The mainframe is not dead. It’s evolving and playing a strategic role in the real-time data landscape. IBM’s recent release of the z16 and now the z17 mainframe generations proves that these systems are far from obsolete. With powerful processors, embedded AI, built-in quantum-safe encryption, and cloud-native interfaces, today’s mainframes are built to meet modern enterprise needs. Especially in industries such as banking, insurance, telco, healthcare, and government, the mainframe still handles mission-critical workloads. At the same time, organizations face pressure to become more agile and data-driven. They need real-time access to data, fast integration across systems, and support for AI and advanced analytics. This is where data streaming with Apache Kafka and Flink becomes essential for mainframe integration.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including several success stories around IT modernization.
Why Data Streaming Is Essential for Modern Mainframe Architectures
Modern enterprises don’t just need to store and process data; they need to act on it as it happens. That’s why data streaming is at the center of mainframe modernization efforts.
Data Streaming with Apache Kafka and Apache Flink supports transactional workloads by enabling real-time event capture from mainframe systems like DB2, IMS, and IBM MQ. This allows downstream services to react to transactions instantly across fraud detection, trading platforms, or digital experiences. Unlike batch-based architectures, data streaming ensures that each change is available as a continuous stream, enabling near-instant responses and decisions.
At the same time, Kafka makes it easy to ingest mainframe data into analytics and AI platforms, both on-premises and in the cloud. Streaming data pipelines deliver fresh, trusted data to tools like Snowflake, Databricks, BigQuery, or AWS Sagemaker—powering everything from executive dashboards to generative AI applications.
