
Stream processing has existed for decades. However, it really kicks off in the 2020s thanks to the adoption of open source frameworks like Apache Kafka and Flink. Fully managed cloud services make it easy to configure and deploy stream processing in a cloud-native way; even without the need to write any code. This blog post explores the past, present and future of stream processing. The discussion includes various technologies and cloud services, low code/ no code trade-offs, outlooks into the support of machine learning and GenAI, streaming databases, and the integration between data streaming and data lakes with Apache Iceberg.
In December 2023, the research company proved that data streaming is a new software category and not just yet another integration or data platform. Forrester published “The Forrester Wave™: Streaming Data Platforms, Q4 2023“. Get free access to the report here. The leaders are Microsoft, Google and Confluent, followed by Oracle, Amazon, Cloudera, and a few others. A great time to review the past, present and future of stream processing as a key component in a data streaming architecture.
The Past of Stream Processing: The Move from Batch to Real-Time
The evolution of stream processing began as industries sought more timely insights from their data. Initially, batch processing was the norm. Data was collected over a period, stored, and processed at intervals. This method, while effective for historical analysis, proved inefficient for real-time decision-making.
In parallel to batch processing, message queues were created to provide real-time communication for transactional data. Message Brokers like IBM MQ or TIBCO EMS were a common way to decouple applications. Applications send data and receive data in an event-driven architecture without worrying about if the recipient was ready, how to handle backpressure, etc. The stream processing journey began.

Stream Processing is a Journey Over Decades…
… and we are still in a very early stage at most enterprises. Here is an excellent timeline of TimePlus about the journey of stream processing open source frameworks, proprietary platforms and SaaS cloud services:
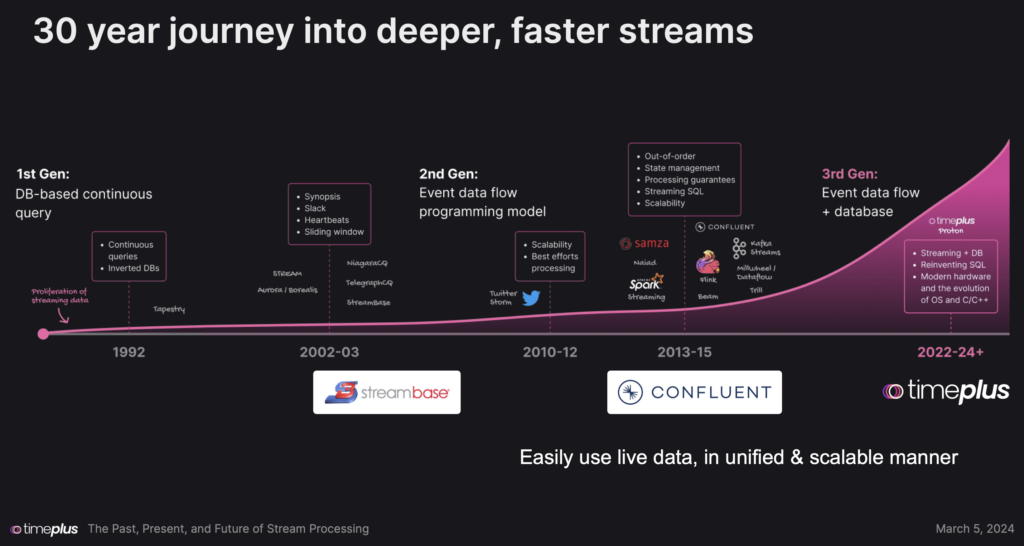
The stream processing journey started decades ago with research and first purpose-built proprietary products for specific use cases like stock trading.
Open source stream processing frameworks emerged during the big data and Hadoop era to make at least the ingestion layer a bit more real-time. Today, most enterprises at least get started understanding the value of stream processing for analytical and transactional use cases across industries. The cloud is a fundamental change as you can start streaming and processing data with a button click leveraging fully managed SaaS and simple UIs (if you don’t want to operate infrastructure or write low-level source code).
TIBCO StreamBase, Software AG Apama, IBM Streams
The advent of message queue technologies like IBM MQ and TIBCO EMS moved many critical applications to real-time message brokers. Real-time messaging enabled the consumption of data in real-time to store it in a database, mainframe, or application for further processing.
