Running Apache Flink on a mainframe sounds odd at first. A modern stream processing engine on a platform most people call legacy? But take a closer look. It is not only possible. It might be a smart move for some of the largest financial institutions in the world. This post explores why some enterprises want Apache Flink on the mainframe, how it could work, and whether it is a brilliant innovation or a technical detour.

Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including several success stories around IT modernization.
Disclaimer: The views and opinions expressed in this blog are strictly my own and do not necessarily reflect the official policy or position of my employer.
Mainframes Will Still Matter in 203X!
A few months ago, I wrote about integrating Apache Kafka with mainframe systems. The blog covered various real-world examples across industries.
The key message: Mainframes are still in use. In many organizations, they are not going away. They remain a central part of IT strategy, especially in banking, insurance, and public sector.
But they are not just legacy systems. Modern mainframes such as the IBM z17 offer the latest Telum II processor and support up to 64 terabytes of system memory. The z17 enables very large in‑memory workloads and faster processing for analytics and real‑time use cases. These systems also integrate on‑chip AI acceleration and optional AI‑focused hardware to support machine learning and real‑time decisions directly where mission‑critical data resides, while running modern Linux environments and container platforms.
Some companies are still on the mainframe because they cannot easily migrate. But many others do not want to move away. Instead, they modernize around the mainframe.
Apache Kafka and Flink play a key role in this journey. They enable a real-time data foundation that connects core systems with modern applications across environments. In future hybrid cloud strategies, this becomes even more critical. Kafka acts as the central nervous system, delivering the right data and context at the right time between on-prem mainframes and cloud-based AI services, including agentic AI and large language models.
An event-driven architecture with hybrid streaming replication ensures business-critical decisions are made on fresh, reliable, and contextual information.
Mainframe Migration Has Not Happened
Ask any architect or CTO in banking. Mainframe migration has been on the roadmap for over two decades. Full replacement of core systems is still rare.
However, it is important to distinguish between migration and offloading.
Mainframe migration means shutting down mainframe workloads entirely and moving all applications and data to a new platform. There are many reasons:
- Risk is too high
- Organizational resistance is strong
- Mainframe skills are still needed but hard to find
- Systems are complex and deeply integrated
- These applications run reliably and perform well
Mainframe offloading, on the other hand, is much more common. It means moving selected workloads, queries, or processing tasks off the mainframe to more flexible and scalable platforms. This reduces load and cost on the mainframe while enabling innovation elsewhere.
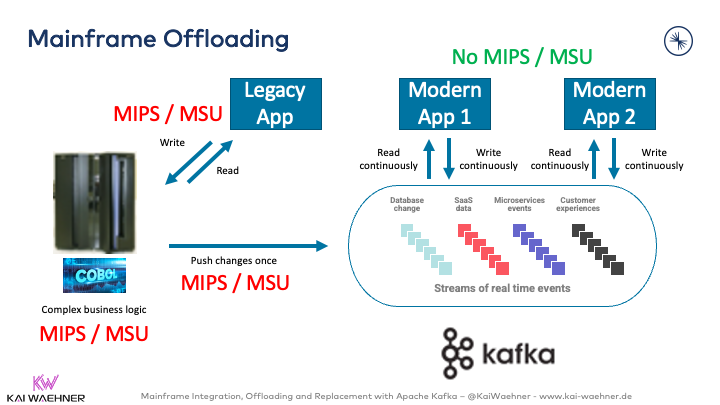
I have shared several real-world examples of offloading in action, using Kafka, IBM MQ and Change Data Capture (CDC) tools like IBM IIDR or Precisely to synchronize and replicate data between mainframe systems to the cloud or distributed infrastructure in real-time: Mainframe Offloading and Integration Examples.
Because of this, many firms choose mainframe integration and a slow lift and shift leveraging the Strangler Fit design pattern over migration. Kafka is already helping. Flink is the next step.
