Generative AI (GenAI) enables advanced AI use cases and innovation but also changes how the enterprise architecture looks like. Large Language Models (LLM), Vector Databases, and Retrieval Augmentation Generation (RAG) require new data integration patterns and data engineering best practices. Data streaming with Apache Kafka and Apache Flink play a key role to ingest and curate incoming data sets in real-time at scale, connecting various databases and analytics platforms, and decouple independent business units and data products. This blog post explores possible architectures, examples, and trade-offs between event streaming and traditional request-response APIs and databases.

Use Cases for Apache Kafka and GenAI
Generative AI (GenAI) is the next-generation AI engine for natural language processing (NLP), image generation, code optimization, and other tasks. It helps many projects in the real world for service desk automation, customer conversation with a chatbot, content moderation in social networks, and many other use cases.
Apache Kafka became the predominant orchestration layer in these machine learning platforms for integrating various data sources, processing at scale, and real-time model inference.
Data streaming with Kafka already powers many GenAI infrastructures and software products. Very different scenarios are possible:
- Data streaming as data fabric for the entire machine learning infrastructure
- Model scoring with stream processing for real-time predictions and generation of content
- Generation of streaming data pipelines with input text, speech, or images
- Real-time online training of large language models
I explored these use cases, including real-world examples like Expedia, BMW and Tinder, in the blog post “Apache Kafka as Mission Critical Data Fabric for GenAI“.
The following looks at a concrete architecture for the combination of large language models (LLM), retrieval augmented generation (RAG) with vector databases and semantic search, and data streaming with Apache Kafka and Flink.
Why Generative AI Differs from Traditional Machine Learning Architectures?
Machine Learning (ML) allows computers to find hidden insights without being programmed where to look. This is called model training, a batch process analyzing big data sets. The output is a binary file, the analytic model.
Applications apply these models to new incoming events to make predictions. This is called model scoring, and can happen in real time or batch by embedding the model into an application or by doing a request-response API call to a model server (that deployed the model).
However, LLMs and GenAI have different requirements and patterns compared to traditional ML processes, as my former colleague Michael Drogalis explained in two simple, clear diagrams.
Traditional Predictive Machine Learning with Complex Data Engineering
Predictive Artificial Intelligence makes predictions. Purpose-built models. Offline training. That is how we did machine learning for the last decade or so.
In traditional ML, most of the data engineering work happens at model creation time. A lot of expertise and efforts are required for feature engineering and model training:
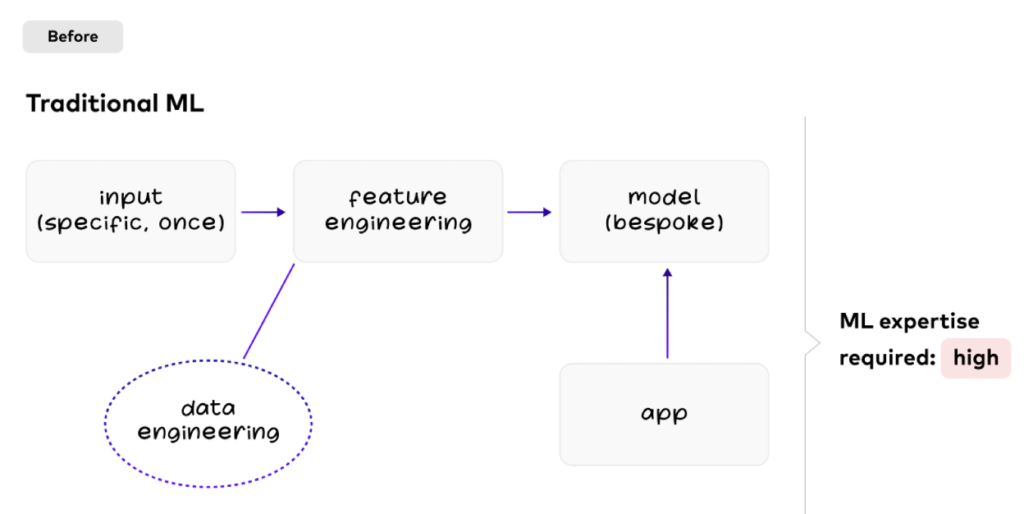
New use cases require a new model built by the data engineers and data scientists.