However, only true stream processing capabilities included in tools like TIBCO StreamBase, Software AG Apama or IBM (InfoSphere) Streams marked a significant shift towards real-time data processing. These products enabling businesses to react to information as it arrived by processing and correlating the data in motion.
Open Source Event Streaming with Apache Kafka
The actual significant change for stream processing came with introducing Apache Kafka, a distributed streaming platform that allowed for high-throughput, fault-tolerant handling of real-time data feeds. Kafka, alongside other technologies like Apache Flink, revolutionized the landscape by providing the tools necessary to move from batch to real-time stream processing seamlessly.
The adoption of open source technologies changed all industries. Openness, flexibility, and community-driven development enabled easier influence on the features and faster innovation.
Over 100.000 organizations use Apache Kafka. The massive adoption came from a unique combination of capabilities: Messaging, storage, data integration, stream processing, all in one scalable and distributed infrastructure.
Various open source stream processing engines emerged. Kafka Streams was added to the Apache Kafka project. Other examples include Apache Storm, Spark Streaming, and Apache Flink.
The Present of Stream Processing: Architectural Evolution and Mass Adoption
The fundamental change to processing data in motion has enabled the development of data products and data mesh. Decentralizing data ownership and management with domain-driven design and technology-independent microservices promotes a more collaborative and flexible approach to data architecture. Each business unit can choose its own technology, API, cloud service, and communication paradigm like real-time, batch, or request-response.
From Lambda Architecture to Kappa Architecture
Today, stream processing is at the heart of modern data architecture, thanks in part to the emergence of the Kappa architecture. This model simplifies the traditional Lambda Architecture by using a single stream processing system to handle both real-time and historical data analysis, reducing complexity and increasing efficiency.
Lambda architecture with separate real-time and batch layers:

Kappa architecture with a single pipeline for real-time and batch processing:
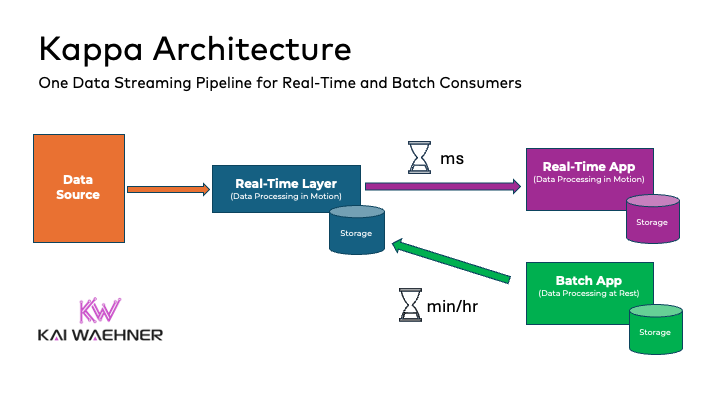
For more details about the pros and cons of Kappa vs. Lambda, check out my “Kappa Architecture is Mainstream Replacing Lambda“. It explores case studies from Uber, Twitter, Disney and Shopify.
Kafka Streams and Apache Flink Become Mainstream
Apache Kafka has become synonymous with building scalable and fault-tolerant streaming data pipelines. Kafka facilitating true decoupling of domains and applications makes it integral to microservices and data mesh architectures.
Plenty of stream processing frameworks, products, and cloud services emerged in the past years. This includes open source frameworks like Kafka Streams, Apache Storm, Samza, Flume, Apex, Flink, Spark Streaming, and cloud services like Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics. The “Data Streaming Landscape 2024” gives an overview of relevant technologies and vendors.
