
How can I do request-response communication with Apache Kafka? That’s one of the most common questions I get regularly. This blog post explores when (not) to use this message exchange pattern, the differences between synchronous and asynchronous communication, the pros and cons compared to CQRS and event sourcing, and how to implement request-response within the data streaming infrastructure.

Message Queue Patterns in Data Streaming with Apache Kafka
Before I go into this post, I want to make you aware that this content is part of a blog series about “JMS, Message Queues, and Apache Kafka”:
- 10 Comparison Criteria for JMS Message Broker vs. Apache Kafka Data Streaming
- Alternatives for Error Handling via a Dead Letter Queue (DLQ) in Apache Kafka
- THIS POST – Implementing the Request-Reply Pattern with Apache Kafka
- UPCOMING – A Decision Tree for Choosing the Right Messaging System (JMS vs. Apache Kafka)
- UPCOMING – From JMS Message Broker to Apache Kafka: Integration, Migration, and/or Replacement
I will link the other posts here as soon as they are available. Please follow my newsletter to get updated in real-time abo t new posts. (no spam or ads)
What is the Request-Response (Request-Reply) Message Exchange Pattern?
Request-response (sometimes called request-reply) is one of the primary methods computers use to communicate with each other in a network.
The first application sends a request for some data. The second application responds to the request. It is a message exchange pattern in which a requestor sends a request message to a replier system, which receives and processes the request, ultimately returning a message in response.
Request-reply is inefficient and can suffer a lot of latency depending on the use case. HTTP or better gRPC is suitable for some use cases. Request-reply is “replaced” by the CQRS (Command and Query Responsibility Segregation) pattern with Kafka for streaming data. CQRS is not possible with JMS API, since JMS provides no state capabilities and lacks event sourcing capability. Let’s dig deeper into these statements.
Request-Response (HTTP) vs. Data Streaming (Kafka)
Prior to discussing synchronous and asynchronous communication, let’s explore the concepts behind request-response and data streaming. Traditionally, these are two different paradigms:
Request-response (HTTP):
- Typically synchronous
- Point to point
- High latency (compared to data streaming)
- Pre-defined API
Data streaming (Kafka):
- Continuous processing
- Often asynchronous
- Event-driven
- Low latency
- General-purpose events
Most architectures need request-response for point-to-point communication (e.g., between a server and mobile app) and data streaming for continuous data processing. With this in mind, let’s look at use cases where HTTP is used with Kafka.
Synchronous vs. Asynchronous Communication
The request-response message exchange pattern is often implemented purely synchronously. However, request-response may also be implemented asynchronously, with a response being returned at some unknown later time.
Let’s look at the most prevalent examples of message exchanges: REST, message queues, and data streaming.
Synchronous Restful APIs (HTTP)
A web service is the primary technology behind synchronous communication in application development and enterprise application integration. While WSDL and SOAP were dominant many years ago, REST / HTTP is the communication standard in almost all web services today.
I won’t go into the “HTTP vs. REST” debate in this post. In short, REST (Representational state transfer) has been employed throughout the software industry and is a widely accepted set of guidelines for creating stateless, reliable web APIs. A web API that obeys the REST constraints is informally described as RESTful. RESTful web APIs are typically loosely based on HTTP methods.
Synchronous web service calls over HTTP hold a connection open and wait until the response is delivered or the timeout period expires.
The latency of HTTP web services is relatively high. It requires setting up and tearing down a TCP connection for each request-response iteration when using HTTP. To be clear: The latency is still good enough for many use cases.
Another possible drawback is that the HTTP requests might block waiting for the head of the queue request to be processed and may require HTTP circuit breakers set up on the server if there are too many outstanding HTTP requests.
Asynchronous Message Queue (IBM MQ, RabbitMQ)
The message queue paradigm is a sibling of the publisher/subscriber design pattern and is typically one part of a more extensive message-oriented middleware system. Most messaging systems support both the publisher/subscriber and message queue models in their API, e.g., Java Message Service (JMS). Read the “JMS Message Queue vs. Apache Kafka” article if you are new to this discussion.
