
Good data quality is one of the most critical requirements in decoupled architectures, like microservices or data mesh. Apache Kafka became the de facto standard for these architectures. But Kafka is a dumb broker that only stores byte arrays. The Schema Registry enforces message structures. This blog post looks at enhancements to leverage data contracts for policies and rules to enforce good data quality on field-level and advanced use cases like routing malicious messages to a dead letter queue.

From point-to-point and spaghetti to decoupled microservices with Apache Kafka
Point-to-point HTTP / REST APIs create tightly couple services. Data lakes and lakehouses enforce a monolithic architecture instead of open-minded data sharing and choice of the best technology for a problem. Hence, Apache Kafka became the de facto standard for microservice and data mesh architectures. And data streaming with Kafka complementary (not competitive!) to APIs, data lakes / lakehouses, and other data platforms.
What makes Apache Kafka so popular
A scalable and decoupled architecture as a single source of record for high-quality, self-service access to real-time data streams, but also batch and request-response communication.
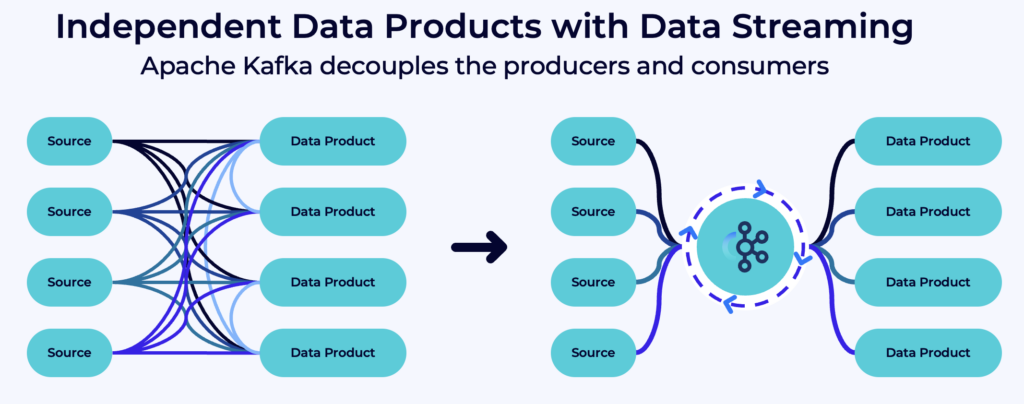
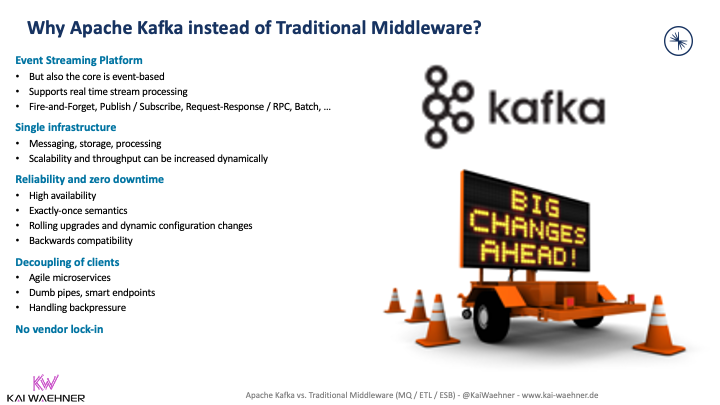
Difference between Kafka and ETL / ESB / iPaaS
Enterprise integration is more challenging than ever before. The IT evolution requires the integration of more and more technologies. Companies deploy applications across the edge, hybrid, and multi-cloud architectures.
Point-to-point integration is not good enough. Traditional middleware such as MQ, ETL, ESB does not scale well enough or only processes data in batch instead of real-time. Integration Platform as a Service (iPaaS) solutions are cloud-native but only allow point-to-point integration.
Apache Kafka is the new black for integration projects. Data streaming is a new software category.
