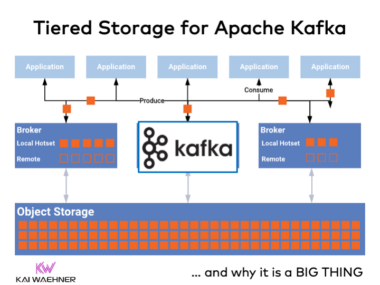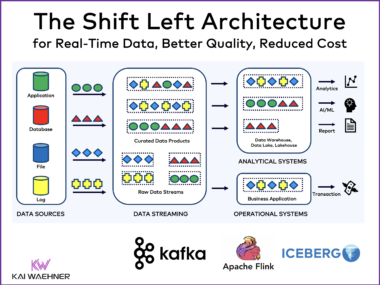
The Shift Left Architecture – From Batch and Lakehouse to Real-Time Data Products with Data Streaming
Data integration is a hard challenge in every enterprise. Batch processing and Reverse ETL are common practices in a data warehouse, data lake or lakehouse. Data inconsistency, high compute cost, and stale information are the consequences. This blog post introduces a new design pattern to solve these problems: The Shift Left Architecture enables a data mesh with real-time data products to unify transactional and analytical workloads with Apache Kafka, Flink and Iceberg. Consistent information is handled with streaming processing or ingested into Snowflake, Databricks, Google BigQuery, or any other analytics / AI platform to increase flexibility, reduce cost and enable a data-driven company culture with faster time-to-market building innovative software applications.