Pulsar vs Kafka – which one is better? This blog post explores pros and cons, popular myths, and non-technical criteria to find the best tool for your business problem.
My discussions are usually around Apache Kafka and its ecosystem as I work for Confluent. The only questions I got about Pulsar in the last years came from Pulsar committers and contributors. They asked me deep technical questions so as to be able to explain where Kafka sucks and why Pulsar is the much better option. Discussions about this topic on platforms like Reddit are typically very opinionated, often inaccurate, and brutal. The following is my point of view based on years of experience with open source streaming platforms.
Tech comparisons are the new black: Kafka vs. Middleware, Event Streaming and API Platforms
Tech comparisons are meant to guide people to choose the right solution and architecture for their business problem. There is no all-rounder, and there should be no bias. Choose the right tool for the problem.
However, technical comparisons are almost always biased. Even if the author does not work for a vendor and is an “independent” consultant, he or she is still likely to have a biased opinion from past experiences and knowledge, whether purposely or unknowingly. Still, comparisons from different perspectives are useful, and we’ve seen Apache Pulsar discussed in a few places on the internet, so I wanted to share my personal views of how Kafka and Pulsar compare. I work for Confluent, the leading experts behind Apache Kafka and its ecosystem, so keep that in mind, but the aim of this post is not to provide opinion, it’s to weigh up facts rather than myths.
Technical comparisons of open source frameworks and commercial software products happen all the time. I did several comparisons in the past on my blog or other platforms like InfoQ, including a Comparison of integration frameworks, Choosing the right ESB for your integration needs, Kafka vs. ETL / ESB / MQ, Kafka vs. Mainframe and Apache Kafka and API Management / API Gateway. All these comparisons were done because customers wanted to understand when to use which tool.
For Pulsar vs. Kafka, the situation is a little bit different.
Why compare Pulsar and Kafka?
Talking to prospects or customers, I rarely get asked about Pulsar. To be fair, this increased slightly in the last months. I guess the question comes up in every ~15th or ~20th meeting due to the overlapping feature set and use cases. However, this seems to be mostly due to a few posts on the internet that claim Pulsar is in some ways better than Kafka. There is no fact-checking and very little material, if any, for the opposing view.
I have not talked to a single organization that seriously considered deploying Pulsar in production, although I know there are a large number of users out there in the world who need a distributed messaging technology like Kafka or Pulsar. But I also think that Pulsar’s alleged reference users are not particularly accurate.
For example, their flagship user is Tencent, a large Chinese tech company, but Tencent is a huge Kafka user, whereas Pulsar’s use is limited to just one project. Tencent processes trillion messages per day (in digits: 10,000,000,000,000) with Kafka. As it turns out, Tencent uses Kafka 1000x more than Pulsar (ten trillion msg/day vs. tens of billion msg/day). The Tencent team discussed their Kafka deployment in more detail: How Tencent PCG Uses Apache Kafka to Handle 10 Trillion+ Messages Per Day.
Comparison of two competitive open source frameworks
Apache Kafka and Apache Pulsar are two exciting and competing technologies. Therefore, it makes a lot of sense to compare them. Period.
Both Apache Kafka and Apache Pulsar have very similar feature sets. I recommend that you evaluate both frameworks for available features, maturity, market adoption, open source tools and projects, training material, availability of local meetups, videos, blog posts, etc. Reference use cases from your industry or business problems help making the right decision.
Confluent published such a comparison of “Kafka vs. Pulsar vs. RabbitMQ: Performance, Architecture, and Features Compared“. I was involved in creating this comparison. So we have that comparison already…
What is this blog post here about then?
I want to explore the myths from some ‘Kafka vs. Pulsar’ arguments which I see regularly in blog posts and forum discussions. Afterwards, I will give a more comprehensive comparison beyond just technical aspects because most Pulsar discussions focus purely on tech features.

Kafka vs Pulsar – Technology myths explored
The following discusses some myths I have come across. I agree with some of them, but also counter some others with hard facts. Of course, different opinions can exist for some of these statements. Again, this is totally fine. The following is my point of view.
Myth 1: “Pulsar has differentiating built-in features compared to Kafka”?
True.
If you compare Apache Kafka to Apache Pulsar, features like its tiered architecture, queuing, and multi-tenancy are mentioned as differentiators.
But:
Kafka has many differentiating features, too:
- Half as many servers to run
- Data saved to disk only once
- Data cached in memory only once
- Battle-tested replication protocol
- Zero copy performance
- Transactions
- Built-in stream processing
- Long term storage
- In the works: ZooKeeper removal (KIP-500), which makes Kafka even more simple to operate and deploy than Pulsar (which has a four-component architecture of Pulsar, ZooKeeper, BookKeeper, and RocksDB), apart from making Kafka more scalable, more resilient, etc. etc..)
- In the works: Tiered Storage (KIP-405), which makes Kafka more elastic and cost-efficient.
Also ask yourself: Should you really compare just the open source frameworks or products and vendors with their complete offering?