Apache Flink seems to become the de facto standard for many enterprises (and vendors). The adoption is like Kafka four years ago:
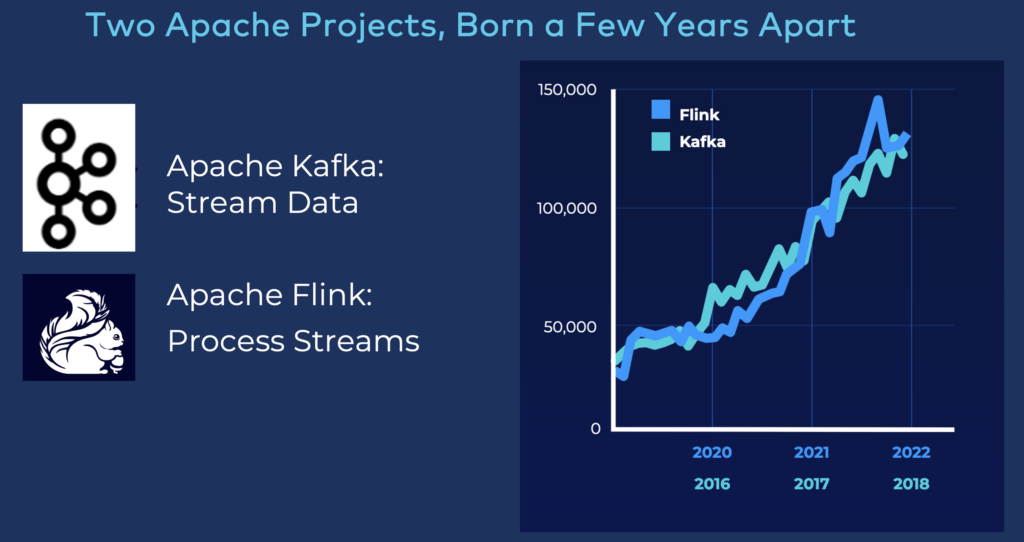
This does not mean other frameworks and solutions are bad. For instance, Kafka Streams is complementary to Apache Flink, as it suites different use cases.
No matter what technology enterprises choose, the mass adoption of stream processing is in progress right now. This includes modernizing existing batch processes AND building innovative new business models that only work in real time. As a concrete example, think about ride-hailing apps like Uber, Lyft, FREENOW, Grab. They are only possible because events are processed and correlated in real-time. Otherwise, everyone would still prefer a traditional taxi.
Stateless and Stateful Stream Processing
In data streaming, stateless and stateful stream processing are two approaches that define how data is handled and processed over time:
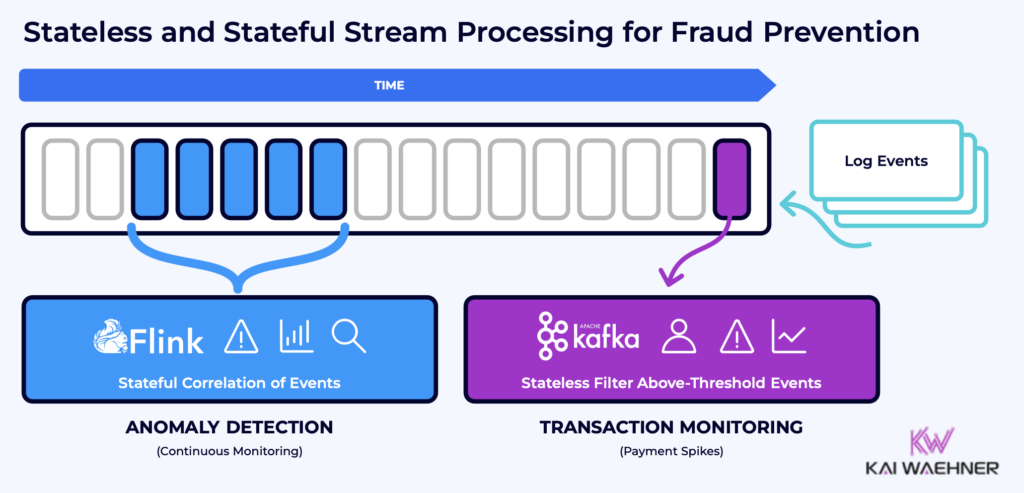
The choice between stateless and stateful processing depends on the specific requirements of the application, including the nature of the data, the complexity of the processing needed, and the performance and scalability requirements.
Stateless Stream Processing
Stateless Stream Processing refers to the handling of each data point or event independently from others. In this model, the processing of an event does not depend on the outcomes of previous events or require keeping track of the state between events. Each event is processed based on the information it contains, without the need for historical context or future data points. This approach is simpler and can be highly efficient for tasks that don’t require knowledge beyond the current event being processed.