The Democratization of AI with Generative AI using Large Language Models (LLM)
Generative Artificial Intelligence (GenAI) creates content. Reusable models. In-context learning.
But with large language models, data engineering happens with every query. Different applications re-use the same model:
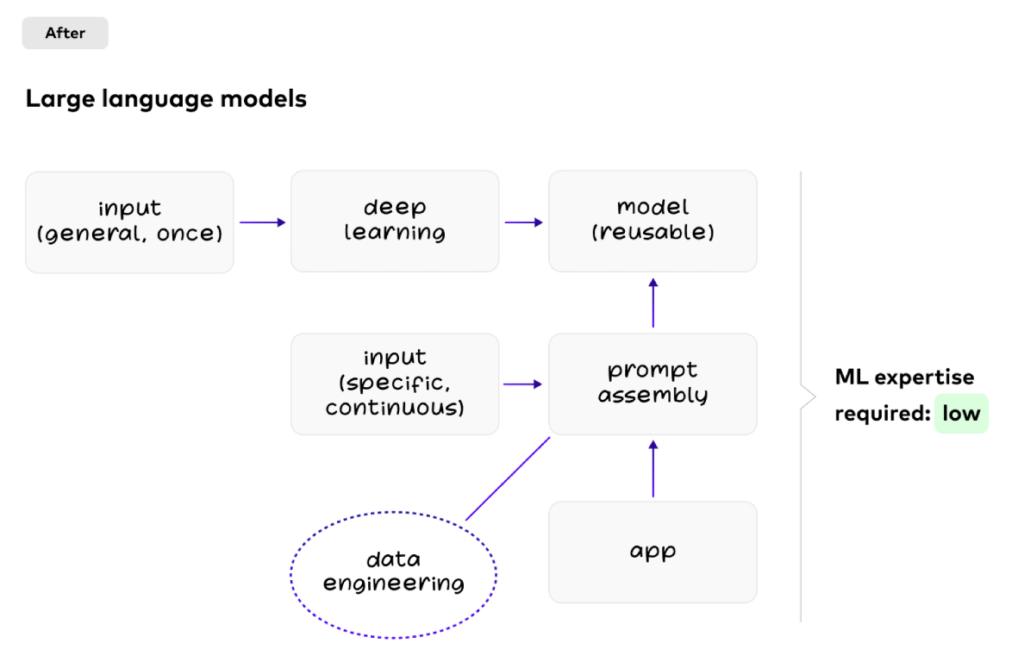
Challenges of Large Language Models for GenAI Use Cases
Large Language Models (LLM) are reusable. That enables democratization of AI, as not every team needs AI expertise. Instead, low AI expertise suffices to use existing LLMs.
However, a few huge trade-offs of LLMs exist:
- Expensive training: LLMs like ChatGPT cost millions of dollars in compute resources (this does not include the required expertise to build the model)
- Static data: LLMs are “frozen in time” meaning the model does not have up-to-date information.
- Lack of domain knowledge: LLMs usually learn from public data sets. Hence, data engineers scrape the worldwide web and feed it into the model training. However, enterprises need to use the LMM in their own context to provide business value.
- Stupidity: LLMs are not intelligent like a human. For instance, ChatGPT cannot even count the number of words in a sentence you prompt to it.
These challenges create so-called hallucination…
Avoiding Hallucination to Generate Reliable Answers
Hallucination, i.e. best guess answers, is the consequence; and the LLM does not tell you it is making things up. Hallucination is a phenomenon where the AI model generates content that is not based on real data or information, but creates entirely fictional or unrealistic outputs. Hallucinations can occur when a generative model, such as a text or image generator, generates content that is not coherent, factual, or relevant to the input data or context. These hallucinations can manifest as text, images, or other types of content that seem to be plausible but are entirely fabricated by the model.
Hallucinations can be problematic in generative AI because they can lead to the generation of misleading or false information.
For these reasons, a new design pattern emerged for Generative AI: Retrieval Augmented Generation (RAG). Let’s first look at this new best practice, and then explore why data streaming with technologies like Apache Kafka and Flink is a fundamental requirement for GenAI enterprise architectures.