It is easy to add new features if you don’t have to provide mission-critical support for it. Don’t just evaluate features in a checklist, but also evaluate how they are battle-tested in production scenarios. How many “differentiating features” are low-quality and implemented quickly vs. high-quality implementations?
For instance: It took a few years to implement and battle-test Kafka Streams as Kafka-native stream processing engine. Do you really want to compare this to Pulsar Functions? The latter is a feature to add user-defined functions (UDF); without any relation to “real stream processing”. Or is this more like Single Message Transformations (SMT), a core feature of Kafka Connect? Just be sure to a) compare apples to apples (instead of apples to oranges) and b) don’t forget to think about the maturity of a feature. The more powerful and critical, the more mature it should be…
The Kafka community spends a large amount of efforts to improve the core project and its ecosystem. Confluent alone has over 200 full time engineers working on the Kafka project, additional community components, commercial products and the SaaS offering on major cloud providers.
Myth 2: “Pulsar has a few very big users like Tencent in China”?
True.
But: Tencent actually uses Kafka more than Pulsar. The billing department, which uses Pulsar, is only a small fraction at Tencent, whereas a large portion of the core business is using Kafka, and they have a Global-Kafka like architecture that combines 1000+ brokers into a single logical cluster.
Always be cautious with open source projects. Check out the success at “normal companies”. Just because a tech giant uses it, does not mean it will work for your company well. How many Fortune 2000 companies shared their success stories around Pulsar in the past?
Look for proof points beyond tech giants!
Proof points beyond the tech giants are helpful to get insights and lessons learned from other people. Not from the software vendors. The Kafka website gives many examples about mission-critical deployments. Even more impressive: At the past Kafka Summit conferences in San Francisco, New York and London, every year various enterprises from different industries present their use cases and success stories. Including fortune 2000 companies, mid-size enterprises and startups.
Just to give you one specific example in the Kafka world: Various different implementations exist for replication of data in real time between separate Kafka clusters, including MirrorMaker 1 (part of the Apache Kafka project), MirrorMaker 2 (part of the Apache Kafka project), Confluent Replicator (built by Confluent and only available as part of Confluent Platform or Confluent Cloud), uReplicator (open sourced by Uber), Mirus (open sourced by Salesforce), Brooklin (open sourced by LinkedIn).
In practice, only two options are reasonable if you don’t want to maintain and improve the code by yourself: MirrorMaker 2 (very new, not mature yet, but a great option mid and long term) and Confluent Replicator (battle-tested in many mission-critical deployments, but not open source). All the other options work, too. But who maintains the projects? Who solves bugs and security issues? Who do you call when you have a problem in production? Deployment in production for mission-critical deployments is different from evaluating and trying out an open source project.
Myth 3: “Pulsar provides message queuing and event streaming in a single solution”?
Partly.
Message queues are used for point-to-point communication. They provide an asynchronous communications protocol, meaning that the sender and receiver of the message do not need to interact with the message queue at the same time.d
Pulsar has only limited support for message queuing, and limited support for event streaming. If it wants to compete in either area, it still has a long way to go for two reasons:
1) Pulsar has only limited support for message queuing because it misses popular messaging features like message XA transactions, routing, message filtering, etc. that are commonly used with messaging systems like IBM MQ, RabbitMQ, and ActiveMQ. Pulsar’s “adapters” for messaging systems are similarly limited. While they may look nice on paper, they are less useful in practice.
2) Pulsar has only limited support for event streaming. For example, it does not support exactly-once delivery and processing semantics, which disqualifies it for most use cases in practice – you would never implement, say, a payment processing system with Pulsar as it may cause duplicate payments, or lose payments. It also lacks functionality to perform stream processing with features like joins, aggregations, windowing, fault-tolerant state management, and event-time based processing. Pulsar’s “topics” functionality is also different to Kafka’s, and suffers from BookKeeper’s origins, as it was conceived and designed in 2008 as a write ahead log for Hadoop’s HDFS namenode, with only short-lived data storage in mind.
Side note: Pulsar’s “Kafka adapter”, like its messaging siblings, is similarly limited. While it may look nice on paper, it is less useful in practice because it supports only a small subset of Kafka functionality.
Like Pulsar, Kafka has only limited support for message queuing.
In Kafka, different workarounds can be used to realize “real queuing” behavior. If you want to use separate message queues instead of shared Kafka topics for:
- Security? => Use Kafka’s ACLs (and optional tools like Confluent’s role-based access control aka RBAC).
- Semantics (i.e. separate applications)? => Use Kafka’s consumer groups.
- Load balancing? => Use Kafka’s partitions.
I typically ask customers what exactly they want to do with queuing. Often, Kafka provides out-of-the-box solutions for use cases which simply require thinking of the solution in new terms. Also, the number of high throughput use cases that need queuing is relatively small.
Having explained all these workarounds and limitations of Pulsar and Kafka for messaging, let’s be clear: Neither Kafka nor Pulsar provide a “real messaging solution”.