Domain-driven design, microservices, data mesh…
The approaches use different principles and best practices. But reality is that the key for a long-living and flexible enterprise architecture is decoupled, independent applications. However, these applications need to share data in good quality with each other.
Apache Kafka shines here. It decouples applications because of its event store. Consumers don’t need to know producers. Domains build independent applications with its own technologies, APIs and cloud services:
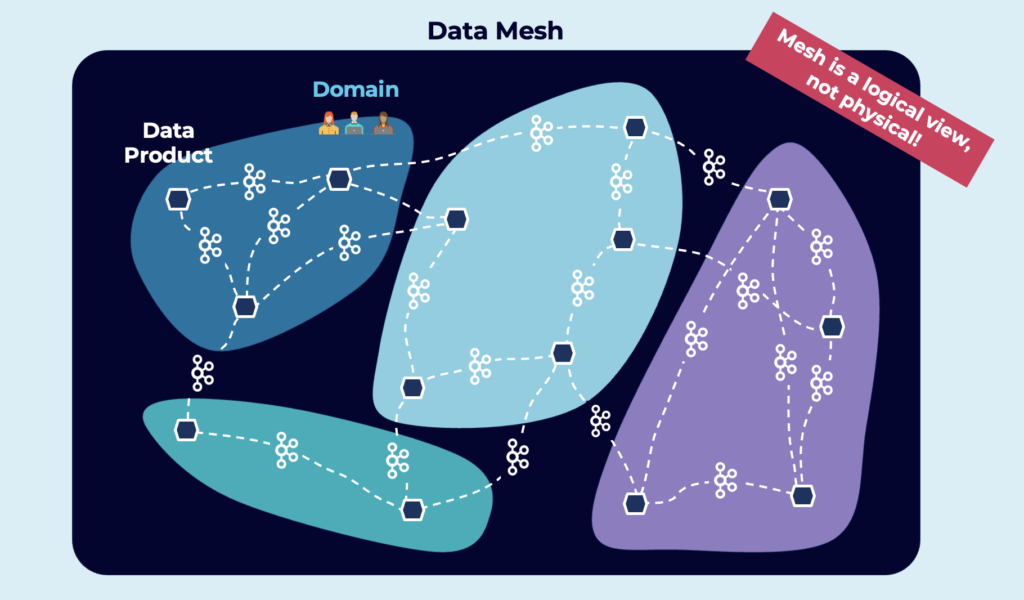
Replication between different Kafka clusters enables a global data mesh across data centres and multiple cloud providers or regions. But unfortunately, Apache Kafka itself misses data quality capabilities. That’s where the Schema Registry comes into play.
The need for good data quality and data governance in Kafka Topics
To ensure data quality in a Kafka architecture, organizations need to implement data quality checks, data cleansing, data validation, and monitoring processes. These measures help in identifying and rectifying data quality issues in real time, ensuring that the data being streamed is reliable, accurate, and consistent.
Why you want good data quality in Kafka messages
Data quality is crucial for most Kafka-based data streaming use cases for several reasons:
- Real-time decision-making: Data streaming involves processing and analyzing data as it is generated. This real-time aspect makes data quality essential because decisions or actions based on faulty or incomplete data can have immediate and significant consequences.
- Data accuracy: High-quality data ensures that the information being streamed is accurate and reliable. Inaccurate data can lead to incorrect insights, flawed analytics, and poor decision-making.
- Timeliness: In data streaming, data must be delivered in a timely manner. Poor data quality can result in delays or interruptions in data delivery, affecting the effectiveness of real-time applications.
- Data consistency: Inconsistent data can lead to confusion and errors in processing. Data streaming systems must ensure that data adheres to a consistent schema and format to enable meaningful and accurate analysis. No matter if a producer or consumer uses real-time data streaming, batch processing, or request-response communication with APIs.
- Data integration: Data streaming often involves combining data from various sources, such as sensors, databases, and external feeds. High-quality data is essential for seamless integration and for ensuring that data from different sources can be harmonized for analysis.