Semantic Search and Retrieval Augmented Generation (RAG)
Many GenAI-enabled applications follow the design pattern of Retrieval Augmented Generation (RAG) to combine the LLM with accurate and up-to-date context. The team behind Pinecone, a fully managed vector database, has a great explanation using this diagram:
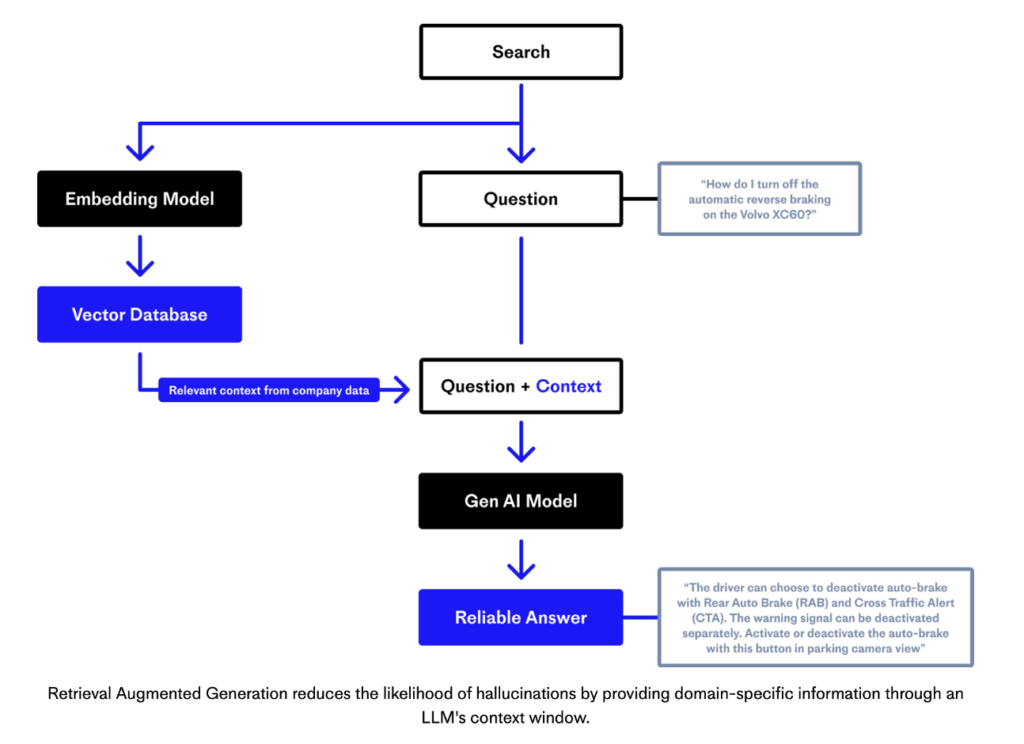
At a high level, RAG is typically two separate steps. The first is a data augmentation step where disparate (often unstructured) operational data is chunked and then embeddings are created using an embedding model. The embeddings are indexed into a vector database. The vector database is a tool for enabling semantic search to find relevant context for prompts that do not require exact keyword matching.
Second comes the inference step, where the GenAI model receives the question and context to generate a reliable answer (without hallucination). RAG does not update embeddings, but retrieves relevant information to send to the LLM along with the prompt.
Vector Databases for Semantic Search with Embeddings
A vector database, also known as a vector storage or vector index, is a type of database that is specifically designed to store and retrieve vector data efficiently. In this context, vector data refers to collections of numerical vectors, which can represent a wide range of data types, such as embeddings of text, images, audio, or any other structured or unstructured data. Vector databases are useful in applications related to machine learning, data retrieval, recommendation systems, similarity search, and more.
Vector databases excel at performing similarity searches, often called semantic search. They can quickly find vectors that are similar or close to a given query vector based on various similarity metrics, such as cosine similarity or Euclidean distance.