If you really need a messaging solution, shouldn’t you better choose a “real messaging framework” like RabbitMQ or NATS for a messaging problem anyway?
There is no ‘yes or no’ answer to this. I see many customers replacing existing messaging systems like IBM MQ with Kafka (for scalability and cost reasons). Know the options, their trade-offs, and do an evaluation to solve your problem the best way…
Myth 4: “Pulsar provides stream processing”?
False.
Or to be fair: It depends on your definition of stream processing. Is it only rudimentary features, or full-fledged stream processing?
In one sentence, I typically explain stream processing as continuous consumption, processing, and aggregation of events from different data sources. In real time. At scale. And, of course, in a fault-tolerant manner, including (and especially) for any stateful processing operations.
Pulsar provides only rudimentary functionality for stream processing, using its Pulsar Functions interface. This is suited for simple callbacks, but it isn’t a true stream processing offering like you get it with Kafka Streams or ksqlDB for building streaming applications that include stateful information, sliding windows, and other stream processing concepts. Use cases exist in every industry. For instance, check out the Kafka Streams website for examples from the New York Times, Pinterest, Trivago, Zalando, and others.
Streaming analytics examples with Pulsar typically use Pulsar in conjunction with another “proper” stream processing framework like Apache Spark or Apache Flink, which of course means you now need to operate even more additional pieces of distributed infrastructure and to understand their complex interactions.
Myth 5: “Pulsar provides exactly-once semantics like Kafka”?
False.
Pulsar provides a deduplication feature that ensures that a message will not be stored in the Pulsar broker twice, but nothing prevents a consumer from reading this message multiple times. This is insufficient for any form of stream processing use case where both input and output are from Pulsar.
Also, unlike Kafka’s Transactions feature, it is not possible to accurately tie messages committed to state recorded inside a stream processor.
Exactly-Once Semantics (EOS) are available since Kafka 0.11 (released three years ago) and used in many production deployments. Kafka’s EOS supports the whole Kafka ecosystem, including Kafka Connect, Kafka Streams, ksqlDB and clients like Java, C, C++, Go or Python. Kafka Summit had several talks about Kafka’s EOS functionality, including this great intro for everybody, with slides and video recording.
Myth 6: “Pulsar’s performance is much better than Kafka’s”?
False.
I am not a fan of most “benchmarks” of performance and throughput. Benchmarks are almost always opinionated and configured for a specific problem (no matter if a vendor, independent consultant, or researcher conducts them).
For example, there is one benchmark published by GIGAOM, which compares the latency and performance of Kafka versus Pulsar. But this benchmark deliberately slowed Kafka down by forcing it to synchronize-to-disk on every single message by setting the Kafka config ‘flush.messages = 1’ (this makes every request cause an fsync). The benchmark also forces the Kafka Consumer to acknowledge synchronously while the Pulsar consumer acknowledges asynchronously. Unsurprisingly, this benchmark setup makes Pulsar the seemingly clear “winner”. But this benchmark does not mention or explain this significant configuration difference in the setup and measurements. This is what some people call apples-to-oranges comparison.
Pulsar’s architecture actually requires higher network utilization (due to the Pulsar broker tier which acts as a proxy in front of BookKeeper bookies) as well as twice the I/O (as BookKeeper writes data to a write ahead log as well as to the main segment).
Confluent did some benchmarks, too. More an apple-to-apple comparison. Not surprisingly, the results were different. But should you really care about these benchmark fights from software vendors?
Think about your performance requirements. Do a proof of concept (POC) with Kafka and Pulsar, if you must. I bet that in 99% of scenarios, both will show acceptable performance for your use case. Don’t trust opinionated benchmarks from others! Your use case will have different requirements and characteristics anyway, and typically performance is just one of many evaluation dimensions.
Myth 7: “Pulsar is easier to operate than Kafka”?
False.
Both Kafka and Pulsar are hard to operate if you don’t use additional tooling.
Kafka includes two distributed systems: Kafka itself and Apache ZooKeeper.
But: Pulsar includes three distributed systems and an additional storage technology: Pulsar, ZooKeeper, and Apache BookKeeper. Like Pulsar, BookKeeper uses ZooKeeper, too. And lastly, RocksDB is used for certain storage tasks. This means that Pulsar has a significantly higher complexity to understand, tweak, and tune than Kafka. Additionally, Pulsar also has more configuration parameters than Kafka.