- Regulatory compliance: In many industries, compliance with data quality and data governance regulations is mandatory. Failing to maintain data quality in data streaming processes can result in legal and financial repercussions.
- Cost efficiency: Poor data quality can lead to inefficiencies in data processing and storage. Unnecessary processing of low-quality data can strain computational resources and lead to increased operational costs.
- Customer satisfaction: Compromised data quality in applications directly impacts customers, it can lead to dissatisfaction, loss of trust, and even attrition.
Rules engine and policy enforcement in Kafka Topics with Schema Registry
Confluent designed the Schema Registry to manage and store the schemas of data that are shared between different systems in a Kafka-based data streaming environment. Messages from Kafka producers are validated against the schema.
The Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving your Avro, JSON Schema, and Protobuf schemas. It stores a versioned history of all schemas based on a specified subject name strategy, provides multiple compatibility settings, and allows evolution of schemas according to the configured compatibility settings and expanded support for these schema types.
Schema Registry provides serializers that plug into Apache Kafka clients that handle schema storage and retrieval for Kafka messages that are sent in any of the supported formats.
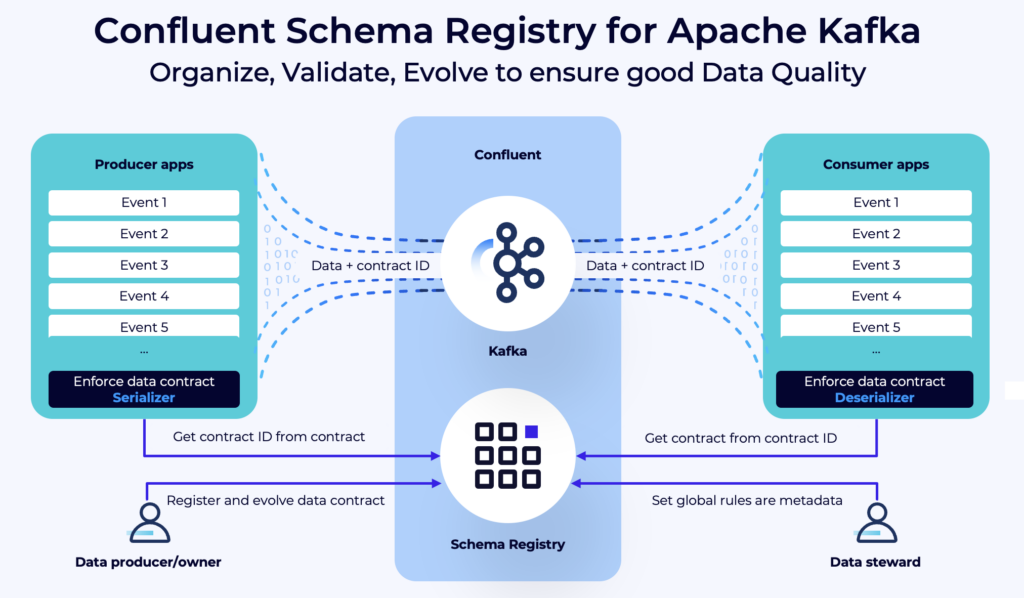
Schema Registry is available on GitHub under the Confluent Community License that allows deployment in production scenarios with no licensing costs. It became the de facto standard for ensuring data quality and governance in Kafka projects across all industries.