Kafka is also a high-throughput integration backbone. It decouples producers and consumers, enforces schema governance, and connects legacy systems with microservices, cloud apps, and data products. For mainframe-heavy organizations, this means better agility, easier scaling, and more resilient operations.
In short, data streaming enables a modern, event-driven architecture without having to replace every legacy system at once. This is what makes it ideal for evolving the mainframe step by step, without disruption.
The next section explores architecture options for evolving mainframe environments using Apache Kafka: offloading, integration, and full replacement. Afterwards, real-world success stories from across industries, including Fidelity, RBC, Sun Life, Citizens Bank, DATEV, Alight, Krungsri, BNL, Lloyds Banking Group, OCC, and BEC—show how organizations use data streaming to reduce mainframe load, improve agility, and power digital innovation.
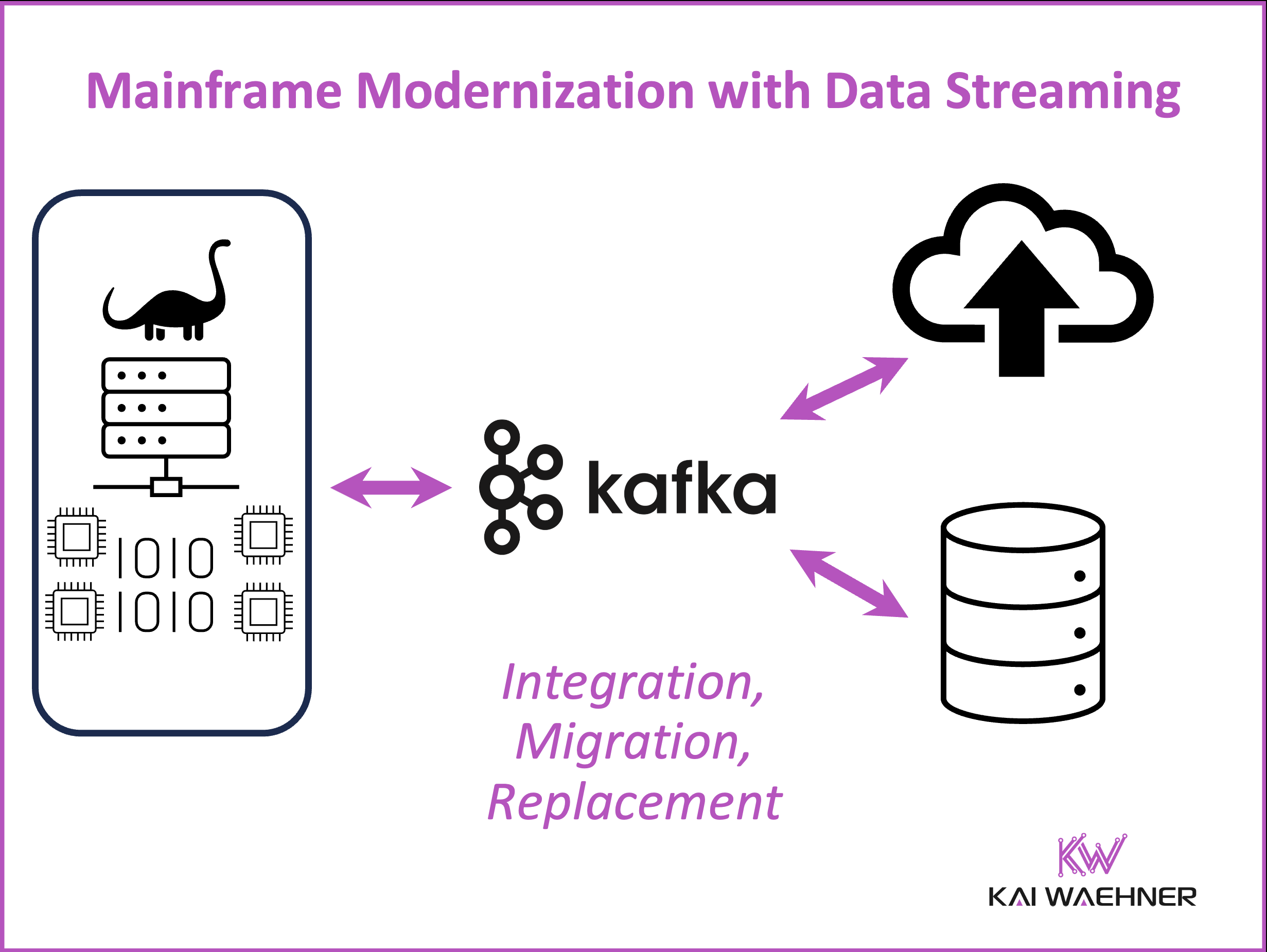
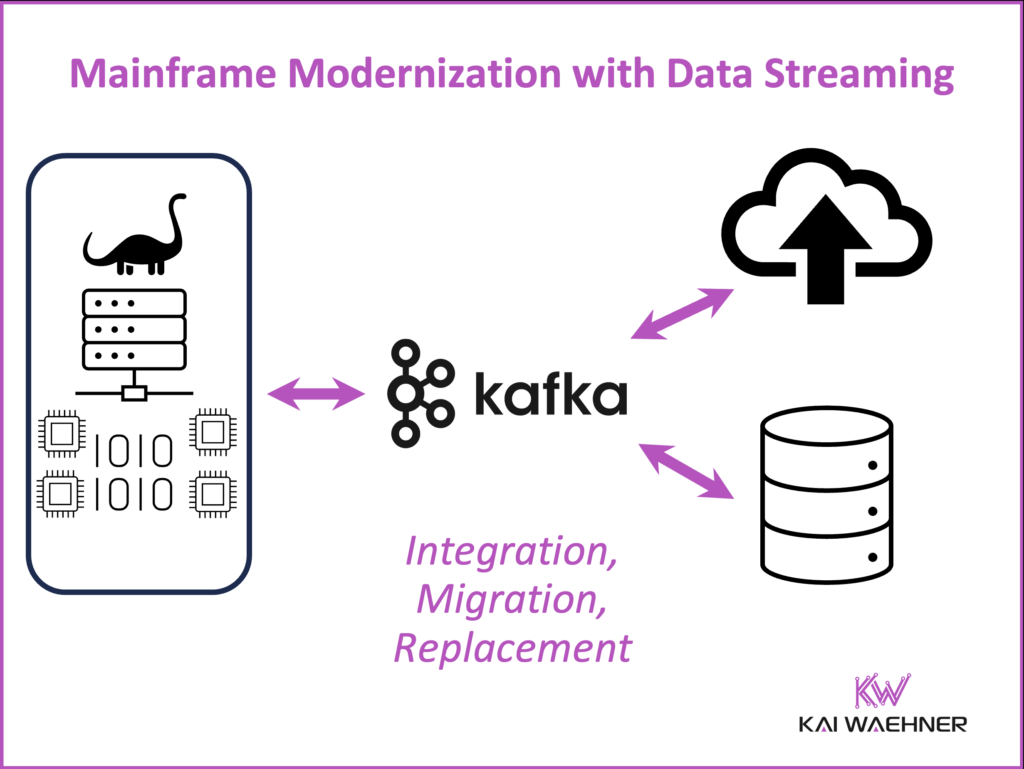
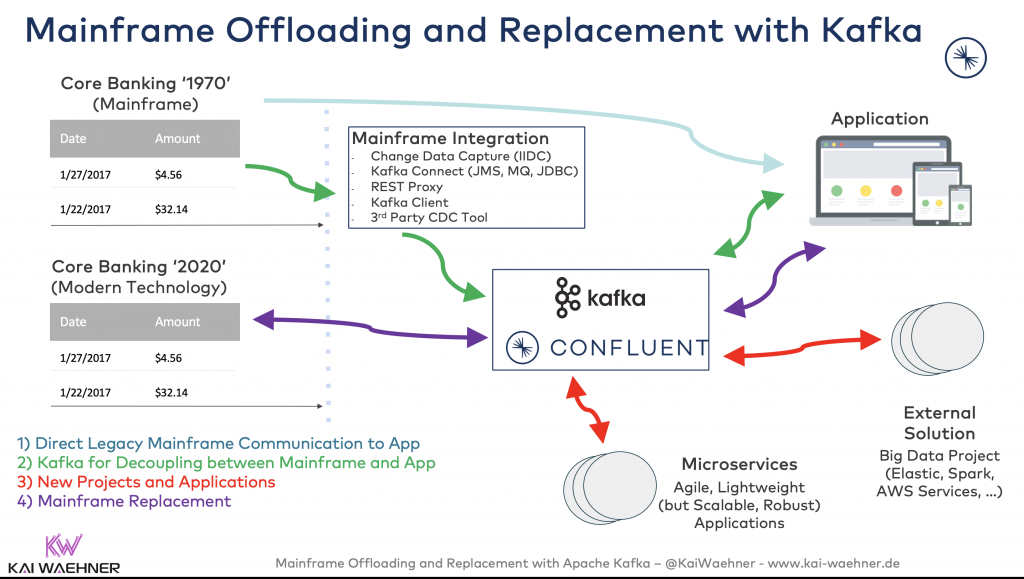
Three Mainframe Strategies with Apache Kafka: Offloading, Integration, and Replacement
In 2020, I published a deep technical guide on integrating Apache Kafka with mainframes. It outlined three core strategies to bring the mainframe into a modern, event-driven architecture: offloading, integration, and replacement.
Each approach has its own trade-offs. The right choice depends on the business goals, existing architecture, and regulatory constraints.
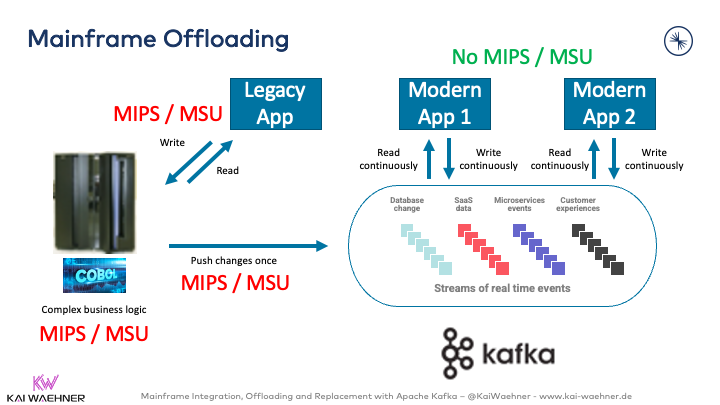
1. Mainframe Offloading
Mainframes are powerful—but expensive. Every CPU cycle counts. The offloading approach aims to reduce the operational load on the mainframe by shifting non-critical processing to cheaper, scalable infrastructure.