Vector database is not (necessarily) a separate database category. Gradient Flow explains in its best practices for Retrieval Augmented Generation:
“Vector search is no longer limited to vector databases. Many data management systems – including PostgreSQL – now support vector search. Depending on your specific application, you might find a system that meets your specific needs. Is near real-time or streaming a priority? Check Rockset’s offering. Are you already using a knowledge graph? Neo4j’s support for vector search means your RAG results will be easier to explain and visualize.”
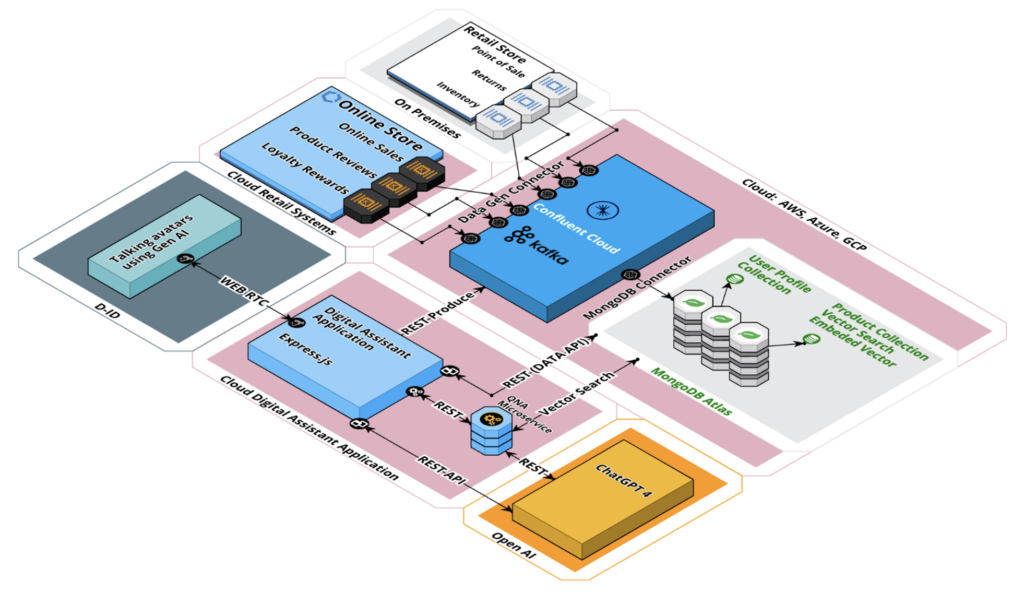
For another concrete example, look at MongoDB’s tutorial for “Building Generative AI Applications Using MongoDB: Harnessing the Power of Atlas Vector Search and Open Source Models“. There are various options for combining a vector database for GenAI use cases with Apache Kafka. The following is a possible architecture in an event-driven world.
Event-driven Architecture: Data Streaming + Vector DB + LLM
Event-driven applications can make both steps of Retrieval Augment Generation (RAG), data augmentation and model inference, more effectively implemented. Data Streaming with Apache Kafka and Apache Flink enables consistent synchronization of data at any scale (in real-time, if the application or database can handle it) and data curation (= streaming ETL).