Producers and consumers are decoupled from each other and communicate asynchronously. The message queue stores events until they are consumed successfully.
Most message queue middleware products provide built-in request-response APIs. Its communication is asynchronous. The implementation uses correlation IDs.
The request-response API (for example, in JMS) creates a temporary queue or topic that is referenced in the request to be used by the consumer by taking the reply-to endpoint from the request. The ID is used to separate the requests from the single requestor. These queues or topics are also only available while the requestor is alive with a session to the reply.
Such an implementation with a temporary queue or topic does not make sense in Kafka. I have actually seen enterprises trying to do this. Kafka does not work like that. The consequence was way too many partitions and topics in the Kafka cluster. Scalability and performance issues were the consequence.
Asynchronous Data Streaming (Apache Kafka)
Data streaming continuously processes ingested events from data sources. Such data should be processed incrementally using stream processing techniques without having access to all the data.
The asynchronous communication paradigm is like message queues. Contrary to message queues, data streaming provides long-term storage of events and replayability of historical information. The consequence is a true decoupling between producers and consumers. In most Apache Kafka deployments, several producers and consumers with very different communication paradigms and latency capabilities send and read events.
Apache Kafka does not provide request-response APIs built-in. This is not necessarily a bad thing, as some people think. Data streaming provides different design patterns. That’s the main reason for this blog post! Let’s explore trade-offs of the request-response pattern in messaging systems and understand alternative approaches that suit better into a data streaming world. But this post also explores how to implement asynchronous or synchronous request-reply with Kafka.
But keep in mind: Don’t re-use your “legacy knowledge” about HTTP and MQ and try to re-build the same patterns with Apache Kafka. Having said this, request-response is possible with Kafka, too. More on this in the following sections.
Request-Reply vs. CQRS and Event Sourcing
CQRS (Command Query Responsibility Segregation) states that every method should either be a command that performs an action or a query that returns data to the caller, but not both. Services become truly decoupled from each other.
Martin Fowler has a nice diagram for CQRS:
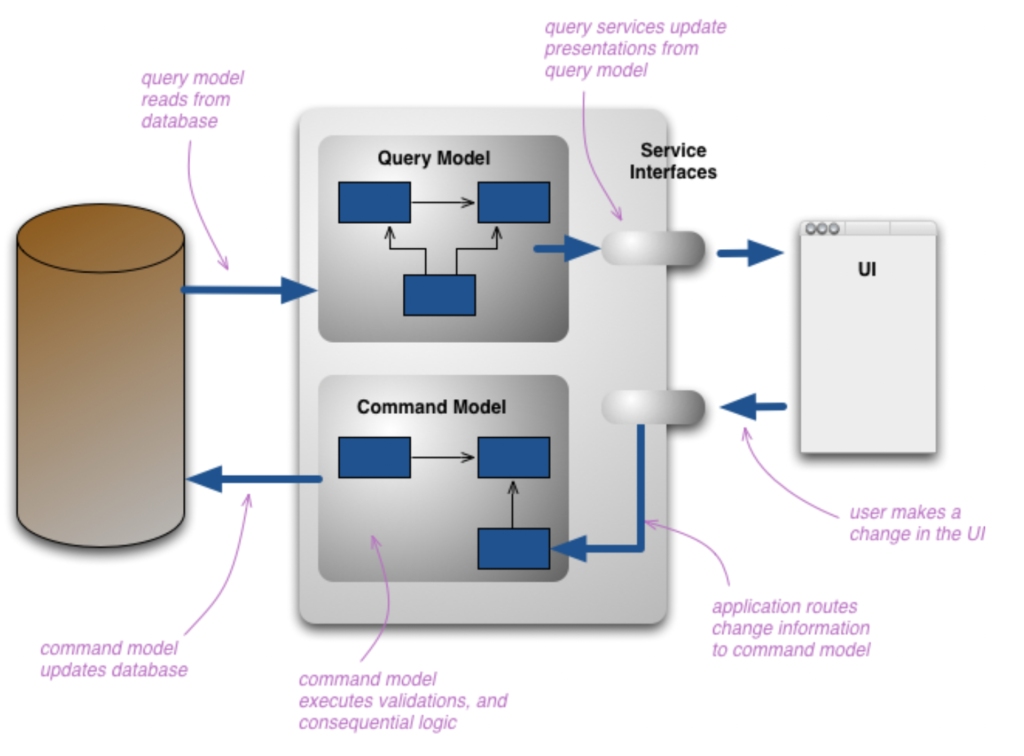
Event sourcing is an architectural pattern in which entities do not track their internal state using direct serialization or object-relational mapping, but by reading and committing events to an event store.