- How it works: Data is streamed from mainframe systems (DB2, IMS, MQ) to Kafka. New downstream applications in cloud or commodity servers consume this data for real-time analytics, reports, dashboards, or batch processing.
- Tools: Change Data Capture (CDC) tools like IBM IIDR, Precisely, or Qlik Replicate monitor DB2 or IMS databases and replicate changes to Kafka.
- Business value: Reduces MIPS usage, cuts costs, and enables faster data access for other business units without disrupting mainframe operations.
2. Mainframe Integration
The mainframe remains in place but is seamlessly integrated into a modern real-time data architecture.
- How it works: Kafka Connect with connectors for IBM MQ, Data Integration tools, or custom applications creates bidirectional data flows. Kafka acts as the central nervous system between mainframe apps and cloud-native services.
- Use cases: Real-time fraud detection, customer-facing applications, regulatory reporting, and digital self-service platforms.
- Business value: Keeps trusted mainframe systems intact while unlocking real-time capabilities across the enterprise.
Bi-Directional Communication between Mainframe and Modern Applications:
In many enterprises, core mainframe applications are critical; but completely off-limits. You can’t change the code, expose new APIs, or modernize the application itself. Yet the business still demands real-time integration and transactional writes back to the mainframe.
The solution:
To write data into these untouchable legacy systems, non-invasive integration techniques are essential. Proven methods include terminal emulation (e.g., 3270 screen automation), robotic process automation (RPA), or structured file-based handoffs using flat files like CSV. These approaches avoid changing the mainframe while enabling reliable data exchange.