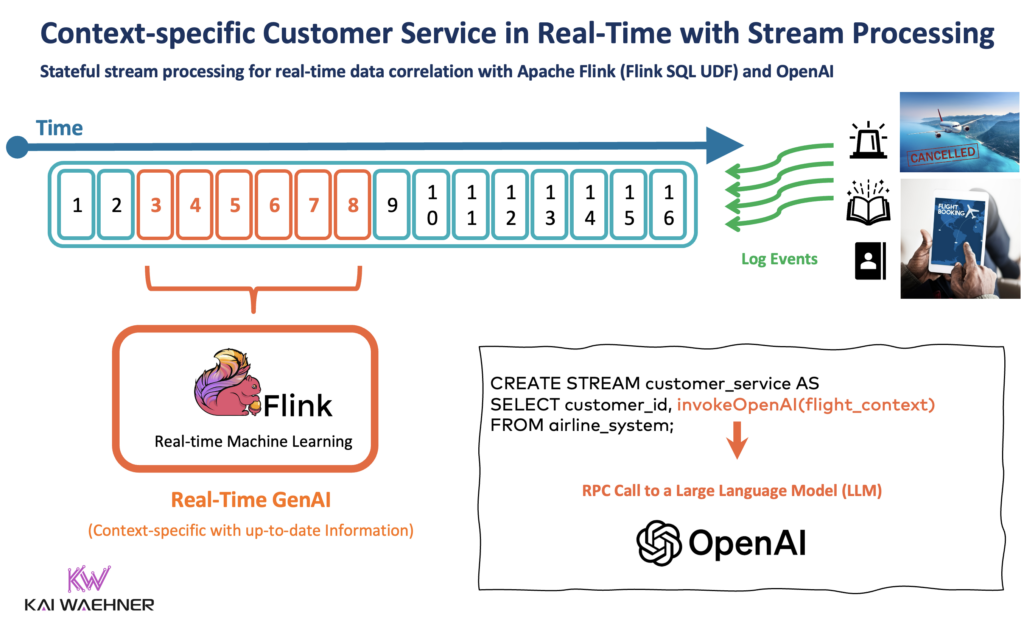
The following diagram shows an enterprise architecture leveraging event-driven data streaming for data ingestion and processing across the entire GenAI pipeline:
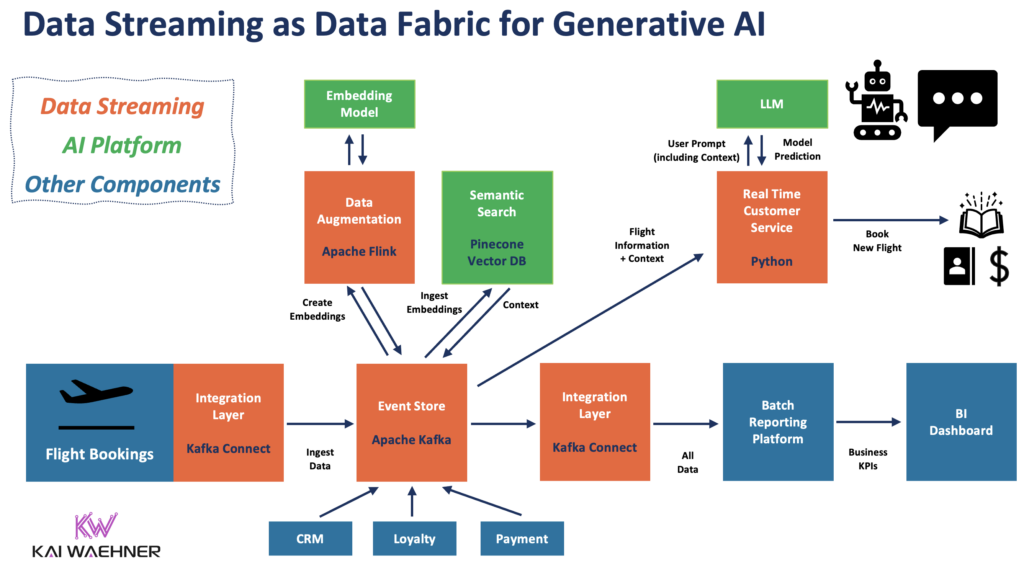
This example uses data streaming to ingest flight bookings and changes in real-time into Kafka’s event store for later processing with GenAI technologies. Flink preprocesses the data before it is calling an embedding model to generate embeddings for the vector database. In parallel, a real-time customer service application built with Python consumes all relevant contextual data (e.g., flight data, customer data, embeddings, etc.) to prompt the large language model. The LLM creates a reliable prediction, e.g. a recommendation to rebook a passenger to another flight.
In most enterprise scenarios, all the processing operates behind the enterprise firewall for security and data privacy reasons. The LLM can even be integrated with transactional systems, like the booking engine, to execute the rebooking and feed the outcome into relevant applications and databases.
Request-Response with API vs. Event-driven Data Streaming
In an ideal world, everything is event-based and streaming data. The real-world is different. Hence, API calls with request-response with HTTP/REST or SQL are totally fine in some parts of the enterprise architecture. As Kafka truly decouples systems, each application chooses its own communication paradigm and processing speed. Therefore, it is important to understand the Trade-offs between HTTP/REST API and Apache Kafka.