When event sourcing is combined with CQRS and domain-driven design, aggregate roots are responsible for validating and applying commands (often by having their instance methods invoked from a Command Handler) and then publishing events.
With CQRS, the state is updated against every relevant event message. Therefore, the state is always known. Querying the state that is stored in the materialized view (for example, a KTable in Kafka Streams) is efficient. With request-response, the server must calculate or determine the state of every request. With CQRS, it is calculated/updated only once regardless of the number of state queries at the time the relevant occurs.
These principles fit perfectly into the data streaming world. Apache Kafka is a distributed storage that appends incoming events to the immutable commit log. True decoupling and replayability of events are built into the Kafka infrastructure out-of-the-box. Most modern microservice architectures with domain-driven design are built with Apache Kafka, not REST or MQ.
Don’t use Request-Response in Kafka if not needed!
If you build a modern enterprise architecture and new applications, apply the natural design patterns that work best with the technology. Remember: Data streaming is a different technology than web services and message queues! CQRS with event sourcing is the best pattern for most use cases in the Kafka world:
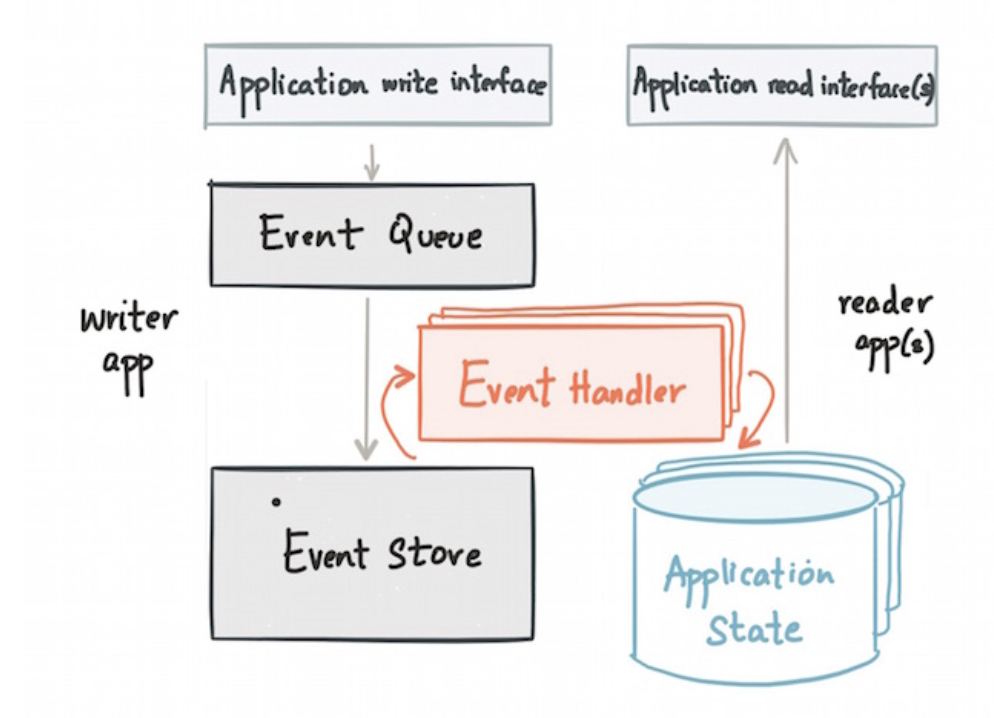
Do not use the request-response concept with Kafka if you do not really have to! Kafka was built for streaming data and true decoupling between various producers and consumers.
