Policy Enforcement and Data Quality for Apache Kafka with Schema Registry
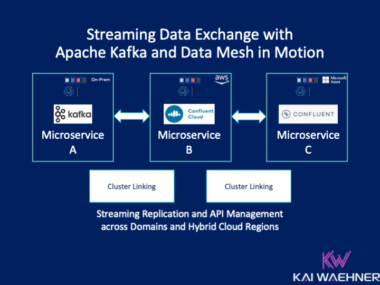
Good data quality is one of the most critical requirements in decoupled architectures, like microservices or data mesh. Apache Kafka became the de facto standard for these architectures. But Kafka is a dumb broker that only stores byte arrays. The Schema Registry enforces message structures. This blog post looks at enhancements to leverage data contracts for policies and rules to enforce good data quality on field-level and advanced use cases like routing malicious messages to a dead letter queue.