Kafka is firmly going into the opposite direction and is removing ZooKeeper (see KIP-500) so that you have just one distributed system to deploy, operate, scale and monitor:
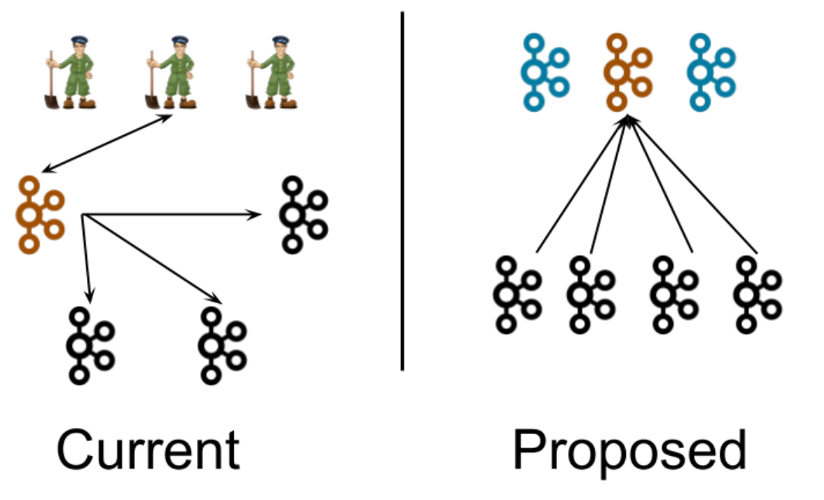
ZooKeeper is Kafka’s biggest scalability bottleneck and comes with operational challenges — This is true for Kafka but even more so for Pulsar!
One of the key issues of my customers is how to run ZooKeeper in mission-critical deployments at scale. Therefore I am really looking forward to Kafka’s simplified architecture, where you will deploy Kafka brokers only. This also establishes a unified security model, as ZooKeeper’s security no longer needs to be separately configured. This is a huge benefit, especially for larger organizations and regulated industries. Compliance and information security departments will thank you for this simplified architecture.
Operations is NOT just about Architecture!
Kafka is significantly better documented, has a tremendously larger community of experts, and a vast array of supporting tooling that make operations easier.
Additionally, there are many options for local and online Kafka training, including online courses, books, meetups, and conferences. You won’t find much for Pulsar, unfortunately.
Myth 8: “An architecture with three tiers is better than two tiers”?
It depends.
Personally, I am skeptical that Pulsar’s three tier architecture (using Pulsar brokers, ZooKeeper and BookKeeper) is an advantage for most projects. It is a trade-off!
Twitter described their move away from BookKeeper + DistributedLog (the latter a system very similar to Pulsar, with comparable architecture and design) just over a year ago, citing the advantages of Kafka’s single-tier architecture, such as cost efficiency and better performance, over a two-tier architecture that decouples storage and serving.
Like Pulsar, DistributedLog is built on top of BookKeeper and adds streaming-like functionality with an architecture and concepts similar to Pulsar (e.g., using decoupled storage and serving tiers). DistributedLog was originally a standalone project but eventually became a sub-project of BookKeeper, though nowadays it appears to be no longer actively developed (only a few commits in the past 12 months). The main reasons Twitter cited for switching to Kafka were (1) significant cost savings and performance gains and (2) Kafka’s huge community and adoption. For example, they concluded: “For single consumer use cases, we saw a 68% resource savings, and for fanout cases with multiple consumers, we saw a 75% resource savings.”
There are benefits from a three-tier architecture to build a scalable infrastructure. But the extra layer also increases network utilization by (at least) 33%, and data held in Pulsar’s brokers must additionally be cached in both layers for equivalent performance, and also written to disk twice because the storage format of Bookkeeper is not based on a log.
On the cloud, where most Kafka deployments are being run, the best backing storage tier is in fact not a niche technology like BookKeeper, but a widely used and battle-tested object store like AWS S3 or GCP GCS.
Tiered Storage in Confluent Platform, which is backed by the likes of AWS S3 and GCP GCS, provides the same benefits without Pulsar’s extra layer of BookKeeper and the resulting extra network transfer cost and latency that this architecture incurs. It took Confluent two years to build and make Tiered Storage for Kafka generally available, including global 24/7 support for your most mission-critical data. Tiered Storage is not available yet for open source Apache Kafka, but Confluent is working with the rest of the Kafka community (including some major tech companies like Uber) on KIP-405 to add Tiered Storage to Kafka with different storage options.
There are always pros and cons for both architectures. Personally, I think that 95% of projects do not need a complex three-tier architecture. And where they make sense it is to add the advantages of external, price-efficient storage. You should care about 24/7 service level agreements (SLA), scalability, and throughout. Plus integration into your ecosystem as well as security, management tooling, and support. If your requirements require a three-tier architecture, then of course give it a go!
Sub-Myth: “Pulsar is better for lagging consumers because of its caching layer and storage layer”?
False.
The main problem with lagging consumers is that they exhaust the page cache i.e. recent messages are already cached. Reads from older segments replace these reducing the performance of consumers reading from the head of the log.
Pulsar’s architecture is actually worse in this regard. It retains the same issue around cache-flushing, but now the reads must do an extra network hop + and IO rather than just reading from the local media.
Myth 9: “Kafka does not scale as well as Pulsar”?
False.