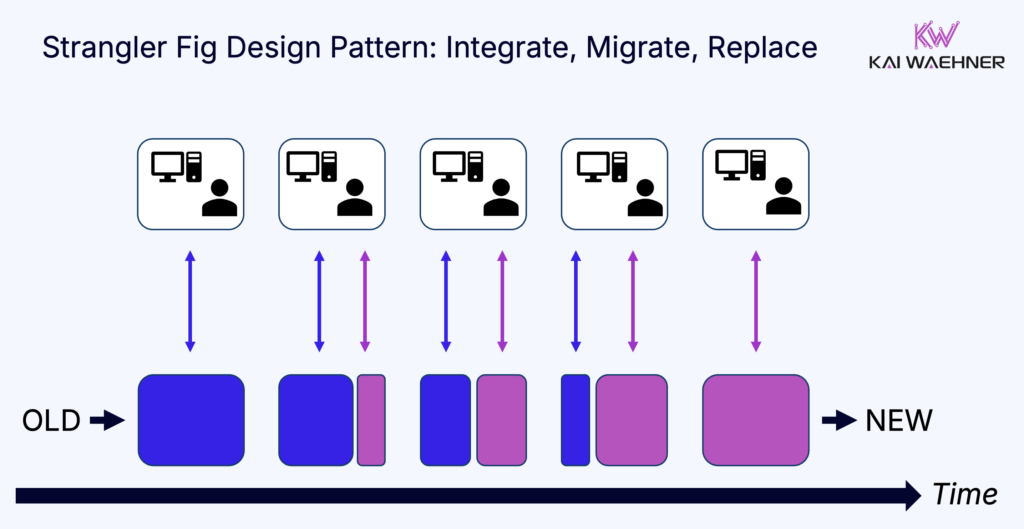
Apache Flink Meets the Mainframe: Unlikely Combo, Real Potential
At first glance, Apache Flink and the mainframe seem like technologies from two different worlds. But combining them can unlock surprising value.
What is Apache Flink?
Apache Flink is the leading open source stream processing engine. It is designed to process high volumes of data continuously and in real time, rather than in batches. Flink is widely used to support use cases like fraud detection, customer personalization, operational monitoring, and data transformation at scale.
Many of the largest tech companies and digital natives rely on Flink to process billions of events per day with low latency and high throughput. It supports both event streaming and batch workloads, but its true strength lies in real-time use cases.
Here is an example for continuous with stream processing leveraging Apache Flink together with OpenAI for Generative AI in real-time:
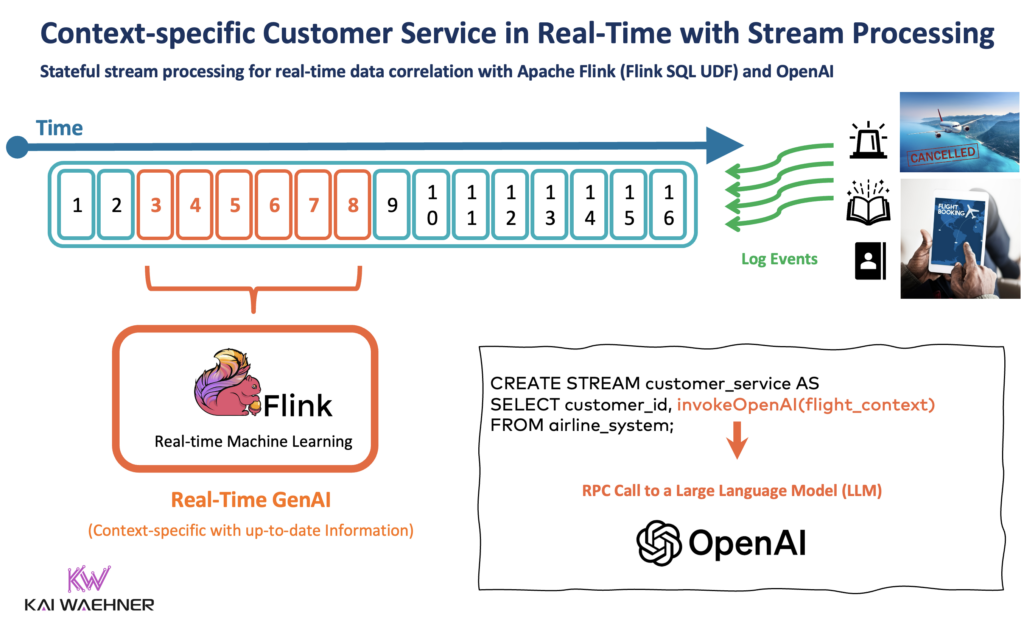
Flink is built for modern environments. It runs natively on Kubernetes, integrates with Apache Kafka for real-time data ingestion, and is commonly deployed in public cloud, private cloud, or hybrid architectures. This makes it an ideal fit for enterprises looking to build fast, intelligent applications on fresh and contextual data.
