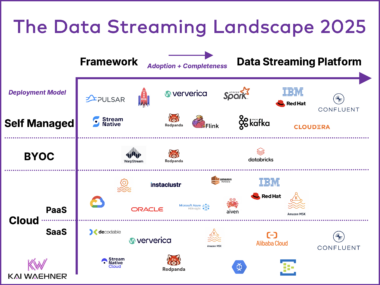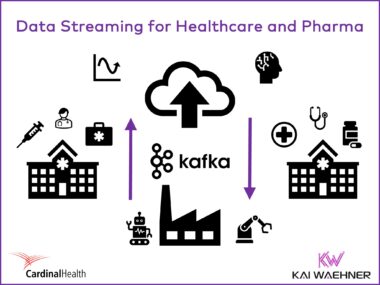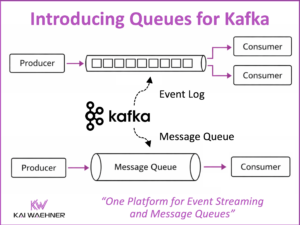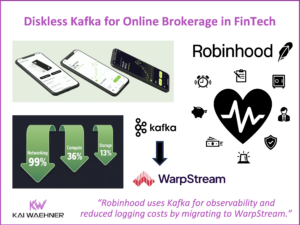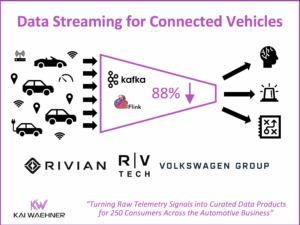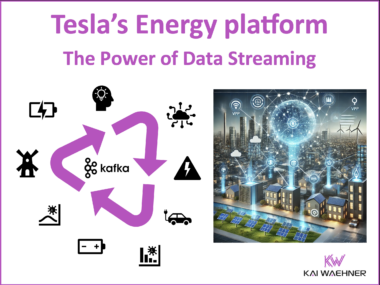
Tesla Energy Platform – The Power of Data Streaming with Apache Kafka
Tesla’s Virtual Power Plant (VPP) turns thousands of home batteries, solar panels, and energy storage systems into a coordinated, intelligent energy network. By leveraging Apache Kafka for event streaming and WebSockets for real-time IoT connectivity, Tesla enables instant energy redistribution, dynamic grid balancing, and automated market participation. This event-driven architecture ensures millisecond-level decision-making, allowing homeowners to optimize energy usage and utilities to stabilize power grids. Tesla’s approach highlights how real-time data streaming and intelligent automation are reshaping the future of decentralized, resilient, and sustainable energy systems.