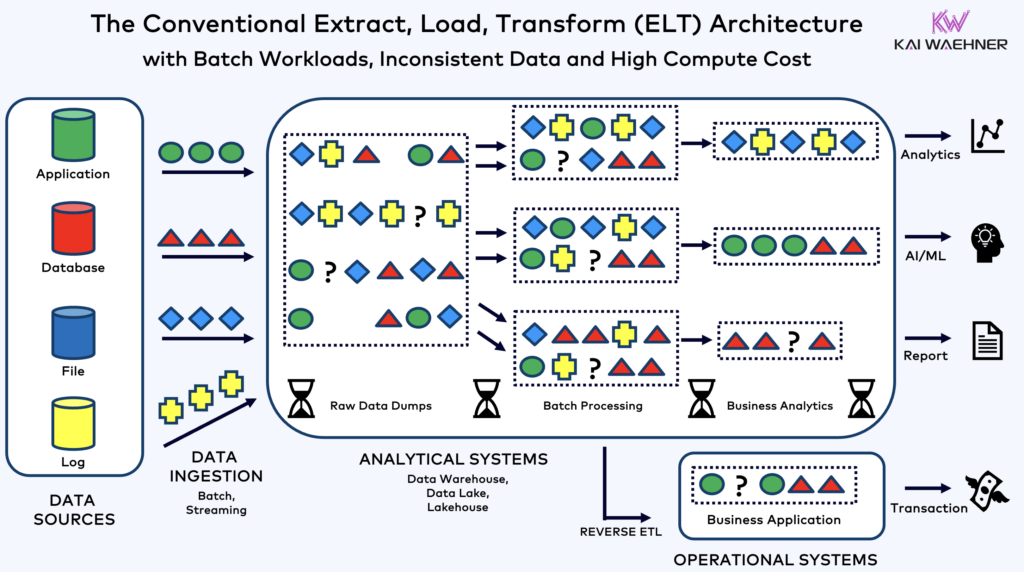
The Shift Left Architecture is a forward-thinking approach that integrates operational and analytical workloads within an event-driven architecture. By shifting data processing closer to the source, this architecture enables real-time data ingestion and analysis, improving data quality for lakehouse ingestion, reducing latency and improving responsiveness.
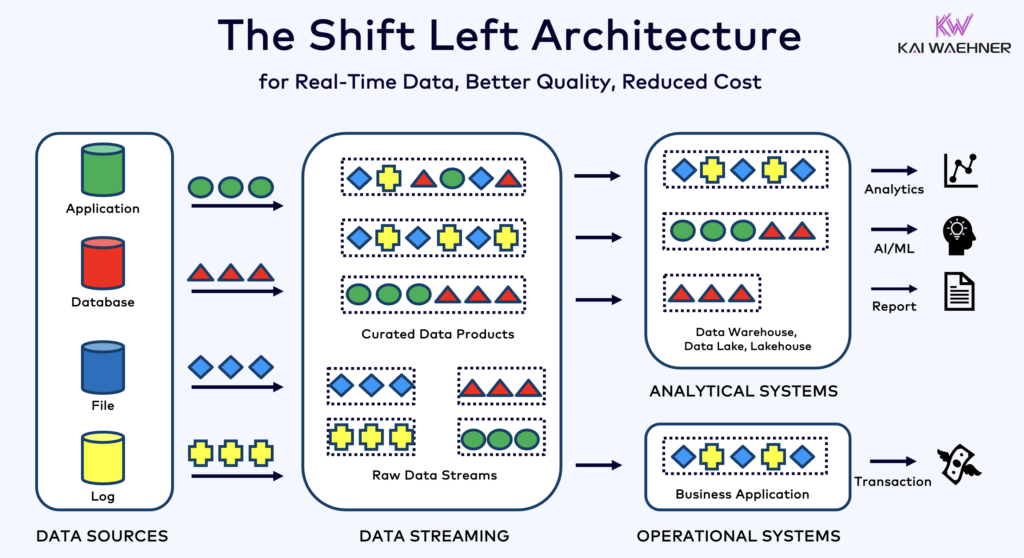
Event-driven architectures, powered by technologies like Apache Kafka and Flink, facilitate the seamless flow and processing of data across systems. Shift Left ensures that both operational and analytical needs are met. This approach not only enhances the agility of data-driven applications, but also supports continuous improvement and innovation. By adopting a Shift Left Architecture, organizations can streamline their data processes, improve efficiency, and gain a competitive edge in the market.