Example:
Some mainframe systems can only ingest data in batch mode from CSV files dropped into specific datasets; originally generated by another legacy system. In such cases, the modern approach is to build a new application that mirrors the same CSV output format to maintain compatibility. At the same time, this modern system can also expose the data via APIs or Kafka streams for downstream analytics, digital services, or real-time monitoring—bridging the gap between old and new without touching the mainframe.
3. Mainframe Replacement
This is the most ambitious and risky option. Some organizations choose to retire the mainframe entirely and migrate applications to modern microservice architectures.
- How it works: Kafka replaces legacy messaging, and services are rebuilt in microservices, using modern databases, stream processing, and AI.
- Challenges: Complexity, data consistency, application rewrites, and cultural resistance.
- Business value: Long-term agility, full cloud-native architecture, and easier hiring and tooling—but only feasible when business drivers justify the cost and risk.
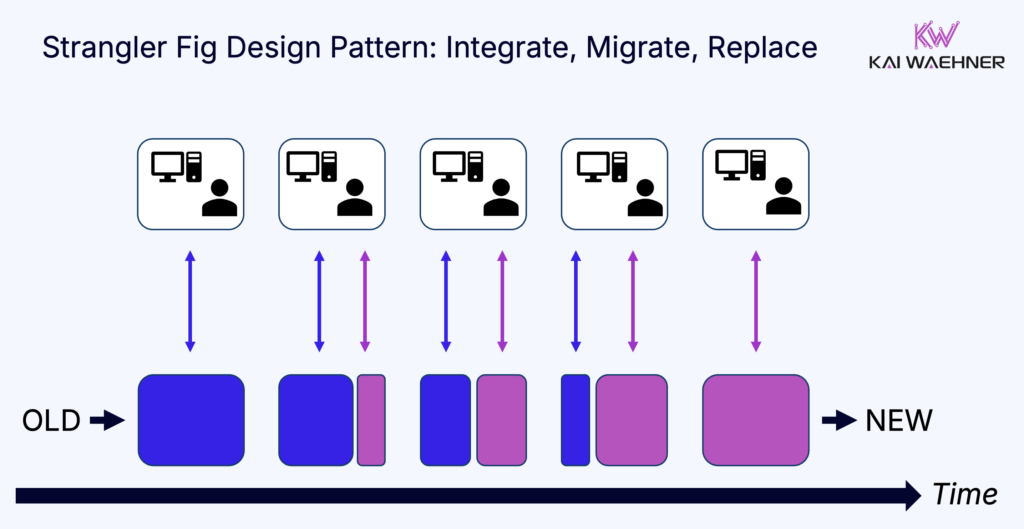
The Strangler Fig pattern is often the best approach here. It allows teams to incrementally replace mainframe components with modern services, reducing risk while maintaining business continuity throughout the migration.
Data streaming with Kafka plays a central role for the Strangler Fig pattern by enabling real-time replication of data from legacy systems to new services, ensuring both environments stay in sync during the transition.
Integration Technologies: Kafka Connect, IBM MQ, and Change Data Capture (CDC)
Successful integration depends on the right tooling. While CDC is typically the preferred approach, several alternatives exist—ranging from interface tables on DB2 and JDBC pull queries to direct HTTP request-response calls or even Kafka clients on the mainframe. In practice, most production environments rely on IBM IIDR or a commercial 3rd party CDC tool, followed closely by IBM MQ via Kafka Connect.
Change Data Capture (CDC) Tools
CDC extracts changes from mainframe databases such as DB2, IMS, or VSAM and streams them to Kafka in near real-time. Common tools:
- IBM InfoSphere Data Replication (IIDR)
- Precisely (formerly Syncsort)
- Qlik Replicate (formerly Attunity)
CDC minimizes impact on the source systems, keeps data fresh, and avoids the need for scheduled batch jobs or FTP transfers.
Kafka Connect with IBM MQ Connector
Kafka Connect enables scalable and reliable ingestion from mainframe-based IBM MQ systems. The IBM MQ Source Connector reads messages and pushes them into Kafka topics. The Sink Connector can also send messages back to MQ, supporting bidirectional integration when needed.
This enables systems like core banking, policy administration, or transaction processing to be included in a real-time architecture without touching the underlying COBOL logic.
Kafka Connect Deployed on the Mainframe
A breakthrough implementation comes from Confluent (data streaming vendor) and Fidelity (a global financial services company). Instead of deploying Kafka Connect off the mainframe, they chose to run Kafka Connect and the IBM MQ connector directly on the z/OS system.
The MQ Connect Worker runs on the mainframe under z/OS and uses a zIIP processor to improve efficiency and lower the cost of CPU usage.