This is one of the key arguments by the Pulsar community. As I said before, this always depends on the chosen benchmark. For example, I have seen tests with equivalent computing resources where Kafka did significantly better at high throughputs than Pulsar. Here is a “Pulsar vs. Kafka benchmark” where Kafka is much faster than Pulsar:
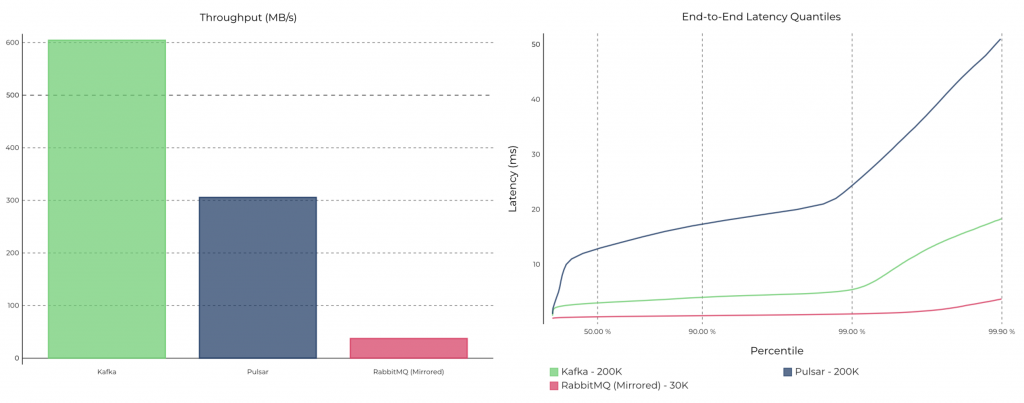
Scalability is not a problem for most use cases. You can easily scale up Kafka to process several gigabytes per second, as you can see in a demo to “Scale Apache Kafka to 10+ GB Per Second in Confluent Cloud“:

Honestly speaking, less than 1% of users should be worried about this discussion at all. If you have requirements like Netflix (processing Petabytes per day) or LinkedIn (processing trillions of messages), let’s talk about and discuss the best architecture, hardware, and configuration for such a deployment. For anybody else, don’t be worried.
Sub-Myth: “Kafka’s current approach means it can only store ~ 500K partitions per cluster”?
True.
Kafka today has not yet the best architecture for large scale deployments with hundreds of thousands of Kafka Topics and Partitions.
But: Pulsar, too, does not allow for unlimited scale. It just has different limits.
Kafka’s partition limit is imposed by Zookeeper. Removing Zookeeper from Kafka through the work in KIP-500 removes this upper bound.
As a side note:
The right design of your architecture is critical for success!
Most of the customers I have seen in trouble with Kafka partition counts and scalability are because they designed their architecture and applications in the wrong way (they’d run into the same issues if they were using Pulsar)!
Kafka is an event streaming platform, and not the next IBM MQ. If you try to recreate your favorite MQ solution and architecture with Kafka, you will likely fail. I have seen several customers failing here and then succeeding by re-architecting their setup with our help.
Chances are very high that you will not have any issues with partition numbers and scalability, even today with Kafka’s usage of ZooKeeper, if you design your use case right and understand Kafka’s basic concepts. This experience of customers is a common theme for any technology, like Kafka, that introduces a new technology level and paradigm well beyond what was done before (a prime example is the adoption hurdles faced by companies when they first began to move their use cases to the cloud).
Sub-Myth: “Pulsar supports a practically infinite number of partitions”?
False.
BookKeeper has the same 1-file-per-ledger limitation Kafka has, but there are multiple ledgers in one partition. Pulsar’s broker layer groups partitions into bundles, but it’s storage layer, Bookkeeper, stores data in segments with many segments for each partition.
Like for Kafka, the metadata for these segments is stored in Zookeeper, which imposes a limit on the total number that can be stored. Kafka is removing this dependency, thus allowing it to scale significantly further. I am really looking forward to seeing KIP-500 being implemented until ~ the end of 2020. “Apache Kafka Needs No Keeper: Removing the Apache ZooKeeper Dependency” walks you through the implementation details and planned timelines.
Sub-Myth: “Kafka scaling needs to be defined when creating a Kafka Topic”?
Partly true.
If more scalability is needed, Kafka topics can either be over-partitioned (i.e., you configure a topic with more partitions than you initially need for a use case; see Streams and Tables in Apache Kafka: Topics, Partitions, and Storage Fundamentals), or they can be re-configured to use more partitions if there are requirements to scale in the future. This is not perfect, but a consequence of how distributed event streaming works (and why it scales much better than traditional messaging systems like IBM MQ).
Best practices for creating topics and procedures for changing topic configurations during production are available. So no worries!
But: Pulsar topics have this restriction, too!
Write throughput is based on the number of partitions allocated in a Pulsar topic in the exact same way it is in a Kafka topic, so Pulsar topics must be over-provisioned for exactly the same reasons. That’s because, for each partition, only a single ledger (of the partition’s potentially many ledgers) is writable at the same time. Also, increasing the number of partitions dynamically impacts message ordering just like it does in Kafka (i.e. the message order is lost).
