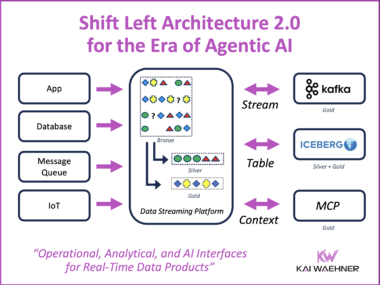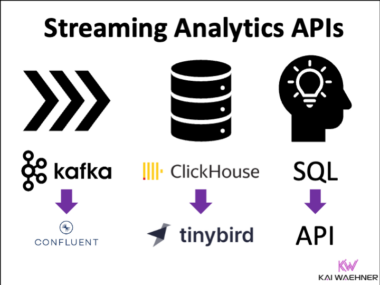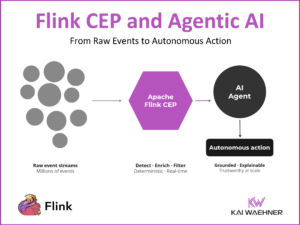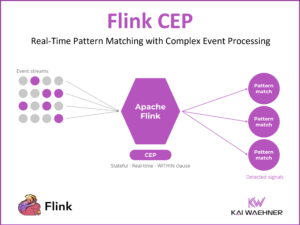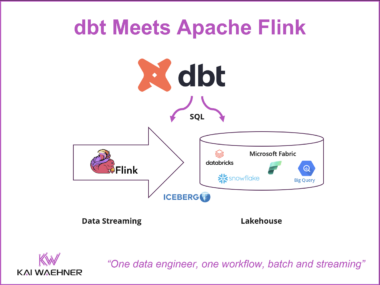
dbt Meets Apache Flink: One Workflow for Data Engineers on Snowflake, BigQuery, Databricks, and Confluent
Two toolchains, two skill sets, two CI/CD pipelines — that has been the reality for data engineers working across batch and streaming. dbt extending to Apache Flink changes that equation. One workflow, one tool, one engineering team for both worlds.