Enforcing the message structure as the foundation of good data quality
Confluent Schema Registry enforces message structure by serving as a central repository for schemas in a Kafka-based data streaming ecosystem. Here’s how it enforces message structure and rejects invalid messages:
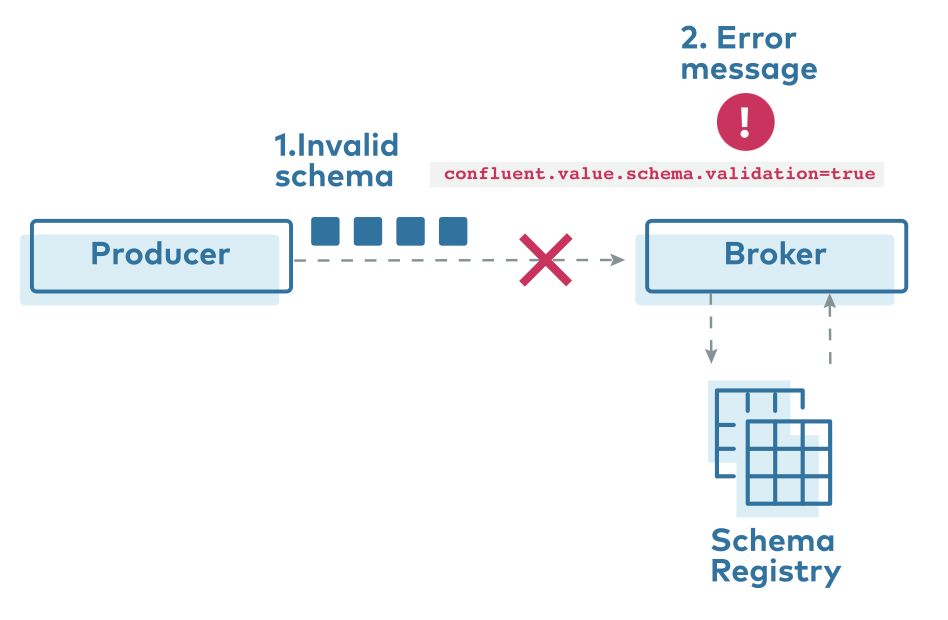
Data messages produced by Kafka producers must adhere to the registered schema. A message is rejected if a message doesn’t match the schema. This behaviour ensures that only well-structured data are published and processes.
Schema Registry even supports schema evolution for data interoperability using different schema versions in producers and consumers. Find a detailed explanation and the limitations in the Confluent documentation.
Validation of schemas happens on the client side in Schema Registry. This is not good enough for some scenarios, like regulated markets, where the infrastructure provider cannot trust each data producer. Hence, Confluent’s commercial offering added broker-side schema validation.
Attribute-based policies and rules in data contracts
The validation of message schema is a great first step. However, many use cases require schema validation and policy enforcement on field level, i.e. validating each attribute of the message by itself with custom rules. Welcome to Data Contracts:
Disclaimer: The following add-on for Confluent Schema Registry is only available for Confluent Platform and Confluent Cloud. If you use any other Kafka service and schema registry, take this solution as an inspiration for building your own data governance suite – or migrate to Confluent 🙂
Data contracts support various rules, including data quality rules, field-level transformations, event-condition-action rules, and complex schema evolution. Look at the Confluent documentation “Data Contracts for Schema Registry” to learn all the details.
Data contracts and data quality rules for Kafka messages
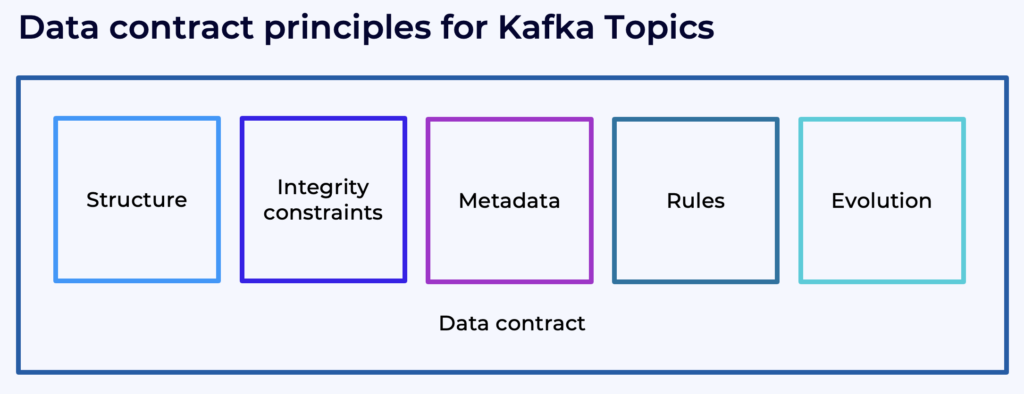
As described in the Confluent documentation, a data contract specifies and supports the following aspects of an agreement:
- Structure: This is the part of the contract that is covered by the schema, which defines the fields and their types.