Both Kafka and Pulsar scale like crazy. This is sufficient for almost all use cases!
If you need even more extreme scale, I think a ZooKeeper-free implementation is the best choice. KIP-500 is thus the most anticipated Kafka change I see in the community and in Confluent’s customer base.
Myth 10: “Pulsar recovers from machine failure instantly but Kafka has to reload data”?
True and false.
Killing a Pulsar broker is indeed seamless, but (in contrast to a Kafka broker) the Pulsar broker doesn’t store any data but is only a proxy fronting the actual storage layer, which is BookKeeper. So highlighting that a Pulsar broker failure can easily be resolved is a marketing distraction, because actually one must talk about what happens when a BookKeeper node (a “bookie”) fails.
Killing and restarting a BookKeeper bookie requires the same redistribution of data seen in Kafka’s case. This is the nature of distributed systems, with concepts like replication and partitions.
Elastic Kafka is here already!
Elasticity is important. Confluent’s founder Jay Kreps has recently blogged about this topic: Elastic Apache Kafka Clusters in Confluent Cloud. In a SaaS cloud service like Confluent Cloud, the end user shouldn’t have to care at all about machine failure. 24/7 uptime is expected and should be guaranteed with 99.xx SLAs. Consumption-based pricing (i.e., pay as you go) means you do not have to worry about issues like broker management, sizing broker nodes, expanding or shrinking clusters, etc. under the hood at all.
Self-managed Kafka clusters also need similar capabilities. Tiered Storage for Kafka is huge because most of the data is not stored on the broker anymore to allow almost instant recovery from failures. In conjunction with tools like Self-Balancing Kafka (a Confluent feature coming in Q3 and discussed in the above link blog post), users don’t have to worry about elasticity in their self-managed clusters at all.
Unfortunately, if you are looking for such a modern offering for Pulsar, there is none available.
Myth 11: “Pulsar has better Inter-Cluster (Geo) Replication than Kafka”?
False.
Every distributed system has to solve problems like the CAP theorem and quorum in distributed computing. The quorum is the minimum number of votes that a distributed transaction has to obtain in order to be allowed to perform an operation in a distributed system. A quorum-based technique is implemented to enforce consistent operation in a distributed system.
Kafka requires ZooKeeper to solve the quorum problem. Even after KIP-500 and ZooKeeper removal, the universal laws of real-world physics are still the same: There are latency issues deploying a distributed system over regions like the US East, Central and West or even globally. That’s because the speed of light, though very high, does have a limit.
Various deployment options exist to work around this problem, including real time replication tools like Apache Kafka’s MirrorMaker 2, Confluent’s Replicator or Confluent’s Multi-Region-Clusters. Check out “Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments” for various different deployment options and best practices:
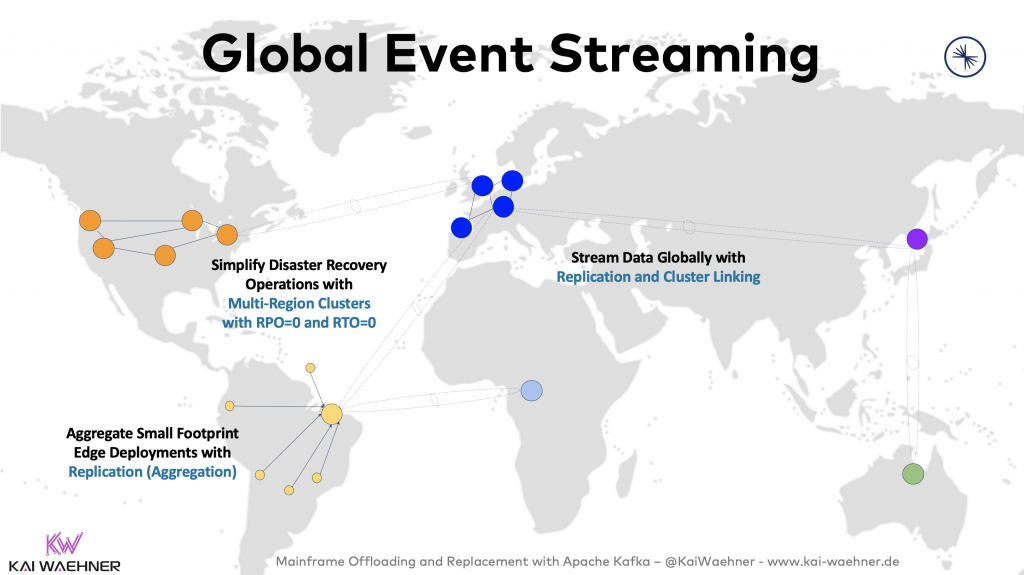
There is no single pattern or implementation to provide global replication AND zero downtime + zero data loss! For the most critical applications, Confluent’s Multi-Region-Clusters allows RTO=0 and RPO=0 (i.e. zero downtime and zero data loss) with automatic disaster recovery and client fail-over even if a complete data center or cloud region goes down.