This architecture delivers:
- Lower latency: No network hops between the connector and MQ.
- Higher throughput: Efficient message processing, ideal for large volumes.
- Cost optimization: Fewer moving parts, reduced infrastructure complexity.
This pattern is now being considered by other large enterprises seeking to tightly integrate Kafka with mainframe messaging while minimizing external dependencies.
Customer Success Stories for Mainframe and Data Streaming
Many leading organizations are using Apache Kafka and Confluent to extend the value of their mainframe systems while building a modern, event-driven architecture. By integrating mainframes with real-time streaming platforms, they reduce operational costs, improve data accessibility, and accelerate the delivery of digital products and services.
These success stories showcase how data streaming supports mainframe offloading, cloud migration, real-time analytics, and AI-powered applications—all while maintaining compliance, reliability, and performance at scale. Whether through stream processing, change data capture, or hybrid cloud integration, data streaming is enabling enterprises to modernize without disruption.
Fidelity Investments – Kafka Connect on z/OS for Real-Time Messaging with IBM MQ
Fidelity Investments runs a high-availability, active-active environment across mainframe and cloud. To enable real-time, bidirectional messaging between systems, Fidelity deployed Kafka Connect with the IBM MQ connector directly on z/OS, running on zIIP processors for better performance and lower cost.
This setup allows key events—like market openings or order executions—to flow seamlessly between IBM MQ and Kafka, supporting both mainframe and cloud-native applications. By colocating the connector with the queue manager, Fidelity avoided network latency and expensive Chinet hops.
With full observability via Prometheus and Grafana, plus active-active Kafka clusters with replication, Fidelity has built a scalable, efficient, and resilient architecture for modern event streaming—backed by a turnkey deployment guide for others to follow.
Royal Bank of Canada (RBC) – Offloading Mainframe Data to Cloud Platforms for Analytics
As Canada’s largest bank, RBC needed a way to unlock legacy data from its mainframe infrastructure while staying compliant with strict banking regulations. Using Confluent Platform and Apache Kafka, RBC built a real-time, event-driven architecture that powers new microservices, improves agility, and significantly reduces operational costs.
“We needed a way to rescue data off of these accumulated assets, including the mainframe, in a cloud-native, microservice-based fashion.”
Mike Krolnik, Head of Engineering, Enterprise Cloud, RBC
With Kafka, RBC lowered mainframe read volumes, cutting fixed infrastructure (OPEX) costs, while preserving existing write logic and compliance requirements. Over 50 applications now run on the new architecture, enabling faster data discovery, reusable data pipelines, and near real-time anomaly detection.
The bank’s internal event streaming platform supports multiple lines of business from digital marketing to fraud detection and provides centralized, secure access to real-time data across cloud and on-prem systems. Developers build and scale new services faster, leveraging schema evolution, stream monitoring via Control Center, and fully decoupled APIs.
“Streaming data as events enables completely new ways for solving problems at scale.”
Mike Krolnik, Head of Engineering, Enterprise Cloud, RBC
Confluent and Kafka have become core to RBC’s strategy—not just for integration, but as a foundation for building the next generation of data-driven, cloud-native applications.
Sun Life – Modernizing Life Insurance with an Enterprise Event Hub for Real-Time Customer Portals
To meet rising demands for speed, innovation, and customer experience, Sun Life is transforming its legacy architecture. Historically reliant on batch-based mainframe integration, the company faced escalating project costs, slow delivery cycles, and fragmented client experiences across channels.
Working with Precisely and Confluent, Sun Life built an Enterprise Event Hub to connect systems in real time and enable a new API-driven architecture. This shift from batch to event streaming improves data freshness, streamlines integration, and lays the groundwork for future digital services.