The implementation could be a stream processor (like Kafka Streams or Flink), functionality in a connector (like Kafka Connect Single Message Transforms), or a Web Assembly (WASM) embedded into a streaming platform.
Stateful Stream Processing
Stateful Stream Processing involves keeping track of information (state) across multiple events to perform computations that depend on data beyond the current event. This model allows for more complex operations like windowing (aggregating events over a specific time frame), joining streams of data based on keys, and tracking sequences of events or patterns over time. Stateful processing is essential for scenarios where the outcome depends on accumulated knowledge or trends derived from a series of data points, not just on a single input.
The implementation is much more complex and challenging than stateless stream processing. A dedicated stream processing implementation is required. Dedicated distributed engines (like Apache Flink) handle stateful computionations, memory usage and scalability better than Kafka-native tools like Kafka Streams or KSQL (because the latter are bound to Kafka Topics).
Low Code, No Code, AND A Lot of Code!
No-code and low-code tools are software platforms that enable users to develop applications quickly and with minimal coding knowledge. These tools provide graphical user interfaces with drag-and-drop capabilities, allowing users to assemble and configure applications visually rather than writing extensive lines of code.
Common features and benefits of visual coding:
- Rapid Development: Both types of platforms significantly reduce development time, enabling faster delivery of applications.
- User-Friendly Interface: The graphical interface and drag-and-drop functionality make it easy for users to design, build, and iterate on applications.
- Cost Reduction: By enabling quicker development with fewer resources, these platforms can lower the cost of software creation and maintenance.
- Accessibility: They make application development accessible to a broader range of people, reducing the dependency on skilled developers for every project.
So far, the theory.
Disadvantages of Visual Coding Tools
Actually, StreamBase, Apama, et al., had great visual coding offerings. However, no-code / low-code tools have many drawbacks and disadvantages, too:
- Limited Customization and Flexibility: While these platforms can speed up development for standard applications, they may lack the flexibility needed for highly customized solutions. Developers might find it challenging to implement specific functionalities that aren’t supported out of the box.
- Dependency on Vendors: Using no-code/low-code platforms often means relying on third-party vendors for the platform’s stability, updates, and security. This dependency can lead to potential issues if the vendor cannot maintain the platform or goes out of business. And often the platform team is the bottleneck for implementing new business or integration logic.
- Performance Concerns: Applications built with no-code/low-code platforms may not be as optimized as those developed with traditional coding, potentially leading to lower performance or inefficiencies, especially for complex applications.
- Scalability Issues: As businesses grow, applications might need to scale up to support increased loads. No-code/low-code platforms might not always support this level of scalability or might require significant workarounds, affecting performance and user experience.
- Over-reliance on Non-Technical Users: While empowering citizen developers is a key advantage of these platforms, it can also lead to governance challenges. Without proper oversight, non-technical users might create inefficient workflows or data structures, leading to technical debt and maintenance issues.
- Cost Over Time: Initially, no-code/low-code platforms can reduce development costs. However, as applications grow and evolve, the ongoing subscription costs or fees for additional features and scalability can become significant.
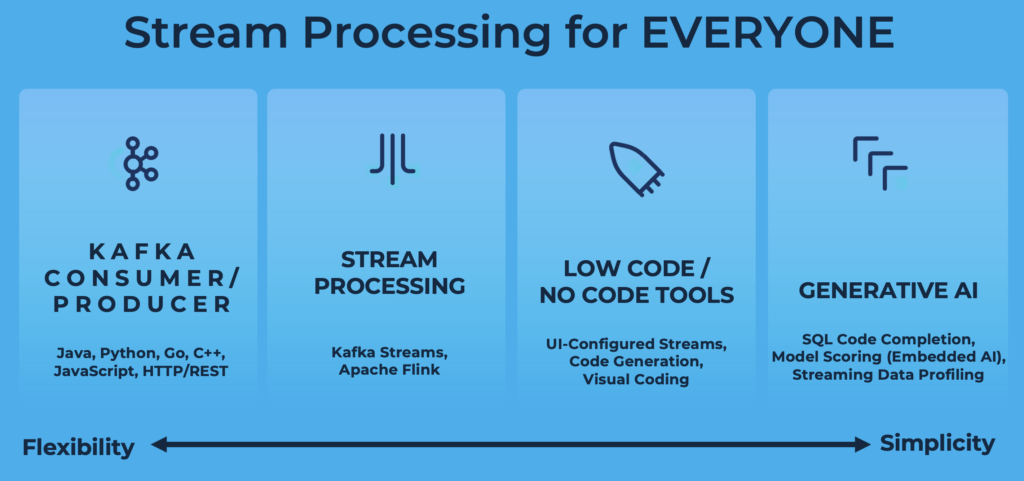
Flexibility is King: Stream Processing for Everyone!