Here, Pulsar’s architecture requires even more complexity than a “basic” Pulsar deployment. That’s because, for geo-replication, Pulsar requires an additional “global” Zookeeper cluster, which makes Pulsar inappropriate for geo-distribution over large distances. There is a workaround, but the problem around CAP theorem and physics do not go away.
No matter if you use Kafka or Pulsar, you need a battle-tested design to fight the laws of physics in your global deployments!
Myth 12: “Pulsar is compatible with Kafka’s interface and API”?
Partially True.
Pulsar provides a very basic implementation that is compatible with only minor parts of the Kafka v2.0 protocol.
Pulsar has a converter for basic parts of the Kafka protocol.
So, while alleged “Kafka compatibility” sounds nice on paper, one shouldn’t seriously consider this for migrating your running Kafka infrastructure to Pulsar? I doubt someone will take the risk…
We have seen “Kafka compatibility” claims in other examples such as the much more mature Azure Event Hubs service. Check out the limiting factors of their Kafka API, and be surprised! No support for core Kafka features like transactions (and thus exactly-once semantics), compression, or log compaction.
As it is not Kafka under the hood, also expect further diverging and unexpected behaviors when you connect your existing Kafka applications against such a “compatible” setup. No matter if Azure Event Hubs, Pulsar, or any other wrapper.
Kafka vs. Pulsar – Comprehensive Comparison
The last sections explored various technology myths we find in many other blog posts. I think I brought some clarity into these discussions.
Now, let’s not forget to take a look beyond the technical details of Kafka and Pulsar. Non-functional aspects are as important when choosing a technology.
I will cover three critical aspects in the following: Market traction, enterprise support and cloud offerings.
Market Traction of Apache Kafka and Apache Pulsar
Taking a look at Google Trends from the last five years confirms my personal experience, I see the interest in Apache Pulsar is very limited compared to Apache Kafka:
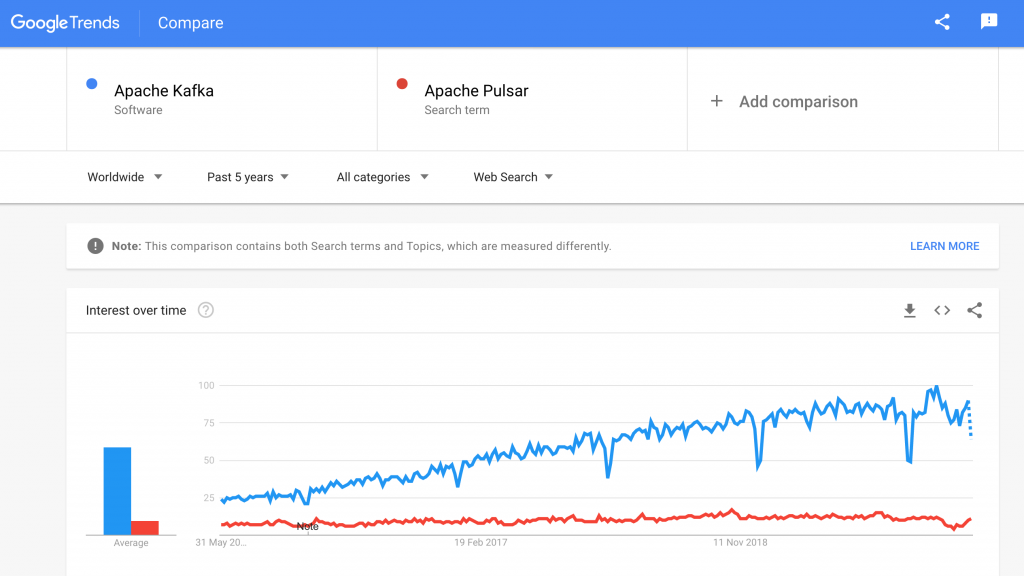
The picture looks very similar when you take a look at Stack Overflow and similar platforms, number and size of supporting vendors, the open ecosystem (tool integrations, wrapper frameworks like Spring Kafka), and similar characteristics for technology trends.
Job openings is another very good indicator of adoption of technology. Not many job openings for Pulsar means not many companies are using it. Search in your favorite job search engine. If you search globally, you will find <100 job openings for Pulsar, but thousands of jobs for Kafka. Additionally, most of the ones showing Pulsar say something like “looking for experience with Kafka, Pulsar, Kinesis or similar technologies”.
In most cases, these characteristics are much more relevant for the success of your next project than the subtle technical differences. The key goal is to solve your business problem, isn’t it?
So with the lack of adoption, why is Pulsar coming up in conversations at all? One reason is that independent consulting companies, research analysts, and bloggers (including me) need to talk about new cutting-edge technologies to keep their audience interested… And to be honest, it makes a good story.
Enterprise Support for Kafka and Pulsar
There is enterprise support for Kafka and Pulsar!
