Time flies… I joined Confluent seven years ago when Apache Kafka was mainly used by a few tech giants and the company had ~100 employees. This blog post explores my data streaming journey, including Kafka becoming a de facto standard for over 100,000 organizations, Confluent doing an IPO on the NASDAQ stock exchange, 5000+ customers adopting a data streaming platform, and emerging new design approaches and technologies like data mesh, GenAI, and Apache Flink. I look at the past, present and future of my personal data streaming journey. Both, from the evolution of technology trends and the journey as a Confluent employee that started in a Silicon Valley startup and is now part of a global software and cloud company.

PAST: Apache Kafka is pretty much unknown outside of Silicon Valley in 2017
When I joined Confluent in 2017, most people did not know about Apache Kafka. Confluent was in the early stage with ~100 employees.
Tech: Big data with Hadoop and Spark as “game changer”; Kafka only the ingestion layer
- Massive adoption of open source (beyond Linux)
- Companies moved from batch to real-time because real-time data beats slow data in almost all use cases across industries
- Adoption of machine learning for improving existing business processes and innovation
- From the Enterprise Service Bus (ESB) – called iPaaS in the cloud today – to more cloud-native middleware, i.e., Apache Kafka (many Kafka projects today are integration projects)
- Kafka being complementary to other data platforms, including data warehouse, data lake, analytics engines, etc.
What I did not see coming:
- The massive transition to the public cloud
- Apache Kafka being an event store for out-of-the-box capabilities like true decoupling of applications (what is the foundation and de facto standard for event-based microservices and data mesh today) and replayability of historical events in guaranteed ordering with timestamps
- Generative AI (GenAI) as a specific pillar of AI / ML (did anyone see this coming seven years ago?)
Company: Confluent is a silicon valley startup with ~100 people making Kafka enterprise-ready
Working in an international overlay role for Confluent…


PRESENT: Everyone knows Kafka (and Confluent); most companies use it already in 2024
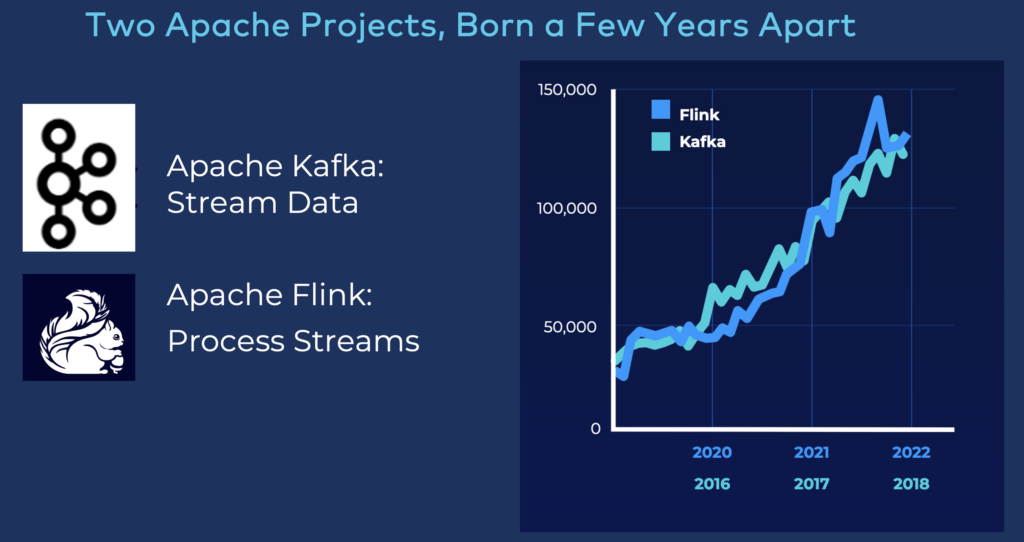
Apache Kafka is used in most organizations in 2024. Many enterprises are still in the early stage of the adoption curve and are building some streaming data pipelines. However, several companies, not just in Silicon Valley but worldwide and across industries, already matured and leverage stream processing with Kafka Streams or Apache Flink for advanced and critical use cases like fraud detection, context-specific customer personalization or predictive maintenance.
Tech: Apache Kafka is the de facto standard for data streaming
- All major cloud providers provide Kafka as a service (AWS, Azure, GCP, Alibaba).
- Many of the largest traditional software players include a Kafka product (including IBM, Oracle, and many more).
- Established data companies support Kafka and/or Flink, like Confluent, Cloudera, Red Hat, Ververica, etc.
- New startups emerge, including Redpanda, WarpStream, Decodable, and so on.
Data Streaming Landscape (vs. Data Lake, Data Warehouse and Lakehouse)
The current “Data Streaming Landscape 2024” provides a much more detailed overview. There will probably be some consolidation in the market. But it is great to see such an adoption and growth in the data streaming market.
I also published a blog series recently exploring how data streaming changes the view on Snowflake (and cloud data platforms in general) from an enterprise architecture perspective:
Company: Confluent is a global player with 3000+ employees and listed on the NASDAQ
Confluent is a global player in the software and cloud industry employing ~3000 reaching $1 Billion ARR soon. As announced a few earnings calls back, the company now also focuses on profit instead of just growth, and the last quarter was the first profitable quarter in the company’s history. This is a tremendous achievement looking into Confluent’s future.
- What is data streaming?
- What are the benefits, differences, and trade-offs compared to traditional software design patterns (like APIs, databases, message brokers, etc.) and related products/cloud services?
- What use cases do companies use data streaming for?
- How do industry-specific deployments look like (this differs a lot in financial services vs. retail vs. manufacturing vs. telco vs. gaming vs. public sector)?
- What is the business value (reduced cost, increased revenue, reduced disk, improved customer experience, faster time to market)?
“The Past, Present and Future of Stream Processing” shows the evolution and looks at new concepts like emerging streaming databases and the unification of operational and analytical systems using Apache Iceberg or similar table formats.
Confluent is a well-known software and cloud company today. As part of my job, I present at international conferences, give press interviews, brief research analysts like Gartner/Forrester, and write public articles to let people know (in as simple as possible words) what data streaming is and why the adoption is so massive across all regions and industries.