This is true even for transactional workloads. A transaction does NOT need synchronous communication. The Kafka API supports mission-critical transactions (although it is asynchronous and distributed by nature). Think about making a bank payment. It is never synchronous, but a complex business process with many independent events within and across organizations.
Synchronous vs. Asynchronous Request-Response with Apache Kafka
After I explained that request-response should not be the first idea when building a new Kafka application, it does not mean it is not possible. And sometimes, it is the better, simpler, or faster approach to solve a problem. Hence, let’s look at examples of synchronous and asynchronous request-response implementations with Kafka.
The request-reply pattern can be implemented with Kafka. But differently. Trying to do it like in a JMS message broker (with temporary queues etc.) will ultimately kill the Kafka cluster (because it works differently). Nevertheless, the used concepts are the same under the hood as in the JMS API, like a correlation ID.
Asynchronous Request-Response with Apache Kafka
ListenableFuture that is asynchronously populated with the result (or an exception, for a timeout). The result also has a sendFuture property, which is the result of calling KafkaTemplate.send(). You can use this future to determine the result of the send operation.Synchronous Request-Response with Apache Kafka
Another excellent DZone article talks about synchronous request/reply using Spring Kafka templates. The example shows a Kafka service to calculate the sum of two numbers with synchronous request-response behavior to return the result:
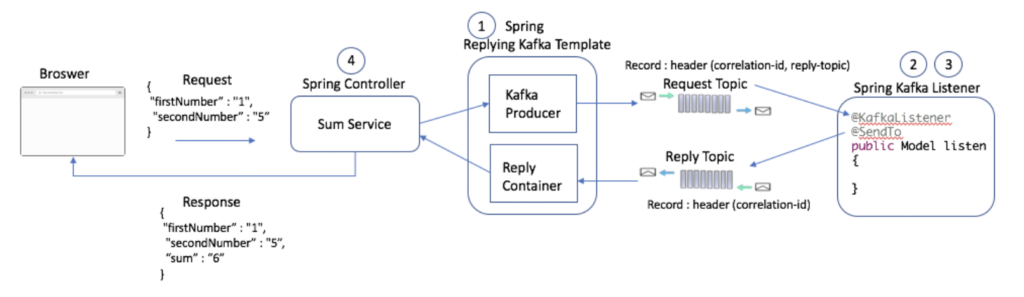
Spring automatically sets a correlation ID in the producer record. This correlation ID is returned as-is by the @SendTo annotation at the consumer end.
Check out the DZone post for the complete code example.
The Spring documentation for Kafka Templates has a lot of details and code examples about the Request/Reply pattern for Kafka. Using Spring, the request/reply pattern is pretty simple to implement with Kafka. If you are not using Spring, you can learn how to do request-reply with Kafka in your framework. That’s the beauty of open-source…
Combination of Data Streaming and REST API
Apache Kafka and API Management
A very common approach is to implement applications in real-time at scale with the Kafka ecosystem, but then put an API Management layer on top to expose the events as API to the outside world (either another internal business domain or a B2B 3rd party application).
Here is an example of connecting SAP data. SAP has tens of options for integrating with Kafka, including Kafka Connect connectors, REST / HTTP, proprietary API, or 3rd party middleware.