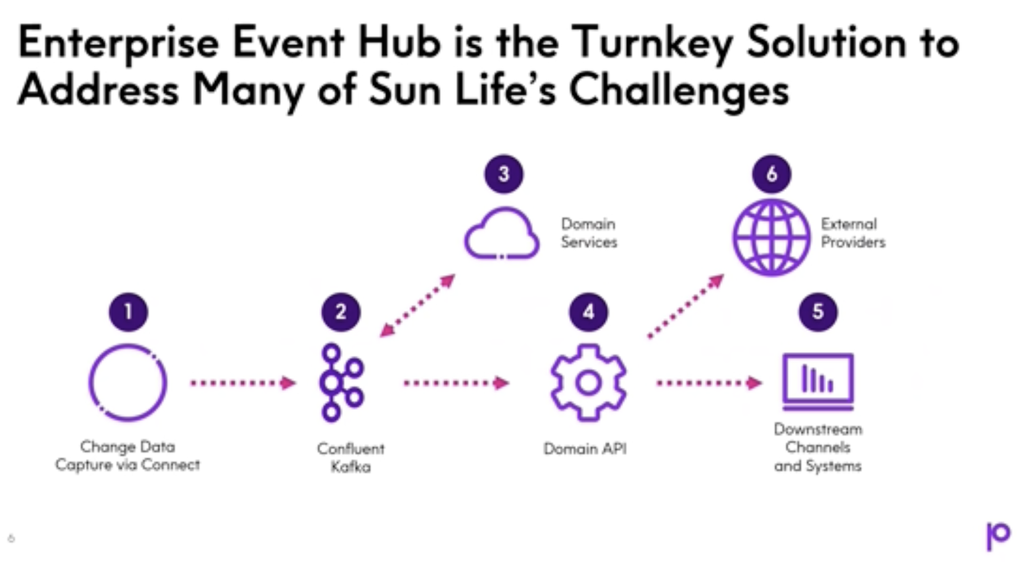
“The Group Benefits Provider eClaims project is creating a portal that will save $1.8 million annually and build a foundation for future capabilities. Enterprise Event Hub is a critical element to this portal.”
By unlocking real-time data and simplifying integration, Sun Life is reducing operational costs and accelerating innovation across the business.
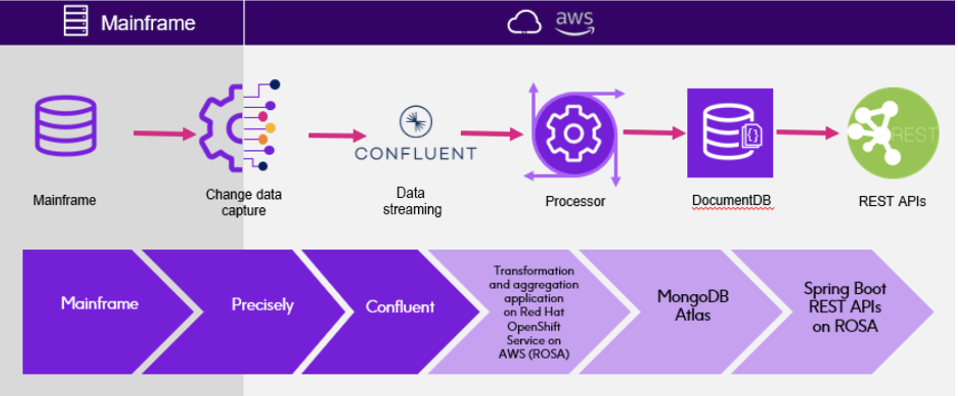
Citizens Bank – Connecting Mainframe to Apache Kafka to Power a Digital-First Strategy
With over $215 billion in assets, Citizens Bank modernized its legacy infrastructure by combining Precisely’s CDC technology with Confluent’s data streaming platform to meet the demands of digital-first customers.
The bank moved from traditional batch processing to real-time data streaming with Precisely and Confluent This enabled up-to-the-second insights across financial transactions, customer interactions, and business intelligence systems. A strict requirement was met: 99.99% of mainframe changes are now reflected in cloud applications within four seconds.
Business results include:
- 20% increase in customer engagement
- 15% drop in false positives for fraud detection, saving roughly $1.2 million per year
- 30% reduction in IT costs
- 50% faster data processing
- 40% improvement in loan processing times
Citizens Bank’s approach shows how integrating mainframe systems with Kafka unlocks speed, accuracy, and agility while delivering measurable business value.
Datev – From Mainframe to Cloud-Native Microservices for Accounting Services
As a “forerunner of digitalization” for tax advisory, DATEV supports tax consultants, auditors, and legal professionals across international markets. To modernize its architecture, DATEV integrated mainframe data into a new event-driven microservices platform.
The results:
- Mainframe data is now available to cloud-native applications in real time
- Processing and networking costs on the mainframe were significantly reduced
- A fully automated deployment pipeline enables faster and more efficient development
This approach bridges legacy reliability with modern agility, unlocking innovation without disrupting core systems.
Alight – Unified Data Platform to Reduce Mainframe Costs and Accelerate Innovation
Alight Solutions modernized its COBOL-based z/OS systems by building a Unified Data Platform (UDP) using Confluent Platform and Apache Kafka. The platform offloads data from the mainframe into a real-time forward cache, reducing processing load and enabling faster, scalable access for consumer-facing applications.
“The UDP platform enabled us to lower costs by offloading work to the forward cache and reducing demand on our mainframe systems.”
Chris Roberts, VP Enterprise Architecture, Alight
With near real-time streaming pipelines, Alight now delivers new digital solutions faster, integrates more easily with platforms like Salesforce, and supports innovation with consistent, secure access to up-to-date customer data—all while significantly cutting mainframe-related costs.