Example: Confluent (Data Streaming) + Microsoft Fabric (Lakehouse) + Snowflake (Another Lakehouse)
An example of integrating data streaming and lakehouse technologies is the combination of Confluent, Microsoft Fabric, and Snowflake.
Confluent, built on Apache Kafka and Flink, provides a robust platform for real-time data streaming, enabling organizations to integrate with operational and analytical workloads.
Microsoft Fabric and Snowflake, both lakehouse platforms, offer scalable storage and advanced analytics capabilities to allow businesses performing in-depth analysis and reporting on historical data, near real-time analytics and AI model training.
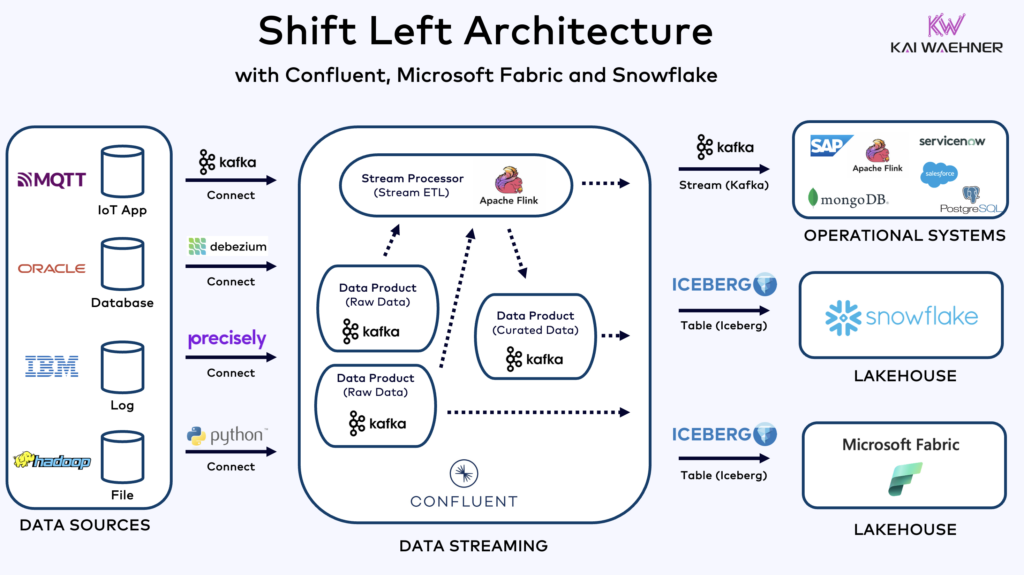
Apache Iceberg enables storing data once and connects any analytical engine to the data, including lakehouses such as Microsoft Fabric or Snowflake, and unified batch and streaming frameworks such as Apache Flink. Iceberg improves the overall data quality for data sharing, reduces storage cost and enables a much faster rollout of new analytical applications.
By leveraging Confluent for data streaming and integrating it with Microsoft Fabric and Snowflake, organizations can create a comprehensive data architecture that supports both real-time operations and long-term analytics. This synergy not only enhances data accessibility and consistency but also empowers businesses to make data-driven decisions with confidence.
Microsoft Fabric Lakehouse + Data Streaming (Kafka, Flink) = Match Made in Heaven
In conclusion, the synergy between Microsoft Fabric and data streaming technologies like Apache Kafka and Apache Flink creates a powerful combination for modern data management. While Microsoft Fabric excels in providing robust analytics and storage capabilities, data streaming platforms offer real-time data processing and integration, ensuring that businesses can respond swiftly to operational demands.
By leveraging both technologies together, organizations can build a comprehensive data architecture that supports both immediate and long-term needs, enhancing their ability to make informed, data-driven decisions. This complementary relationship not only breaks down data silos, but also fosters a more agile and responsive data strategy. As businesses continue to navigate the complexities of data management, understanding and using the strengths of both Microsoft Fabric and data streaming with data streaming vendors like Confluent will be key to achieving a competitive edge.
The Shift Left Architecture, when paired with Apache Iceberg’s open table format, simplifies the integration of data streaming with one or more lakehouses. This combination enhances data quality for all data consumers and significantly reduces overall storage costs.
In part three of this blog series, I will dig deeper into the data streaming alternatives. When to choose open source frameworks such as Apache Kafka and Flink, a leading data streaming platform such as Confluent, or a native Azure service like Event Hubs. Primer: The trade-offs are huge. Do a proper evaluation BEFORE choosing your data streaming solution.
How do you see the combination of a lakehouse like Microsoft Fabric with data streaming? Do you already use both together? And what is your strategy for other data lakes and data warehouses you already have in your enterprise architecture, such as Databricks or Snowflake? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