When to use Request-Response with Apache Kafka? – this decision is often made on trade-offs like latency, decoupling, or security. However, with large LLMs, the situation changes. As an LLM is very expensive to train, the reusability of existing LLMs is crucial. And embedding an LLM into a Kafka Streams or Flink application makes little sense in contrary to other models built with algorithms like decision trees, clustering, or even small neural networks.
Similarly, augmentation models are usually integrated via an RPC/API call. By embedding it into the Kafka Streams microservice or Flink job, the augmentation model becomes tightly coupled. And experts host many of them today because operating and optimizing them is not trivial.
Solutions hosting LLMs and augmentations models typically only provide an RPC interface like HTTP. This will probably change in the future as request-response is an anti-pattern for streaming data. An excellent example of the evolution of model servers is Seldon; providing a Kafka-native interface in the meantime. Read more about request-response vs. streaming model serving in the article Streaming Machine Learning with Kafka-native Model Deployment.
Direct Integration between an LLM and the Rest of the Enterprise?
While writing this article, OpenAI announced GPTs to create custom versions of ChatGPT that combine instructions, extra knowledge, and any combination of skills. For enterprise usage, the most interesting capability is that developers can connect OpenAI’s GPTs to the real world, i.e. other software applications, databases, and cloud services:
“In addition to using our built-in capabilities, you can also define custom actions by making one or more APIs available to the GPT. Like plugins, actions allow GPTs to integrate external data or interact with the real-world. Connect GPTs to databases, plug them into emails, or make them your shopping assistant. For example, you could integrate a travel listings database, connect a user’s email inbox, or facilitate e-commerce orders.”
The trade-offs using direct integration are tight coupling and point-to-point communication. If you already use Kafka, you understand the value of domain-driven design with true decoupling.
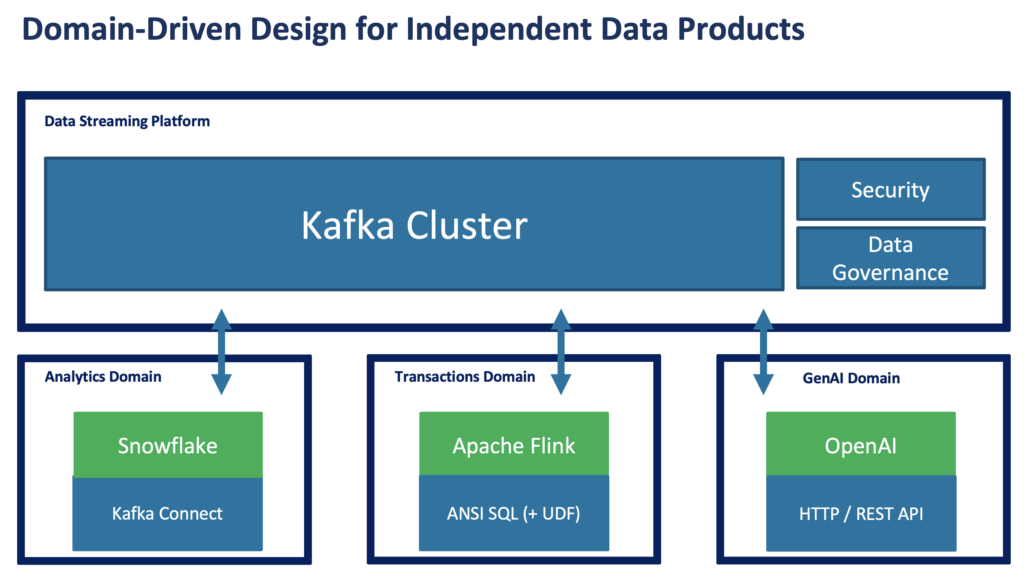
For more details about the importance and value of true decoupling in a microservice or data mesh architecture, check out these two articles to learn the difference between tight coupling with traditional middleware and decoupled data products with event-based data streaming:
- Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies?
- Why Data Streaming differs from Data Integration with integration Platform as a Service (iPaaS) Solutions
Last but not least: Public GenAI APIs and LLMs have a weak security and governance strategy. As AI data needs emerge and the number of point-to-point integrations increase, data access, lineage, and security challenges escalate.