Krungsri (Bank of Ayudhya) – Fraud Detection in Under 60 Seconds
I had the pleasure to do a panel conversation with Tul Roteseree, Executive Vice President and Head of the Data and Analytics Division from Krungsri at Confluent’s Data in Motion Tour 2024 in Bangkok, Thailand.
Krungsri, Thailand’s fifth-largest bank by assets, has modernized its architecture to fight fraud with real-time data streaming. The shift from batch processing and point-to-point integrations to an event-driven architecture using Apache Kafka and Confluent allows the bank to detect and respond to suspicious transactions in under 60 seconds—before funds can be transferred to mule accounts.
Key use cases include mainframe offloading, customer account movement notifications, and fraud detection triggered by real-time events. With stream processing and cloud-based AI models, Krungsri built a hybrid environment connecting on-prem core banking systems with cloud services and mobile apps.
“We went with someone we can trust. Confluent gave us the stability, speed, and cost savings we needed—projects that once took 4–6 months now go live in 6–8 weeks.”
By leveraging IBM CDC for data capture and Confluent for scalable distribution, Krungsri offloads workloads from the mainframe, reduces cost, and improves time to insight. This architecture supports regulatory compliance as a tier-one application under the Bank of Thailand.
BNL (BNP Paribas Italy) – Mainframe Offloading via Data Streaming as a Service
Banca Nazionale del Lavoro (BNL), part of the BNP Paribas Group, is modernizing its data infrastructure by offloading workloads from DB2 on the mainframe. The bank shared this approach at the Data in Motion Tour 2023 in Milan.
Using Qlik Replicate for Change Data Capture (CDC), BNL streams DB2 changes into Apache Kafka. With Confluent, the data is distributed to multiple consumers in real time.

This reduces mainframe load and costs. It also improves access to fresh data for analytics, compliance, and operations while keeping core systems in place.
Lloyds Banking Group – From Mainframe to Hybrid Cloud with Real-Time Data Products
Lloyds Banking Group, a leading UK financial services provider, has been transforming its data architecture since 2019. With a strong focus on retail and commercial banking, the organization began its journey to the public cloud by adopting Google Cloud Platform (GCP) and Azure to modernize its analytics and application landscape.
While many core systems, including mainframe applications, remain on-premises, real-time data streaming has become critical. The bank needed a solution to synchronize data across on-prem and cloud environments, support streaming applications in the cloud, and meet regulatory requirements such as “stressed exit” compliance for cloud portability.
To support this hybrid model, Lloyds is building an internal Data Mesh framework, grounded in four key principles:
- Domain ownership
- Data as a product
- Self-serve infrastructure
- Federated data governance
At the heart of this transformation is the Enterprise Streaming Hub—a new internal framework with reusable patterns and templates for creating Streaming Data Products. These products serve both real-time and batch needs through a Kappa Architecture, where event streams are the primary source of truth. Anton Hirschowitz and Julian Gevers from Lloyds presented the architecture at Kafka Summit 2024 in London:
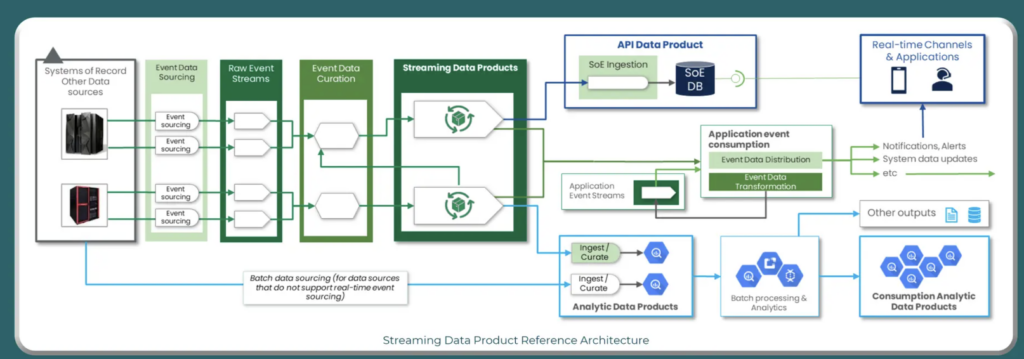
By integrating Apache Kafka and Confluent, Lloyds delivers near real-time data across its systems, reduces latency for cloud analytics, and enables teams to build and scale modern data services; all while keeping mission-critical workloads running reliably on the mainframe.