Though, the situation is not what you might expect. Here are the vendors you can call and ask for a meeting to discuss the potential next steps for working together on your Pulsar journey:
- Streamlio (now acquired by Splunk), the former company behind Apache Pulsar. Splunk did not yet announce a future Pulsar strategy to support people working on their own Pulsar-based projects. Splunk is well-known for their widely-adopted analytics platform. That’s their core business (~ $1.8B in 2019). The only thing people complain about Splunk is the pricing. Splunk is a heavy Kafka user under the hood and now incorporates Pulsar into their Splunk Data Stream Processor (DSP). It is very doubtful that Splunk will jump on the open source bandwagon to support your next standalone Pulsar project (but a broader-scope DSP might be coming, of course). The future will show us…
- StreamNative, founded by one of the original developers of Apache Pulsar, provides an event streaming platform based on Pulsar. At the time of writing this in June 2020, StreamNative has 13 (!) employees on LinkedIn. I am not sure if this is the right scale to support your next mission-critical deployment in 2020 but they do offer it.
- TIBCO announced support for Pulsar in December 2019. Their core strategy moved from integration to analytics in the last years. TIBCO’s middleware customers are migrating away in high numbers. Their middleware team had to do some desperate strategy decisions: Support other platforms even though having zero contribution and experience with the projects. You are right, this might be a myth. But hey, a fact is that TIBCO also does the same for Kafka. And here is a nice trivia: TIBCO provides Kafka and ZooKeeper to you on Windows! Something nobody else does – because others know that this is not stable and creates inconsistencies all the time. But hey, TIBCO can support you now with Kafka and Pulsar. Why evaluate these two frameworks if one single vendor allows you to use both? Even on Windows; with .exe download and .bat scripts for starting the server components:
The number of vendors supporting Kafka grows every quarter!
Kafka has incredible huge market adoption in the meantime. The best proof for this is when the biggest software vendors provide support and tools around it. IBM, Oracle, Amazon, Microsoft and many other software companies support Kafka and build integration capabilities and own products around it.
The latest “wake-up call” for me was at Oracle OpenWorld 2019 in San Francisco where I attended a roadmap session from the Oracle product manager for GoldenGate (Oracle’s well-known great but also very expensive CDC tool). Most of the talk focused on opening GoldenGate to make it the data integration platform for everything. Half the talk was about event streaming, Kafka and how GoldenGate will provide integration with different databases / data lakes and Kafka in both directions.
Fully-Managed Cloud Offerings for Kafka and Pulsar
Let’s take a look at the cloud offerings available for Kafka and Pulsar.
There is a cloud service available for Apache Pulsar. It has a very innovative name:
No kidding. Check the link… [Update: On ~June 17th, they rebranded the service: KAFKAESQUE is now KESQUE – probably they realized how embarrassing the name was.]
Maybe you also check out the various cloud offerings for Apache Kafka to find out which offering fits you better:
- Confluent Cloud (SaaS) is a fully-managed service providing consumption-based pricing, 24/7 SLAs and elastic, serverless characteristics for Apache Kafka and its ecosystem (e.g. Schema Registry, Kafka Connect connectors and ksqlDB for stream processing).
- Amazon MSK (PaaS) provisions ZooKeeper and Kafka Brokers so that the end user can operate it, fix bugs, do rolling upgrades, etc. One important fact everybody should be aware of: AWS excludes Kafka issues from its 99.95 SLAs and support!
- Azure Event Hubs (SaaS) provides a Kafka endpoint (with a proprietary implementation under the hood) to interact with Kafka applications. It is very scalable and performant. As it is not really Kafka, but just an emulation, it misses several core features of Kafka like exactly-once semantics, log compaction, and compression. Not to mention the surrounding capabilities like Kafka Connect and Kafka Streams
- Big Blue (IBM) and Big Red (Oracle) have cloud offerings around Kafka and its APIs. I have no idea if anyone is using them and how good they are. Never seen them in the wild by myself.
- Plenty of smaller players like Aiven, CloudKarafka, Instaclustr, and others.
As you can see, the current cloud offerings show relatively clear how the market adoption of Kafka and Pulsar look like.
Conclusion – Apache Kafka or Apache Pulsar?
TL;DR: Pulsar is still a long way from Kafka’s level of maturity in terms of being proven for high scale use cases and building a community.
You should also question whether Pulsar is actually better.
Evaluate Kafka and Pulsar if you are going the purely open source way. Find out which fits you best. In your evaluation, include the technical feature set, maturity, vendors, developer community, and other relevant factors. Which one fits your situation best?
If you need an enterprise solution that covers much more than what both of these two open source systems offer, Kafka is the only option: Choose a Kafka-based offering from one of the various vendors or a suitable cloud offering. Pulsar, unfortunately, is not ready for this today and the foreseeable future.
How do you think about Apache Kafka vs. Apache Pulsar? What is your strategy? Let’s connect on LinkedIn and discuss! Stay informed about new blog posts by subscribing to my newsletter.