No matter how you get data into the streaming data hub, on the right side, the Kafka REST API is used to expose events via HTTP. An API Management solution handles the security and monetization/billing requirements on top of the Kafka interface:
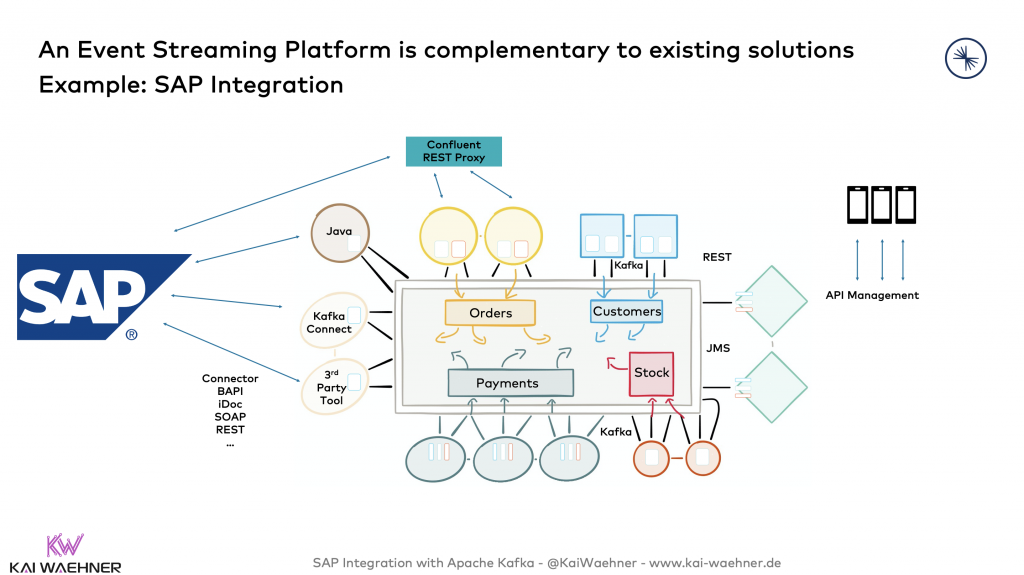
Read more about this discussion in the blog post “Apache Kafka and API Management / API Gateway – Friends, Enemies or Frenemies?“. It covers the relation between Apache Kafka and API Management platforms like Kong, MuleSoft Anypoint, or Google’s Apigee.
Stream Exchange for Internal and External Data Sharing with Apache Kafka
After discussing the relationship between APIs, request-response communication, and Kafka, let’s explore a significant trend in the market: Data Mesh (the buzzword) and stream exchange for real-time data sharing (the problem solver).
Data Mesh is a new architecture paradigm that gets a lot of buzz these days. No single technology is the perfect fit to build a Data Mesh. An open and scalable decentralized real-time platform like Apache Kafka is often the heart of the Data Mesh infrastructure, complemented by many other data platforms to solve business problems.
Stream-native data sharing instead of using request-response and REST APIs in the middle is the natural evolution for many use cases:
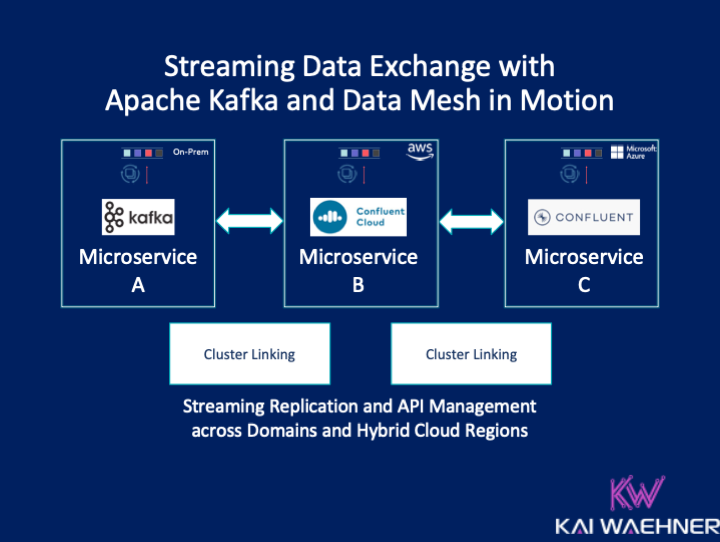
Learn more in the post “Streaming Data Exchange with Kafka and a Data Mesh in Motion“.
Use Data Streaming and Request-Response Together!
Most architectures need request-response for point-to-point communication (e.g., between a server and mobile app) and data streaming for continuous data processing.
Synchronous and asynchronous request-response communication can be implemented with Apache Kafka. However, CQRS and event sourcing is the better and more natural approach for data streaming most times. Understand the different options and their trade-offs, and use the right tool (in this case, the correct design pattern) for the job.
What is your strategy for using request-response with data streaming? How do you implement the communication in your Apache Kafka applications? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