- Integrity constraints: This includes declarative constraints or data quality rules on the domain values of fields, such as the constraint that an age must be a positive integer.
- Metadata: Metadata is additional information about the schema or its constituent parts, such as whether a field contains sensitive information. Metadata can also include documentation for a data contract, such as who created it.
- Rules or policies: These data rules or policies can enforce that a field that contains sensitive information must be encrypted, or that a message containing an invalid age must be sent to a dead letter queue.
- Change or evolution: This implies that data contracts are versioned, and can support declarative migration rules for how to transform data from one version to another, so that even changes that would normally break downstream components can be easily accommodated.
Example: PII data enforcing encryption and error-handling with a dead letter queue
One of the built-in rule types is Google Common Expression (CEL), which supports data quality rules.
Here is an example where a specific field is tagged as PII data. Rules can enforce good data quality or encryption of an attribute like the credit card number:
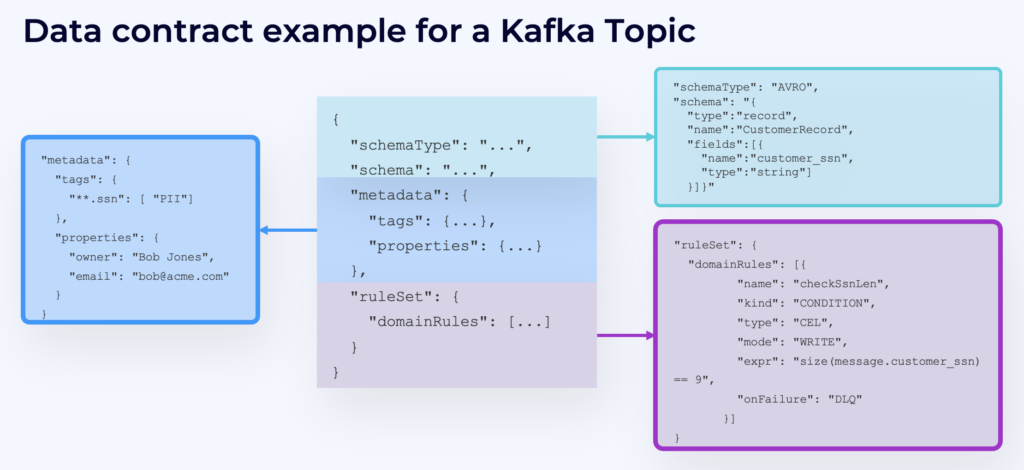
You can also configure advanced routing logic. For instance, error handling: If the expression “size(message.id) == 9” is not validated, then the streaming platform forwards the message to a dead letter queue for further processing with the configuration: “dlq.topic”: “bad-data”.
Dead letter queue (DLQ) is its own complex (but very important) topic. Check out the article “Error Handling via Dead Letter Queue in Apache Kafka” to learn from real-world implementations of Uber, CrowdStrike, Santander Bank, and Robinhood.
Data contracts as a foundation for new data streaming products and integration with Apache Flink
Schema Registry should be the foundation of any Kafka project. Data contracts enforce good data quality and interoperability between independent microservices. Each business unit and its data products can choose any technology or API. But data sharing with others works only with good (enforced) data quality.
No matter if you use Confluent Cloud or not, you can learn from this SaaS offering how schemas and data contracts enable data consistency and faster time to market for innovation. Products like Data Catalog, Data Lineage, Confluent Stream Sharing, or the out-of-the-box integration with serverless Apache Flink rely on a good internal data governance strategy with schemas and data contracts.
Do you already leverage data contracts in your Confluent environment? If you are not a Confluent user, how do you solve data consistency issues and enforce good data quality? Let’s connect on LinkedIn and discuss it! Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter.