Options Clearing Corporation (OCC) – Modernizing Trade and Risk Data Flows From COBOL Systems
The Options Clearing Corporation (OCC), the world’s largest equity derivatives clearing organization, processes over 10 billion contracts annually for 16 U.S. exchanges. Historically reliant on mainframe-based batch processing, OCC faced increasing pressure to reduce risk and improve responsiveness.
By adopting Apache Kafka and Apache Flink, OCC shifted from overnight batch jobs to real-time stream processing. Their margin calculation process—once taking over 8 hours—now runs in just 5 minutes, multiple times a day. Kafka and Flink power analytics on high-volume data streams, including millions of transactions per hour and price updates for over 2 million financial instruments per second.
OCC also implemented windowing strategies in Flink to ensure consistency across client portfolios, even as data volumes vary. To meet SEC disaster recovery requirements, they deployed isolated Kafka and Flink infrastructure across AWS and on-premises, ensuring high availability and compliance.
This transformation showcases how event streaming can modernize risk management, drive massive performance gains, and meet the highest regulatory standards.
BEC Financial Technology – Core Banking Modernization for 20+ Banks in Denmark
BEC Financial Technologies, a core banking platform provider for over 20 banks in Denmark, is replacing decades of batch-based legacy architecture with modern, event-driven systems. In collaboration with Scoutz, its innovation subsidiary, BEC is transforming a 40-year-old mainframe by integrating Apache Kafka to synchronize data in real time with cloud-native platforms such as Salesforce CRM.
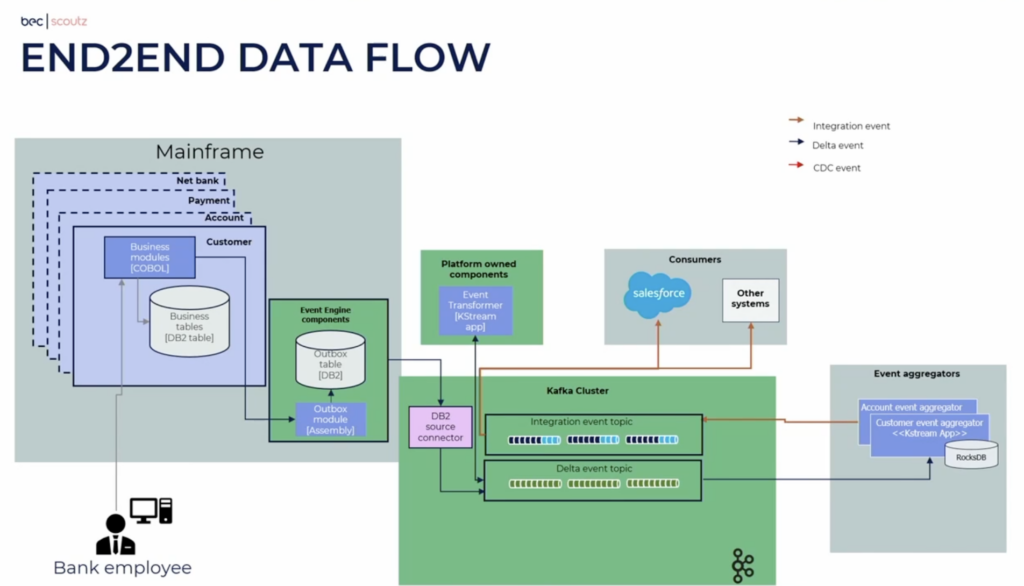
Instead of relying on end-of-day batch jobs, the new architecture supports continuous event flows between DB2 on the mainframe and Kafka topics, enabling real-time customer updates and unlocking new business capabilities. To ensure reliability and consistency, BEC implemented key patterns like event-carried state transfer, compacted topics, and change data capture (CDC). They also built robust reconciliation mechanisms to validate alignment between DB2 and Kafka.
A DevOps-centric approach was critical. The team focused on efficient topic management, schema evolution, and delivery pipelines. Lessons learned include avoiding centralized transformation logic and enforcing schema governance from day one. The shift toward a Kappa architecture ensures the platform can handle both streaming events and large-scale batch jobs—depending on operational needs.
Apache Kafka as Event Broker and Integration Platform for Mainframe Modernization
Mainframes are here to stay, but they must evolve.
With Apache Kafka as event broker and integration platform, enterprises have a flexible foundation to extend, enhance, or gradually replace mainframe systems. Offloading reduces costs. Integration accelerates innovation. Replacement, when appropriate, modernizes the core.
A cloud-native data streaming platform powered by Apache Kafka and Flink brings the best of both worlds: the reliability of the mainframe and the agility of real-time cloud architectures.
If you’re connecting Kafka to your mainframe:
Are you offloading, integrating, or replacing?
Let’s learn from each other.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including several success stories around IT modernization.