How to Run Apache Flink on the Mainframe?
Yes, Apache Flink can run on the mainframe. In fact, it already does.
I have already seen this deployed in a real-world environment. A large global financial institution is preparing to invest massively to expand its use of Apache Flink. Running Flink on IBM LinuxONE is a central part of that strategy. This is NOT a lab experiment, but a production-focused initiative.
This bank already uses Kafka and Flink in production. Now they want to move Flink compute workloads onto the mainframe. The reason is simple. They already have unused compute on LinuxONE. Running Flink there is cheaper and easier to scale (for some companies) than scaling out other systems.
The architecture is modern. IBM LinuxONE runs OpenShift. IBM LinuxONE is a high-performance, enterprise-grade server built on IBM Z architecture. It is designed to run Linux workloads with extreme reliability, scalability, and security. Unlike traditional mainframes focused on COBOL and legacy apps, LinuxONE is optimized for modern Linux applications.
Flink is deployed in containers inside OpenShift’s Kubernetes infrastructure, just like in any other cloud or data center. From a technical perspective, you need to build Docker images for the s390x architecture to run Apache Flink on IBM LinuxONE. In addition, components like RocksDB, which is used as a state backend in Flink, must be compiled for s390x to ensure full functionality.
Confluent supports the deployment of Flink on the Linux / s390x CPU architecture for IBM Mainframe.
Why Put Apache Flink on the IBM Mainframe?
This is a very valid question!
Nobody would buy a mainframe just to run Flink on it. However, this approach offers several benefits for organizations that already own and operate mainframe infrastructure:
- Available compute resources on the mainframe.
- Consume data directly from mainframe sources (such as IBM MQ or other integration interfaces) and process it directly on the mainframe; or consume data from external sources such as a Kafka cluster running on x86 infrastructure, enabling flexible integration across hybrid environments.
- Lower total cost of ownership (TCO) regarding hardware and license cost compared to adding new external x86 servers and bi-directional integration pipelines.
- Simplified operations within a single, familiar environment.
- Benefit from IBM actively promoting LinuxONE and driving more workloads onto the platform.
Mainframes are not only still alive. They are growing. IBM’s infrastructure business, which includes the mainframe, is doing very well. In Q3 2025, IBM reported 3.6 billion dollars in revenue for the infrastructure segment. That is 17 percent growth. IBM Z alone grew 61 percent. In Q2 2025, infrastructure revenue was 4.14 billion dollars, beating expectations by a wide margin.
This is not legacy tech in decline. It is a platform in transformation.
A New Chapter for Stream Processing and Mainframes
Apache Flink running on the mainframe may sound unusual at first, but it reflects a broader shift in how enterprises think about modernization. The mainframe is not just a legacy system to replace. IBM Mainframe can fit hybrid cloud strategies, especially in highly regulated industries like banking and insurance.
Apache Flink brings real-time intelligence. The mainframe brings performance, reliability, and unmatched security. Together, they offer a powerful combination for building fast, contextual, and mission-critical applications; without abandoning existing infrastructure.
With Kafka as the backbone and Flink as the engine for real-time processing, organizations can connect mainframe systems with cloud innovation, including advanced AI workloads. This is not just about preserving the past. It is about extending and reusing trusted systems to meet the demands of the future.
Enterprises that embrace this model can reduce risk, increase agility, and unlock new value from the heart of their operations.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including several success stories around IT modernization.