Microservices, domain-driven design, data mesh… All these modern design approaches taught us to provide flexible enterprise architectures. Each business unit and persona should be able to choose its own technology, API, or SaaS. And no matter if you do real-time, near real-time, batch or request response communication.
Apache Kafka provides the true decoupling out-of-the-box. Therefore, low-code or now-code tools is an option. However, a data scientist, data engineer, software developer or citizen integrator can choose its own technology for stream processing.
The past, present and future of stream processing shows different frameworks, visual coding tools and even applied generative AI. One solution does NOT replace but complement the other alternatives:
The Future of Stream Processing: Serverless SaaS, GenAI and Streaming Databases
Stream processing is set to grow exponentially in the future, thanks to advancements in cloud computing, SaaS, and AI. Let’s explore the future of stream processing and look at the expected short, mid and long-term developments.
SHORT TERM: Fully Managed Serverless SaaS for Stream Processing
The cloud’s scalability and flexibility offer an ideal environment for stream processing applications, reducing the overhead and resources required for on-premise solutions. As SaaS models continue to evolve, stream processing capabilities will become more accessible to a broader range of businesses, democratizing real-time data analytics.
For instance, look at the serverless Flink Actions in Confluent Cloud. You can configure and deploy stream processing for use cases like deduplication or masking without any code:
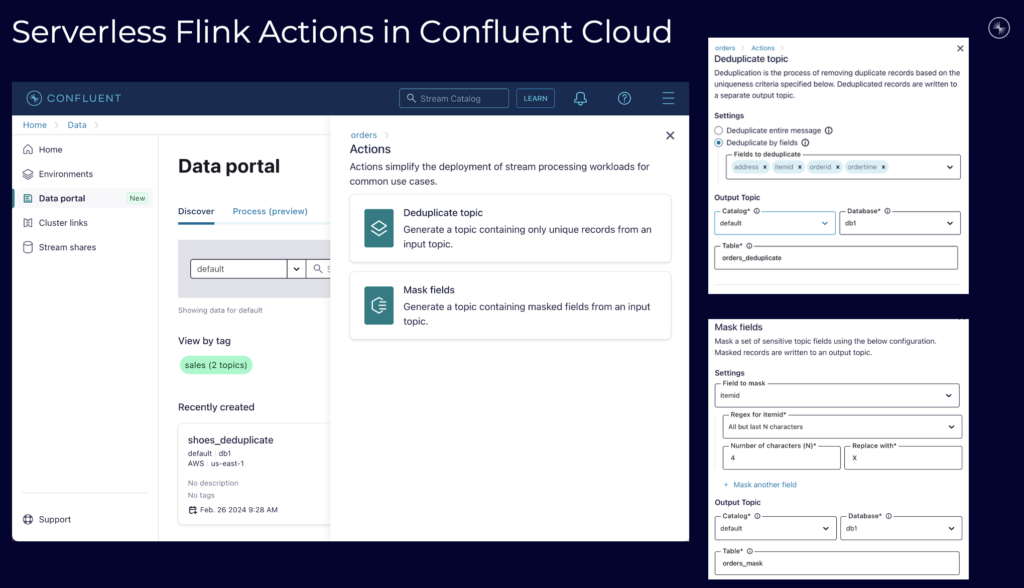
MID TERM: Automated Tooling and the Help of GenAI
Integrating AI and machine learning with stream processing will enable more sophisticated predictive analytics. This opens new frontiers for automated decision-making and intelligent applications while continuously processing incoming event streams. The full potential of embedding AI into stream processing has to be learned and implemented in the upcoming years.