Confluent Partners: Cloud Service Providers, 3rd Party Vendors, System Integrators
Confluent strategically works with cloud service providers (AWS, Azure, GCP, Alibaba), software / cloud vendors (the list is too long to name everyone), and system integrators. While some people still think about a company like AWS as an enemy, it is much more a friend to co-sell data streaming in combination with other cloud services via the Amazon marketplace.
The list of strategic partners grows year by year. One of the most exciting announcements of 2023 was the strategic partnership between SAP and Confluent to connect S/4Hana ERP and other systems with the rest of the software and cloud world using Confluent.
Confluent Customers: From Open Source Kafka to Hybrid Multi-Cloud
Confluent has over 5000 customers already. I talk about many of these customer journeys in by blogs. Just search for your favorite industry to learn more. One exciting example is the evolution of the data streaming adoption at BMW. Coming from a wild zoo of deployments, BMW has standardized on Confluent, including self-service, data governance, and global rollouts for smart factory, logistics, direct-to-consumer sales and marketing, and many other use cases.
BMW hosts an internal Kafka Wiesn (= Oktoberfest) every year where we sponsor some pretzels and internal teams and external partners like Michelin present new projects, use cases, success stories, architectures and best practices around the data streaming world for transactional and analytical workloads. Here is a picture of our event in 2023 where my colleague Evi Schneider and I visited the BMW headquarters:

FUTURE: Data streaming is a new software category in 2024+
Thinking about Gartner’s famous hype cycle, we are reaching the “plateau of productivity”. Thanks to mature open source frameworks, sophisticated (but far from perfect) products, and fully managed SaaS cloud offerings make the mass adoption of data streaming possible in the next few years.
Tech: Standards and (multi-cloud) SaaS are the new black
In December 2023, the research company Forrester published “The Forrester Wave™: Streaming Data Platforms, Q4 2023“. Get free access to the report here. The leaders are Microsoft, Google, and Confluent, followed by Oracle, Amazon, Cloudera, and a few others. IDC followed in early 2024 with a similar report. This is a huge proof that the category of data streaming is attested. A Gartner Magic Quadrant for Data Streaming will hopefully (and likely) follow soon, too… 🙂
Company: Confluent is more than just Kafka and Flink; it is becoming the provider of a true data streaming platform
In the past years, the company transitioned from “the Kafka vendor” into a data streaming platform. Confluent still does only one thing (data streaming), but better than everyone else regarding product, support and expertise. I am huge fan of this approach compared to vendors with a similar number of employees that try to (!) solve every (!) problem.
As Confluent is a public company, it is possible to attend the quarterly earnings calls to learn about the product strategy and revenue/growth.
From a career perspective, I still enjoy doing the same thing I did when I started at Confluent seven years ago. I transitioned into the job role of a Global Field CTO, focusing more on executive and business conversations, not just focusing on the technology itself. This is a job role that comes up more and more in software companies. There is no standard definition for this job role. As I regularly get the question about what a Field CTO does, I summarized the tasks in my “Daily Life As A Field CTO“. The post concludes with the answer to how you can also become a Field CTO at a software company in your career.
Data streaming is still in an early stage…
I was really excited to start at Confluent in May 2017. I visited Confluent’s London and Palo Alto headquarters in the first weeks and also attended Kafka Summit in New York. It was an exciting month to get started in an outstanding Silicon Valley startup. Today, I still visit our headquarters regularly for executive briefings, and Kafka Summit or similar events from Confluent like Current and the Data in Motion Tour around the world.
I hope this was an interesting report about my past seven years in the data streaming world at Confluent. What is your opinion about the future of open source technologies like Apache Kafka and Flink, the transition to the cloud, and the outlook for Confluent as a company? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