For instance, automated data profiling is one instance of stream processing that GenAI can support significantly. Software tools analyze and understand the quality, structure, and content of a dataset without manual intervention as the events flow through the data pipeline in real-time. This process typically involves examining the data to identify patterns, anomalies, missing values, and inconsistencies. A perfect fit for stream processing!
Automated data profiling in the stream processor can provide insights into data types, frequency distributions, relationships between columns, and other metadata information crucial for data quality assessment, governance, and preparation for further analysis or processing.
MID TERM: Streaming Storage and Analytics with Apache Iceberg
Apache Iceberg is an open-source table format for huge analytic datasets that provides powerful capabilities in managing large-scale data in data lakes. Its integration with streaming data sources like Apache Kafka and analytics platforms, such as Snowflake, Starburst, Dremio, AWS Athena or Databricks, can significantly enhance data management and analytics workflows.
Integration between Streaming Data from Kafka and Analytics on Databricks or Snowflake using Apache Iceberg
Supporting the Apache Iceberg table format might be a crucial strategic move by streaming and analytics frameworks, vendors and cloud services. Here are some key benefits from the enterprise architecture perspective:
- Unified Batch and Stream Processing: Iceberg tables can serve as a bridge between streaming data ingestion from Kafka and doxwnstream analytic processing. By treating streaming data as an extension of a batch-based table, Iceberg enables a seamless transition from real time to batch analytics, allowing organizations to analyze data with minimal latency.
- Schema Evolution: Iceberg supports schema evolution without breaking downstream systems. This is useful when dealing with streaming data from Kafka, where the schema might evolve. Consumers can continue reading data using the schema they understand, ensuring compatibility and reducing the need for data pipeline modifications.
- Time Travel and Snapshot Isolation: Iceberg’s time travel feature allows analytics on data as it looked at any point in time, providing snapshot isolation for consistent reads. This is crucial for reproducible reporting and debugging, especially when dealing with continuously updating streaming data from Kafka.
- Cross-Platform Compatibility: Iceberg provides a unified data layer accessible by different compute engines, including those used by Databricks and Snowflake. This enables organizations to maintain a single copy of their data that is queryable across different platforms, facilitating a multi-tool analytics ecosystem without data silos.
LONG TERM: Transactional + Analytics = Streaming Database?
Streaming databases, like RisingWave or Materialize, are designed to handle real-time data processing and analytics. This offers a way to manage and query data that is continuously generated from sources like IoT devices, online transactions, and application logs. Traditional databases that are optimized for static data stored on disk. Instead, streaming databases are built to process and analyze data in motion. They provide insights almost instantaneously as the data flows through the system.
Streaming databases offer the ability to perform complex queries and analytics on streaming data, further empowering organizations to harness real-time insights.
The ongoing innovation in streaming databases will probably lead to more advanced, efficient, and user-friendly solutions, facilitating broader adoption and more creative applications of stream processing technologies.
Having said this, we are still in the very early stage. It is not clear yet when you really need a streaming database instead of a mature and scalable stream processor like Apache Flink. The future will show us and competition is great for innovation.
The Future of Stream Processing is Open Source and Cloud
The journey from batch to real-time processing has transformed how businesses interact with their data. The continued evolution couples technologies like Apache Kafka, Kafka Streams, and Apache Flink with the growth of cloud computing and SaaS. Stream processing will redefine the future of data analytics and decision-making.
As we look ahead, the future possibilities for stream processing are boundless, promising more agile, intelligent, and real-time insights into the ever-increasing streams of data.
If you want to learn more, listen to the following on-demand webinar about the past, present and future of stream processing with me joined by the two streaming industry veterans Richard Tibbets (founder of StreamBase) and Michael Benjamin (TimePlus). I had the please work with them for a few years at TIBCO where we deployed StreamBase at many Financial Services companies for stock trading and similar use cases:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
How does your stream processing journey look like? In which decade did you join? Or are you just learning with the latest open-source frameworks or cloud services? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
